


話題のブロックチェーンを構築してみた-インフラ編
投稿者:ソリューション担当

こんにちは。昨今のITキーワードとしてビットコインにはじまり、ブロックチェーンという単語を目にする機会が増えました。ブロックチェーンの技術はさまざまな種類が開発されており、LinuxOSの普及を促進している団体のLinux Foundationのプロジェクトに登録されているものもあります。このように日々変化していくIT技術でありますが、弊社では次世代技術への取り組みとしてブロックチェーン技術を利用し、地域振興券の発行から利用までの一連の流れを管理する「金融資産(地域振興券)管理システム」をモチーフとしたプロトタイプ環境を構築しました。今回のブログはこのプロトタイプ環境の作成を通じて得たノウハウの一部を”インフラ観点”と”アプリ観点”の2回に分けてご紹介します。
ブロックチェーン概要
まずは、簡単にブロックチェーンの概要をお伝えします。
そもそもブロックチェーンとは、”改ざん防止された分散型台帳”という位置づけだと考えています。”改ざん防止”と”分散型台帳”の2つのキーワードがでてきましたので、それぞれ簡単に紐解いてみます。
改ざん防止
ブロックチェーンでは追加や変更されるデータを「ブロック」という単位で扱います。データの追加や変更が発生するたびにこのブロックが追加されていきますが、単純にデータが入ったブロックを追加していくわけではありません。追加されるブロックの中には直前ブロックのハッシュ値も保持されています。追加されていくブロックは直前ブロックのハッシュ値を保持しているため、下図のような数珠繋ぎ構造になります。
