



今回は予測機能を提供するPredictive Analyticsサービス(以下、PAサービス)の紹介です。予測と言えば、天気予報、渋滞予測などが身近ですが、今回は誰もが興味のあるお金(為替相場)の予測です。
予測方法
予測にはいくつかの方法がありますが、過去データを学習して未来を予測するのが一般的な方法の1つかと思います。例えば天気予報は主に気圧配置の情報をもとに天候を予測します。高気圧に覆われていると晴れる可能性が高い、といった感じですが、これは過去同じ気圧配置の時に晴れたという事実(学習結果)をもとに今日は晴れるだろうという予測を行っています。
同様の手法で今回はドル円相場を予測したいと思います。
過去データ(学習データ)を準備する
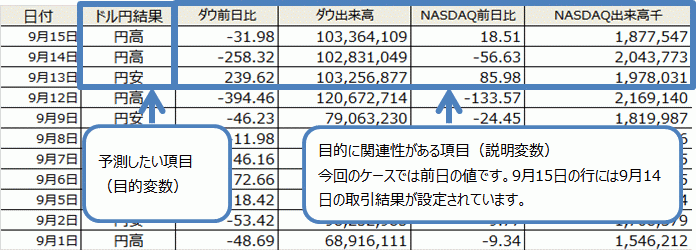
データは予測の目的となる正解データとそれと相関性のある関連データを使います。天気予報に例えると天候と気圧配置であり、天候のような正解データを目的変数、気圧配置のような関連データを説明変数と呼びます。
では為替相場の関連データとは何でしょうか。
様々な要素が思い浮かびますが、どのデータとの相関性が強いかは一概に言えませんね。このような仮説を立てる作業が分析者の腕の見せ所となりますが今回の本題ではないので単純に以下としました。
正解データ(目的変数) : 日本市場のドル円相場終値が円高、円安のどちらになるか
関連データ(説明変数) : ダウ前日比/出来高、NASDAQ前日比/出来高
NY市場の株式取引が日本の為替市場に関連している、という仮説をもとに前日のNY市場の取引結果で今日の日本市場のドル円相場の終値を予測します。
準備するデータのイメージは以下の通りです。今回は簡単に入手できた過去3ヶ月分(71日分)の取引データを利用します。
予測モデルを作成する
PAサービスを利用するにはSPSSで作成したモデルが必要となります。SPSSの紹介は割愛しますが、スコアリング設定が行われているモデルであればPAサービスに登録できると思います。
以下が今回作成した分析モデルです。SPSS利用者であれば10分程度で作成できるような単純なモデルです。
分析モデルには「自動分類ノード」を使用しています。与える値の型に合わせて自動でモデルを選定、評価してくれるので分析素人の私でもモデルを簡単に作成することができます。
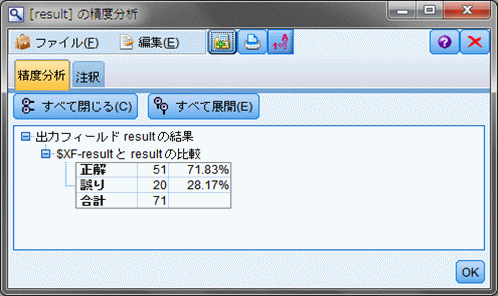
PAサービスに組み込む前にモデルの精度を確認しておきましょう。ここでいうモデルは「法則」のようなものです。例えば前日のダウ平均が30ドル以上下げた場合はドル円相場は円高になる、というような感じです。4つの説明変数を与えているので実際にはもっと複雑な法則が導き出されていますが、その法則を適用すると過去データに対して勝率71%というのが今回のモデルの精度です。
