


Matillion ETL for BigQueryで構築からデータ連携まで簡単に実装!
投稿者:佐々木

様々な場所に散在しているデータを統合して分析に活用したいという要望は、非常に多いです。
今回はそのような要望に対して、Matillionをご紹介し、簡単なデータ連携の手順についてご説明したいと思います。
Matillionとは
Matillionはクラウドデータウェアハウス向けに構築されたデータインテグレーションツールで、Amazon Redshift、Google BigQuery(以下BQ)、Snowflake、Azure Synapseなどのクラウドデータベースプラットフォーム用に特別に構築されています。
様々なオンプレミスやSaaSのデータをクラウド上へロードするフローを簡単に作成することが可能で、分析等に向けて、散在しているデータを統合し一元管理したいという方におすすめのツールとなっています。
公式ドキュメントはこちら
構築
今回はGoogle Cloud Platform(以下GCP)のCloud Storage(以下GCS)に格納されているCSVファイルをBQにロードすることをゴールに構築していきます。
必要なタスクは以下の通りです。
1. 準備
2. セットアップ
3. ジョブを作成する
4. ジョブを実行し、結果を確認する
1. 準備
1.1 GCPプロジェクトを作成する
・プロジェクトの作成手順は公式ドキュメントをご覧ください
1.2 GCSにバケットを作成し、CSVファイルを格納する
・GCPコンソールでStorage>バケットを作成からバケットを作成する
1.3 BQにテーブルを作成する
・BigQueryを押下し、リソース中の1.2.で作成したプロジェクト名を押下
・データセットを作成を押下し、データセットIDを入力してデータセットを作成を押下
・作成したデータセットを押下し、テーブルを作成を押下でテーブルを作成する
2. セットアップ
2.1. Matillionインスタンスを作成する
・GCPコンソールでMarketplaceを押下し、検索バーにMatillionと入力
・Matillion ETL for BigQuery – Mediumを選択し、運用開始を押下
※同時接続ユーザー数、環境数に応じてLarge, Extra Largeを選択してください

・マシンタイプなどを選択し、インスタンスを作成する
2.2. Matillionにアクセスし、ログインする
・外部IPをコピーして、Matillionにアクセスする
・以下の情報でMatillionにログイン
ログイン名:gcp-user
パスワード:指定のパスワード
※パスワードは下図のようにVMの詳細からカスタムメタデータの欄で確認することができます。