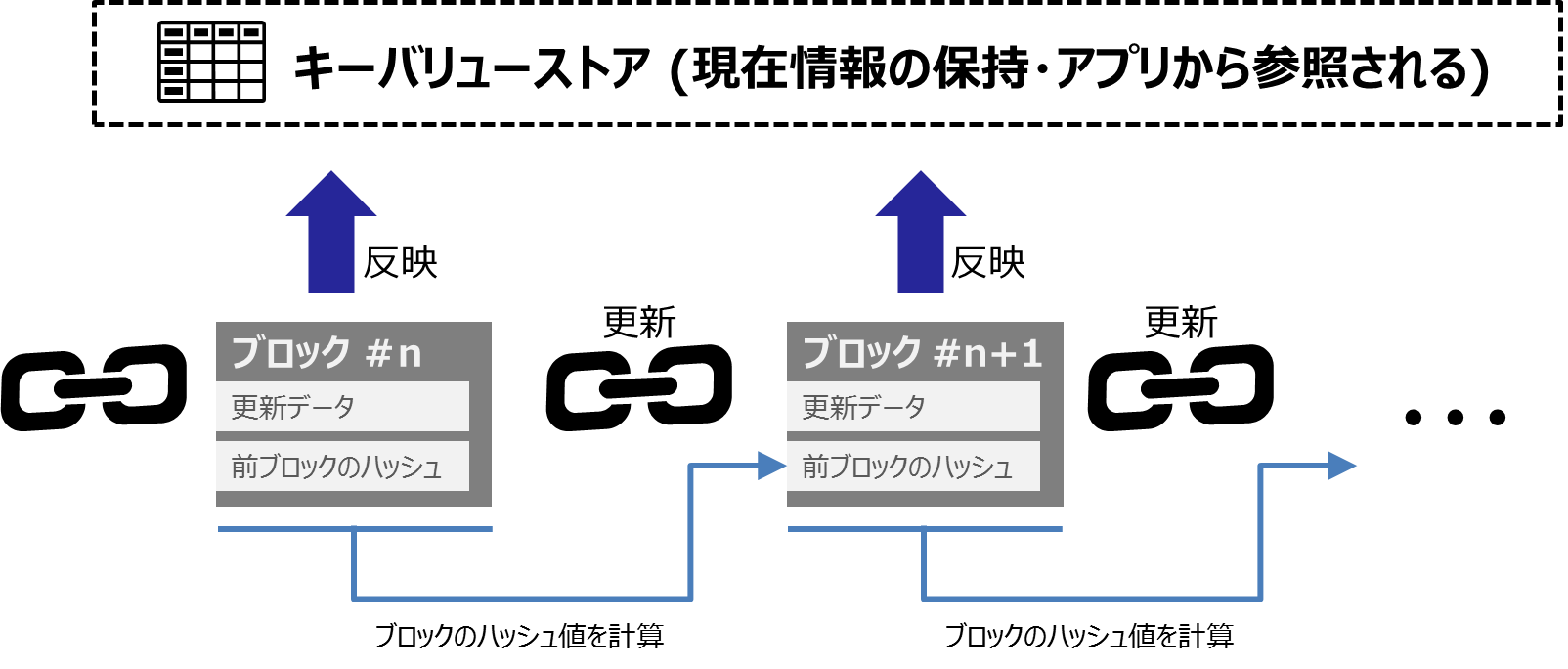
例えば、1つの中間のブロックを改ざんしたとします。改ざんしようとしたブロックの中に保持するハッシュ値は直前のブロックを参照すれば求めることができます。しかし、改ざんしたブロックの次のブロックには、改ざん前のブロックのハッシュ値が保持されています。ブロック内のデータを改ざんすることで前後ブロックのハッシュ値の辻褄が合わなくなります。(下図参照)

分散型台帳
ブロックチェーンでは、一つのサーバにデータ(ブロック)を集約するのではなく、複数台のPeerサーバで保管します。ブロックは日々追加され、現状のデータも都度更新されていきます。更新されたデータは各Peerサーバのキーバリューストア(KVS)と呼ばれる最新の情報を保持しており、どのPeerサーバからでも最新の情報を取得することができます。そのためブロックチェーンを構成しているPeerサーバは1つのロケーションでなくとも複数のデータセンタをまたいだ実装が可能になります。データセンタを跨ぐとその分NWのレイテンシが大きくなるため後述のブロック追加検証のレスポンスは低下しますが、アプリケーションサーバは近くのPeerサーバへアクセスできるため一長一短があると言えます。
またブロックチェーンを構成するPeerサーバの台数にもよりますが、Peerサーバが数台ダウンしたとしても継続した使用が可能なため耐障害性にも優れていると言えます。