トレード成績としては悪くないので、これをPAサービスに組み込みます。
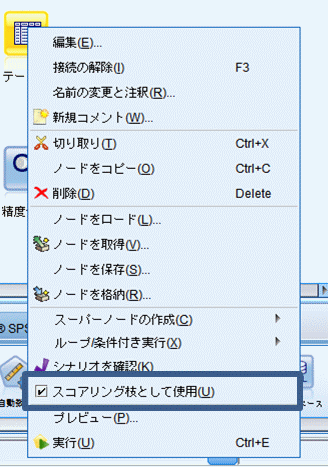
PAサービスに組み込む前にスコアリング設定は忘れずに行ってください。
予測モデルを登録する
既存または新規インスタンスにPAサービスを追加し、PAサービスのページを開きます。
破線のエリアに作成したSPSSストリームファイルをドラッグ&ドロップします。Context IDを聞かれるので任意の値を設定しDeployします。Context IDはこの予測モデルを呼び出すURLの一部になります。
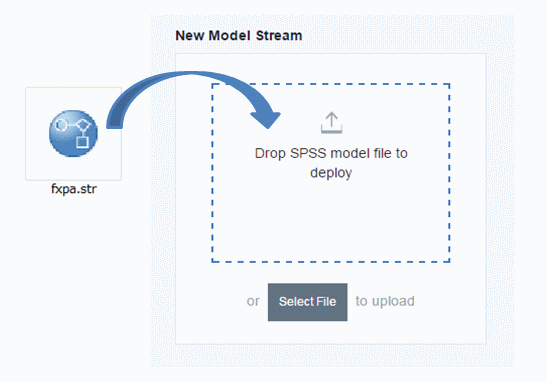
登録すると以下のページが表示されます。ページ下部に登録されたストリームファイルとConext IDを確認することができます。
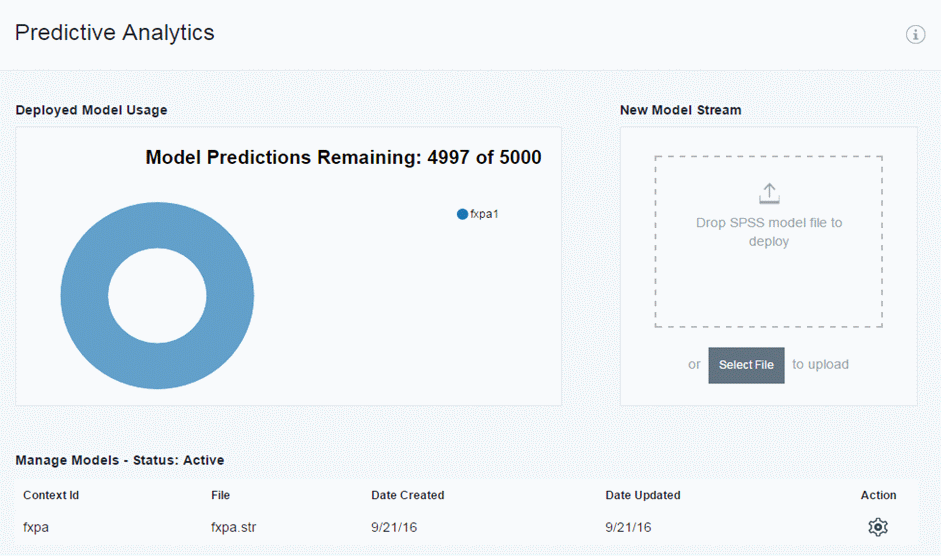
予測モデルの登録は以上で完了です。
ここまでの手順で「昨日のNY市場の取引結果をもとに本日の日本市場のドル円相場の値動きを予測するAPI」ができました。
予測する
登録したモデルを使って予測するにはREST APIを使用します。
REST APIはHeader、Bodyに必要な情報をセットして所定のURLに対してPOSTすることで実行できます。
まずはインスタンスの環境変数からURLとアクセスキーを取得し、以下のようなURLを作成します。
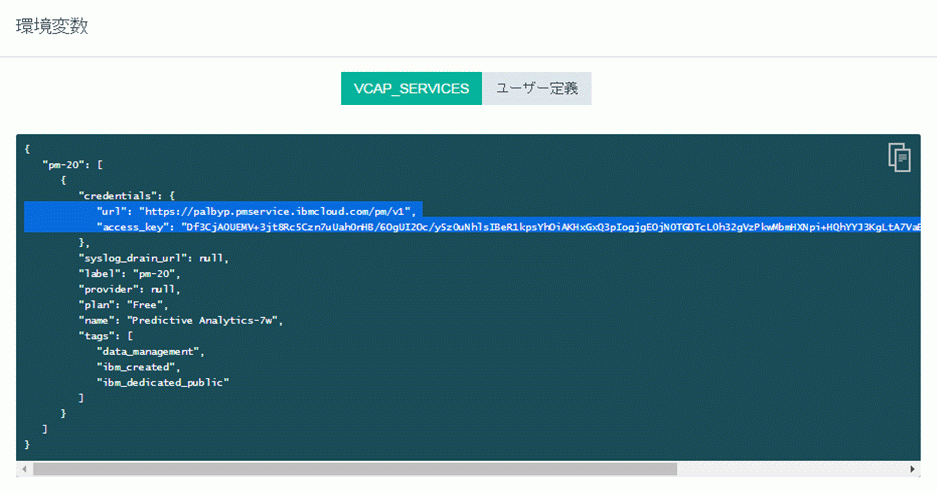
構文)
http://{url}/score/{Context ID}?accesskey={access_key}
例)
https://palbyp.pmservice.ibmcloud.com/pm/v1/score/fxpa? accesskey=Df3CjA0UEMV+3jt8Rc5Czn7uUah0nHB/6OgUI2Oc/y5z0uNhlsIBeR1kpsYhOiAKHxGxQ3pIogjgEOjN0TGDTcL0h32gVzPkwMbmHXNpi+HQhYYJ3KgLtA7VaBX7e0c6T1bpDX7rC5Zehg+ElmdqFVz06GEypkHw0ojzw5afdiY=
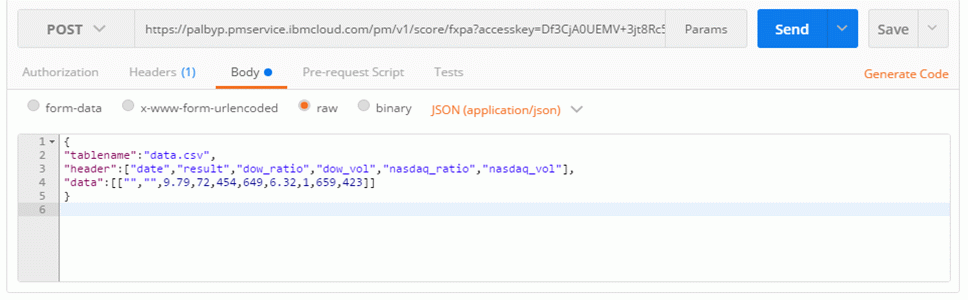
次に予測に与えるデータ(説明変数)を準備します。今日のドル円相場を予想したいので昨日のデータを取得し、以下のフォーマットに設定します。tablename にはデータの渡し先となるSPSSの入力ノード名を指定します。今回の場合は「data.csv」が入力ノード名(注:ファイル名ではありません。)なので「data.csv」と記述します。header にはカラム名、data には値をそれぞれカンマ区切りで記述します。