2.3. プロジェクトを作成する
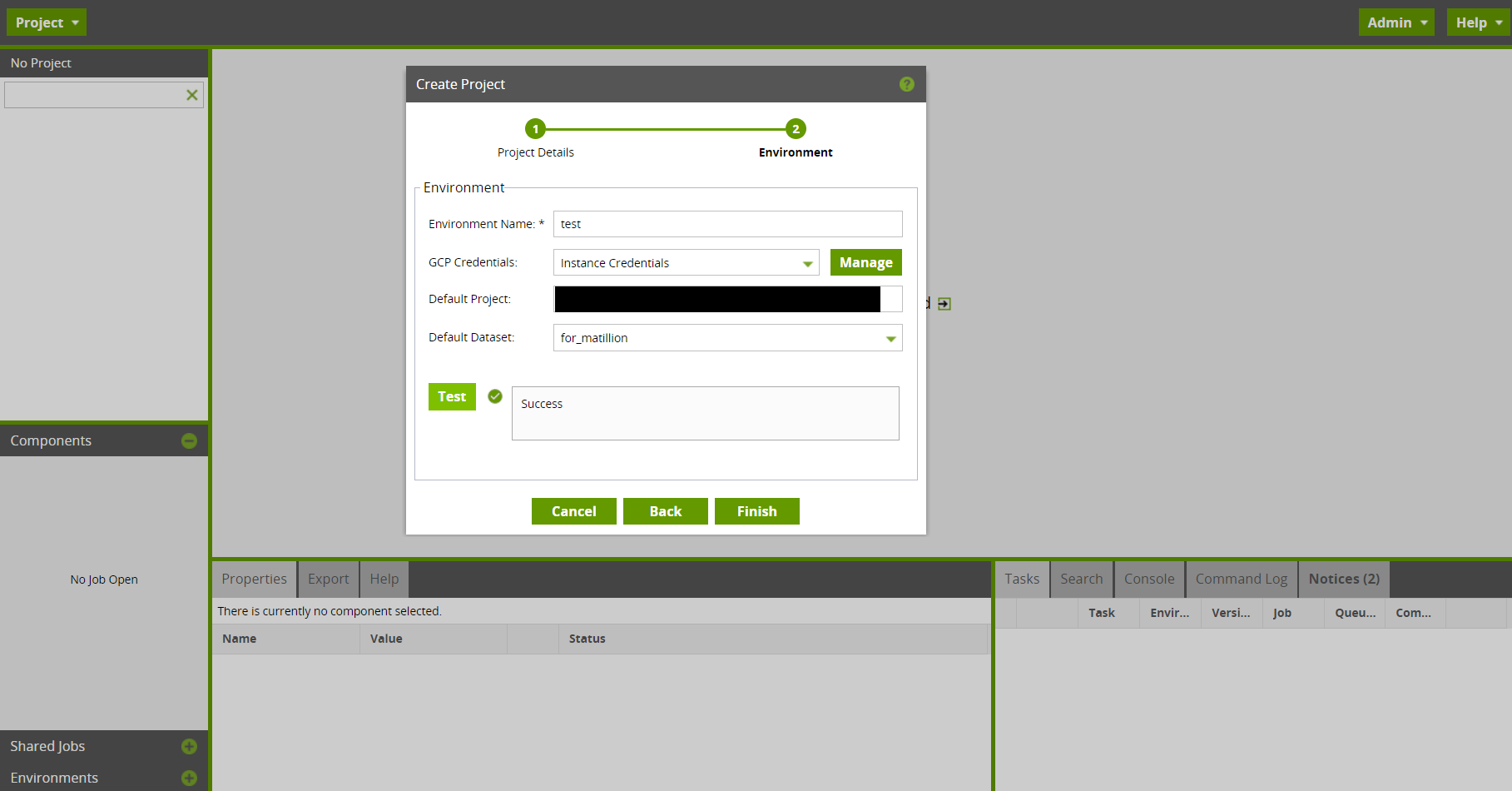
・下図のように必要事項を入力しNextを押下

・環境名とデフォルトとするGCPプロジェクトIDとBQのデータセット名を入力しFinishを押下
3. ジョブを作成する
3.1. ジョブを作成
・画面左のdefaultを右クリックし、Add Orchestration Jobを押下
・ジョブ名を入力してジョブを作成

3.2. コンポーネントを配置
・下図のようにコンポーネントを配置
・コンポーネントの役割は以下の通り
Start:ジョブを実行するスタート位置
Cloud Storage Load:GCSに格納されているファイルデータをBQにロードする
End Success:正常終了
End Failure:異常終了

3.3. コンポーネントの設定値を指定
・Cloud Storage Loadの設定値を以下のように指定
Target Table:<対象のテーブル名>
Load Columns:<対象のカラム>
Google Storage URL Location:<GCSに格納したファイルURL>
File Format:CSV
Write Preference:Append to table
Header Rows to Skip:1
※上記以外の項目はデフォルトで問題ありません。