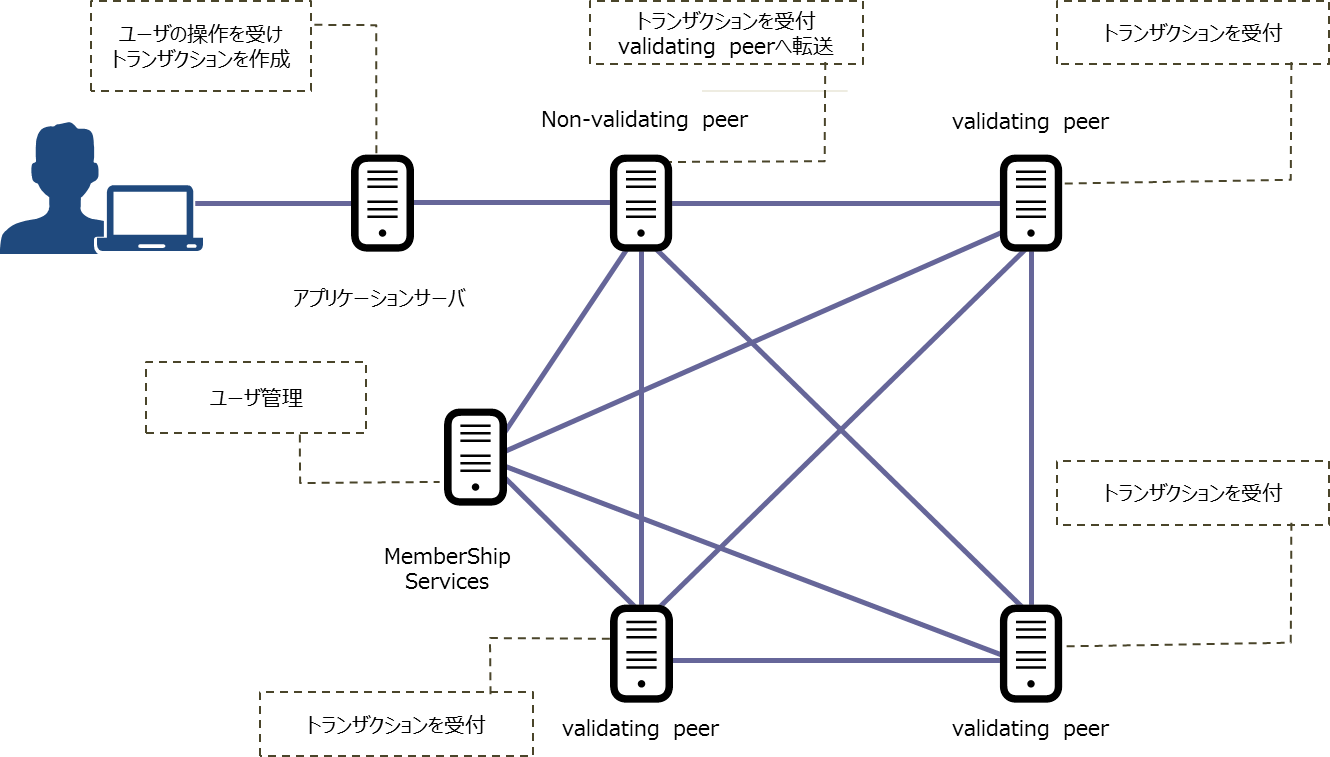
また、新たにデータ追加が発生してブロックを追加する場合は、全てのコンピューターが追加されようとしているブロックが正しいかどうかを検証し、一定数のコンピューターで正しいと判断されたブロックのみ台帳に追加される仕組みになっています。他のPeerサーバの処理と整合性が取れないトランザクションが発生した場合は処理を無効にする仕組みを備えています(ピザンチン将軍問題の回避)。
構築したプロトタイプ環境
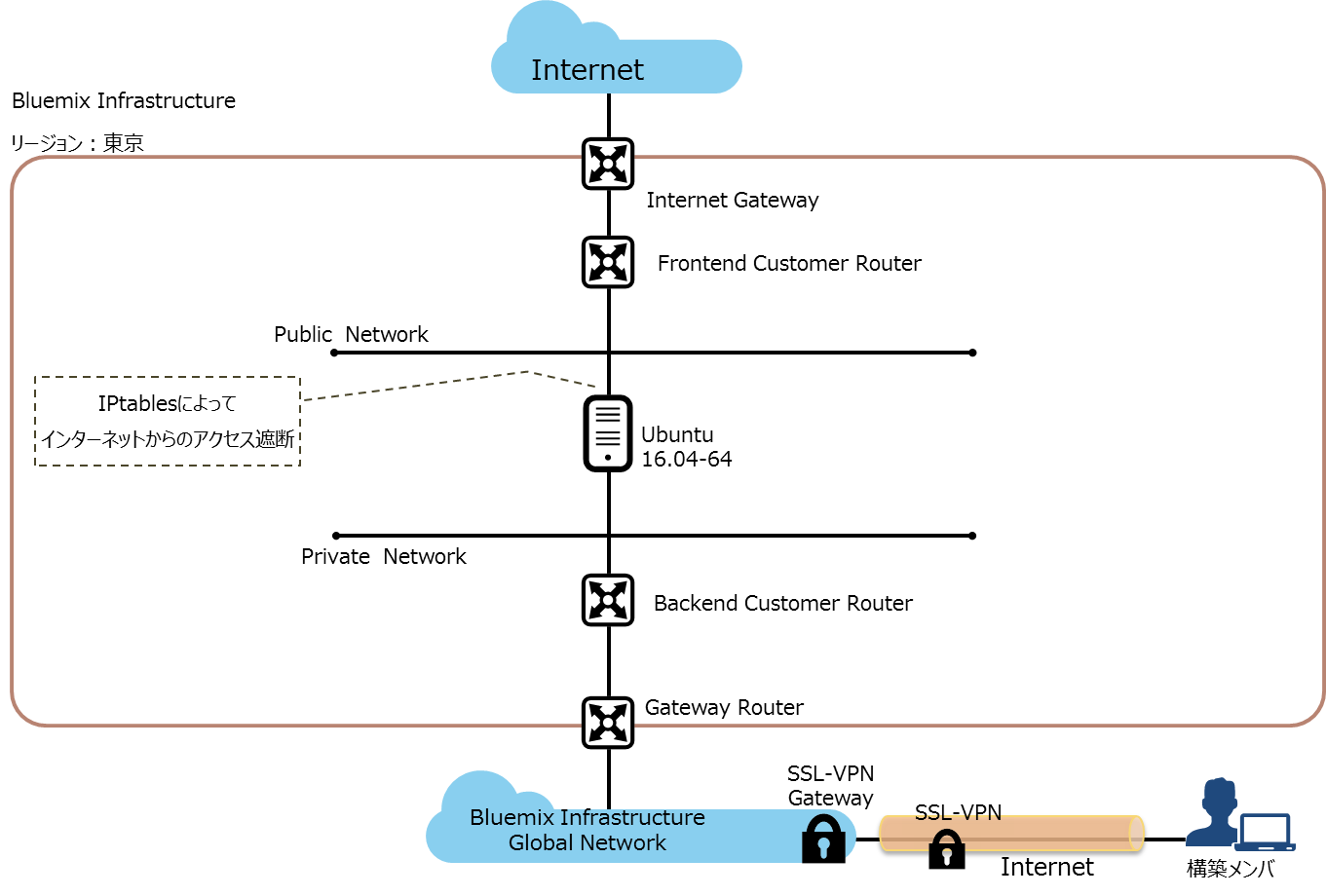
ブロックチェーンの概要は以上にして、今回弊社で構築したブロックチェーンのプロトタイプ環境を下記の図にて説明を致します。使用したブロックチェーンのプラットフォームはIBMがイニシアティブをもって開発推進しているHyperledger Fabricです。Hyperledger Fabricは本ブログの冒頭で触れました、Linux Foundationのプロジェクトの1つとして開発されています。今後の展開を踏まえ、IBMブランドIaaSのBluemix Infrastructure(旧SoftLayer)上に構築しました。仮想サーバインスタンスをUbuntu16.04 54bitで購入し、IPtablesでインターネット側からの通信を制御しています。Hyperledger FabricはGitHub上で開発が行われいるため、Ubuntuサーバはインターネットと通信できるようにしてあります。(SSL-VPN側からでもHyperledger Fabricのインストールはできなくはないと思います)。
