












PythonでGoogle Speech to TextとGoogle Storageを使った音声テキスト化
投稿者:大島
こんにちは、NI+C大島です。
今回はPython3を使ってGCPで提供されているSTTで音声ファイルのテキスト化を行いたいと思います。
# 概要
GCPのSTTはIBM Watsonで提供されているSTTと違い、音声ファイルの再生時間の長さによって同期処理/非同期処理が分かれています。(利用するAPIが異なる)
基本的に1分以上の音声ファイルは非同期処理によるテキスト化を行います(1分以下でも非同期処理はテキスト化可能ですが同期処理で1分以上の音声ファイルはテキスト化できません)
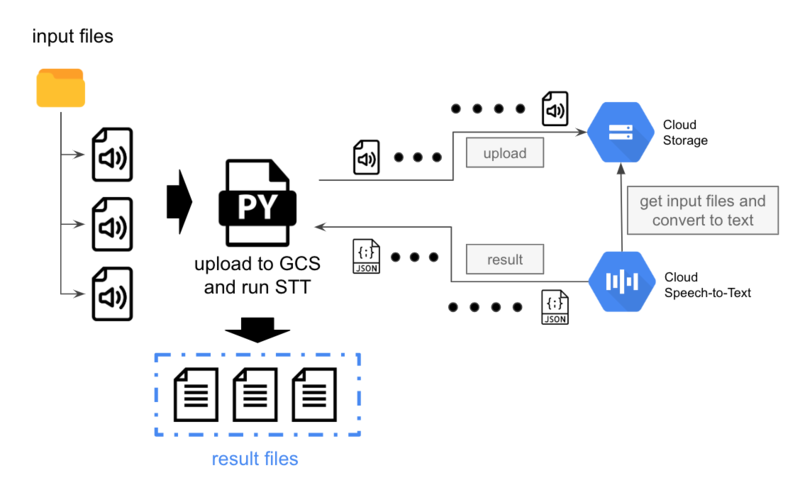
# 概要図
今回の処理概要を絵にすると以下のような形です。
Googleが提供しているSTT/GCSのライブラリーを活用して、テキスト化を行いたい音声ファイルをディレクトリに置いてもらい、プログラム実行時にそのディレクトリを指定すると
再帰的に音声ファイルを抽出して順次アップロード&テキスト化するようなプログラムを作成しました。
# 前準備
– GCS上でバケットを作成
適当にバケットを作成してください。

– STTを有効化
STTのAPIを有効化してください。

– サービスアカウントとIAMを設定
まずはSTTの管理画面にアクセスして、メニューから「認証情報」をクリック。「+認証情報を作成」ボタンをクリックして、「サービスアカウント」を選択する。サービスアカウント作成画面のフィールドは適当に入力して、作成をお願い致します。作成が終わったら、クレデンシャルファイル(json)の取得も忘れずに

次に、GCSの管理画面にアクセスし、先程作成したバケットのメニューを選択し、「バケットの権限の編集」をクリック

メンバーを追加ボタンクリックし、先程作成したサービスアカウントを指定。
権限は今回は管理者を選択します(実PJの場合はセキュリティーの観点から細く権限を付与してください)

以上で前準備は終わりです。
サービスアカウントに紐づくサービスアカウントキー(jsonファイル)の取得とバケット名は忘れずに、次項のプログラムで利用します。
# コード
今回のプログラムになります。動作環境はMac、Pythonは3になります。
importしているpipライブラリーのインストールを忘れずにお願い致します。
# 実行してみる
検証用のwavファイルを日立さんよりお借りし、プログラムを実行してみます。(日立さんありがとうございます。)
プログラムが置かれているディレクトリーに音声ファイルを格納したディレクトリを作成してください。プログラムを実行すると、「ディレクトリのパスを入力してください」とプロンプトに表示されるので、音声ファイルを配置したディレクトリパスを指定すると再帰的にファイルを検索して順次テキスト化します。
$ python gcp-stt.py
ディレクトリのパスを入力してください: sample
start get file list: sample
## START: sample/01.male.wav
start check input file: sample/01.male.wav
#######
start check .wav file info: sample/01.male.wav
#######
start upload to gcs
done upload to gcs: sample/01.male.wav
#######
exec stt: sample/01.male.wav
Transcript: 明日の関東地方の天気は晴れ所によりにわか雨でしょう
done stt: sample/01.male.wav
#######
## END: sample/01.male.wav
## START: sample/05.femal.normal.wav
start check input file: sample/05.femal.normal.wav
#######
start check .wav file info: sample/05.femal.normal.wav
#######
start upload to gcs
done upload to gcs: sample/05.femal.normal.wav
#######
exec stt: sample/05.femal.normal.wav
Transcript: 家の音声合成は自然性が高く声に表情をつけることも可能です
done stt: sample/05.femal.normal.wav
#######
## END: sample/05.femal.normal.wav
start date: 2020-02-07 12:06:34.867716
end date: 2020-02-07 12:06:47.741041
spend time: 12.873322010040283[sec]
テキスト化された文字は画面以外にも以下のようにフォルダーへ出力されます。(2つ目の音声ファイルは誤変換してますね。。)

# まとめ
音声ファイルの時間が長い場合非同期処理を実施する必要があるため
システム化する際はCloud Functionsを活用して、音声ファイル→アップロード→GCS←アプロードを検知←Cloud Functions→テキスト化→Cloud SQL に格納といった処理を実施したほうが良いと思います。
検証目的などで本記事が参考になれば幸いです。