4. ジョブを実行し、結果を確認する
4.1. ジョブを実行する
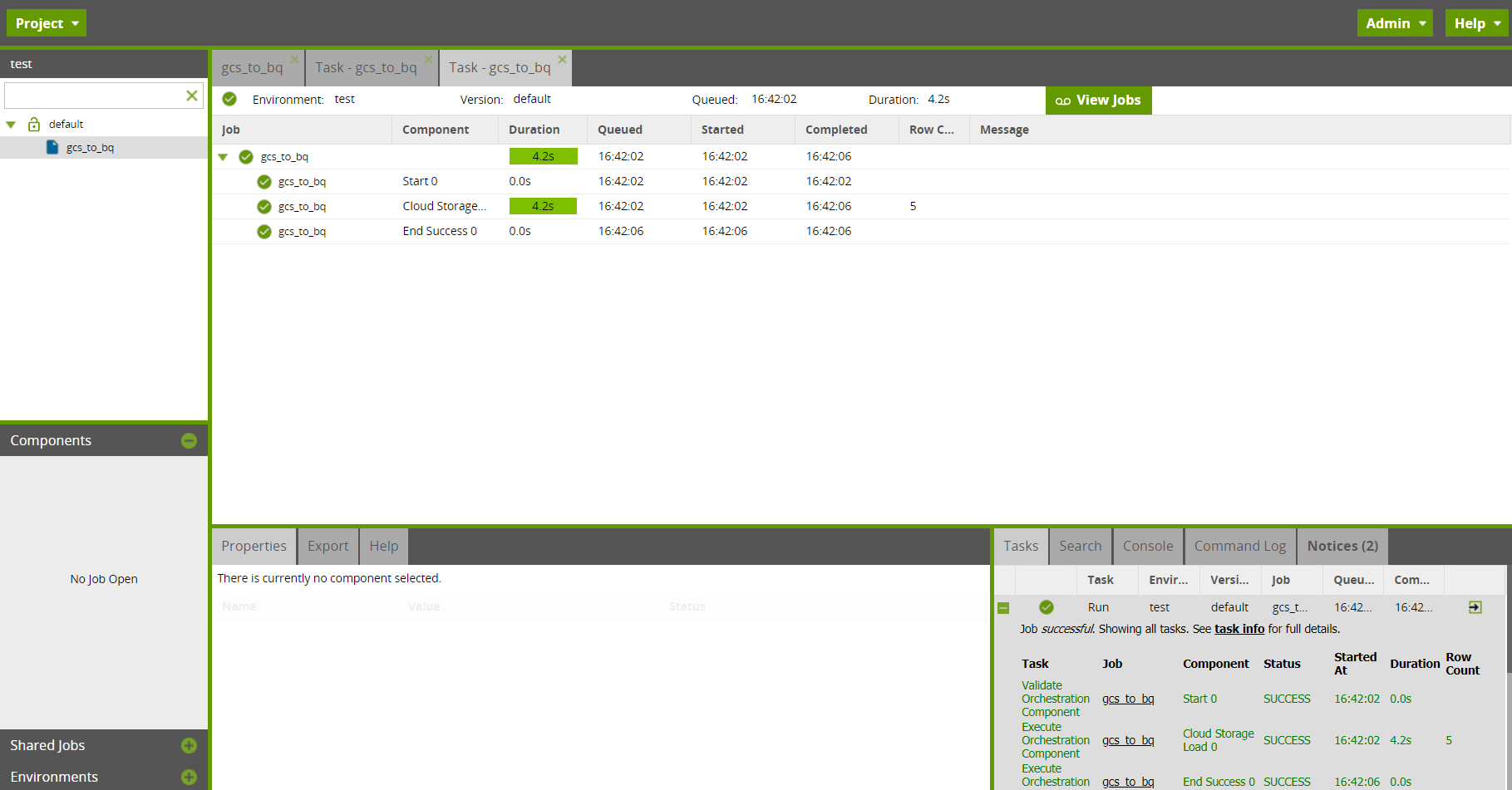
・startコンポーネントを右クリックし、Run From Componentを押下
・画面右下Tasksで正常終了したことを確認
4.2. BQを確認する
・GCPコンソールのBQの画面でCSVファイルデータをインサートしたテーブルを確認

まとめ
Matillionを利用してCSVファイルのデータをBigQueryにロードするフローを簡単に作成することができました。時間主導によるトリガー設定などもあるので、継続的なデータ連携を自動化することも可能です。
また、今回ご紹介しませんでしたが、他にもAmazon S3に格納されているファイルやMySQLとのデータ連携も行ってみましたが、簡単に実装することができ、使っていて非常に便利に感じることができました。
しかし、ドキュメントが英語版しか存在せず、体験記事等がほぼゼロだったこともあり、最初は機能を理解するのに少々苦労しました。
機能としては他にも様々あるので、時間がある時に試してみたいと思います。