


「IBM Watson日本語版ハッカソン」参加レポート
投稿者:ソリューション担当

昨年12月に開催された「IBM Watson(ワトソン)日本語版ハッカソン」の参加レポートをお届けします。
今回のハッカソンは2016年に正式リリースを予定しているIBM Watson日本語版のベータ版APIとBluemixを使って、「人々の生活を豊かにする」というテーマで、そのアイディアを競い合うものでした。
IBM Watson日本語版ハッカソンについて詳しくは公式ホームページをご覧ください
参加は抽選制であり、約30社が応募しました。NI+Cからも有志としてチームで応募し、抽選の結果、NI+Cを含む11社が残り、それぞれがサービス開発に熱中しました。
Watsonで「Know Who」システムを考えてみる
私たちのチームはWatsonを使い「Know Who」システムを作りました。「Know Who」とは知りたい情報を誰が知っているか、どこに得意としている人がいるかというものを検索できる仕組みのことです。仕事や生活の悩み等で、その道のスペシャリストの意見や知識が欲しい人は、「Know Who」システムを使い必要な知識などを得ることができます。このシステムをWatsonと融合させる上で考慮した点は、「データフローの実装」と「自然な会話」となるように実装した点です。以下に詳細を記載します。
「データフローの実装」(Node-REDの活用)
「Know Who」という既知のシステムにWatsonという新しい技術を組み込むのは簡単でしたが、どういう「データフロー」にすればいいのかは悩みどころでした。特に機械学習も視野に入れてデータフローを設計しなければいけなかったのでデータフローの設計に時間がかかりました。開発環境ですが、ハッカソンという限られた時間の中で駆動品を動かすという状態の中だったこともあり、「Node-RED」を使用しました。「Node-RED」とは開発環境のひとつで、機能がひとつのノードとして分かれており、視覚的にデータフローを設計できるというメリットがあります。
[図1.Node-REDでのフロー]
「自然な会話」(日本語での形態素解析について)
ユーザが入力した文章を全てWatsonに問い合わせ、それを表示させるだけでは会話は成り立ちません。例えば、Watsonが知らないことについて質問があった場合、どういうやりとりが自然なのかについても考える必要があります。他にも例が挙げられますが、正直なところ自然言語処理、特に日本語の意味判定は難しいです。コンピュータ上で自然言語処理をする場合、通常は形態素解析をします。形態素解析とは、私たちが普段使っている自然言語で書かれた文章を、意味を持つ最小単位に分割することです。例えば、英語は単語ごとに区切って書くため形態素解析は容易です。一方、日本語は単語が続いた文章となるため、どこが単語の区切りとなるかがわかり辛い言語のため、形態素ごとに分割するのが難しいのです。ハッカソンで使用したWatsonも形態素解析を用いています。従って、どこが単語の区切りとなるかを教えてあげる必要があります。今回のハッカソンでは、実装までは間に合いませんでしたが、Watsonに単語の区切りを教える例は以下となります。

[図2.Watsonに学習させる日本語区切りフォーマット]
Watson日本語版APIの”NLC”と”R&R”とは
デモを2日間で仕上げないといけないという緊張感のなかで、参加者はWatson日本語版APIの”NLC”(Natural Language Classifier)と”R&R”(Retrieve and Rank)の動作について深く学習することができました。実はハッカソン開催まで、漠然とでしかWatsonの使用イメージがつかめていませんでした。ハッカソン主催者のIBMとソフトバンクも外部からのアイデアを求めている状況でした。以下に”NLC”と”R&R”の簡単な動作を解説します。
“NLC”は機械学習を用いた自然言語のクラス分類を行います。文章を入力すると、その文章のカテゴリ(class)が返ってきます。例えば、「たこ焼き」と入力し”NLC”に問い合わせると、「食べ物という分類の可能性が高いよ」と帰ってきます。”NLC”は質問の分類を返すのに対して”R&R”は具体的な答えを返すことができます。例えば、「東京で一番高い建物は?」という質問であれば「スカイツリーです。」というやりとりをさせることが可能になります。
“NLC”と”R&R”は事前に組み込まれたデータやプログラムから応答するのではなく、これまでに習得した知識に基づいて、より質問者の意図に近い解を返すことができる可能性に満ちたシステムです。両者は単体よりも組み合わせで機能させた方が回答パターンやバリエーションに幅をもたせることができると考えます。

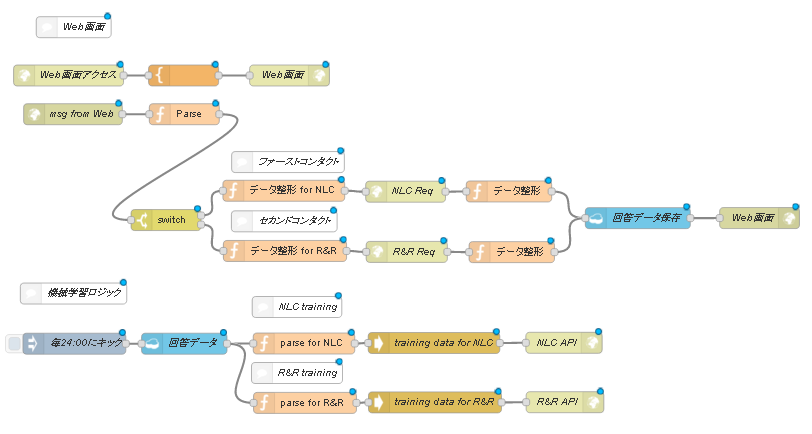
[図3.Know Whoグランドデザイン]
ハッカソンを終えて
ハッカソンが無事終了し、参加チームにて振り返りを行ったところ私たちのチームで開発した「Know Who」システムは拡張性が乏しかったという意見がありました。他チームでは既存サービスに補完する形でWatsonを活用した例が多く、既存サービスを利用しているユーザーの知らないところでWatsonを有効活用できる点が評価されていました。今回作成した「Know Who」システムはパブリックデータをWatsonに読み込ませていましたが、ゆくゆくは社内のスキルデータベースと連携して活用できるように改善していきたいです。今回は残念ながら入賞に至りませんでしたが、今後も引き続きWatsonやBluemixを活用したサービスについて積極的に取り組んでいきたいと思います。
【執筆者紹介】山内修平
日本情報通信入社後、日々会社業務を遂行する傍ら、自身の知見を広げようと積極的にハッカソン等に参加し、新しい技術の習得や様々なバックグラウンドをもつ方々とのコミュニケーションを図っている。そこで得られた知見をもとに、社内ハッカソン・勉強会を企画・実行するなど、精力的に情報収集や発信を行っている。