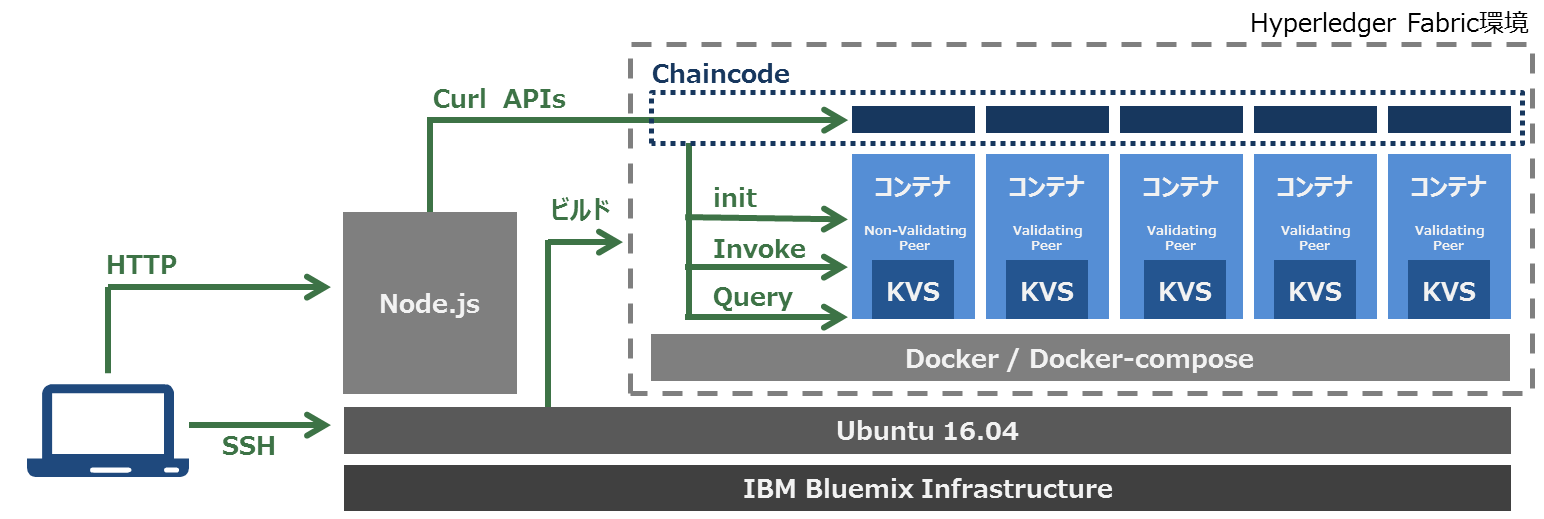
Hyperledger Fabric v0.6 はDockerコンテナ上で稼働するようになっているため、UbuntuにはDockerもインストールしています。Hyperledger FabricではChaincodeと呼ばれるプラットフォームが存在しブロックチェーンのデータ構造の定義ができるようになっています。v0.6の段階ではgo言語で書かれていましたが、v1.0からはJAVAでの記述もできる様になっています。ChaincodeはAPIのコールによってブロックの操作をします。そのためAPサーバはAPIコールできるものであれば種類は問いません。もちろんCUIのcurlでもブロックの操作が可能です。
今回の環境のWEBフロント/APサーバはNode-jsによって構築しており、プロトタイプということで同一筐体で稼働させていますが、もちろんNode-jsサーバとHyperledger Fabricサーバを分けて構築することも可能です。
以上でインフラ編は終了となります。次回、アプリケーション編ではより具体的な内容になります。プロトタイプ画面等も紹介しますので、挙動についてもイメージが湧きやすくなるのではと思います。
この記事を見てブロックチェーンに興味が湧いた方や検証を実施したいお客様がおられましたら是非弊社までお気軽にご連絡いただけますと幸いです。