構文)
{
tablename:”{ストリームの入力ノード名}”,
header:[“カラム名”],
data:[[値]]
}
値を設定すると以下のようになります。
dateは使用しないのでブランクです。resultが予測したい値(目的変数)なのでこちらもブランクです。SPSSでモデルを作成する時はCSVファイルで過去データを与えていましたが、PAサービスではAPI実行時にデータをPOSTし、それを元に予測します。言い方を変えると、昨日のNY市場の結果を与え、SPSSが過去データから導き出した法則により、今日の相場が円高になるか、円安になるかを予測します。
例)
{
“tablename”:”data.csv”,
“header”:[“date”,”result”,”dow_ratio”,”dow_vol”,”nasdaq_ratio”,”nasdaq_vol”],
“data”:[[“”,””,9.79,72454649,6.32,1659423]]
}
準備ができたので早速予測してみましょう。
REST API実行用のツールにURLを設定しメソッドはPOSTにします。
Header情報には Content-Type: application/json;charset=UTF-8 を設定します。
Bodyにも準備した値を設定し、Sendボタンを押します。
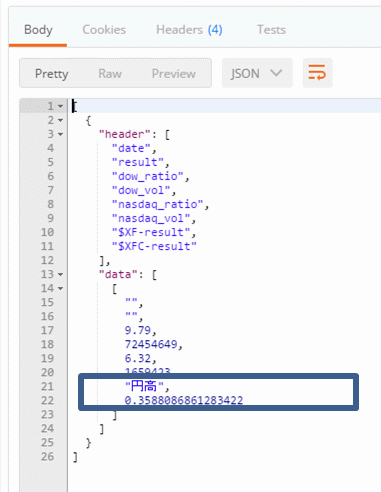
以下が予測結果です。今日の終値は前日比で円高(ドル安)になるという結果がでました。
予測の信頼度は0.35(35%)なので少々不安な予測ですが、トレード戦略としてはドル売りで始めて、円高に振れたタイミングで買い戻すという感じでしょうか。
以上がPAサービスを利用した予測です。
トレード戦略としては工夫の余地が沢山ありますが、予測アプリケーションが簡単に作成できることはご理解いただけたと思います。トレード以外にも顧客分析や在庫適正化、故障予測、品質管理など予測アプリケーションが使える場面は沢山ありますので、ぜひご利用ください。
なお、SPSSのモデルを変更するタイミングは「法則が変わった時」です。法則が変わるタイミングは予測対象により毎日であったり不変であったり様々ですが為替のようにトレンド(相場の方向性)がある場合はそれが変わったタイミングというのが一つの目安かと思います。
APIの詳細について
以下に詳細な利用方法が記載されていますので、こちらもご参照ください。
https://console.ng.bluemix.net/docs/services/PredictiveModeling/index-gentopic1.html#genTopProcId2