


watsonx.data Beta(*)版を触ってみた。(*:2023年7月7日に正式版リリース済)
投稿者:ビッグデータ担当
■はじめに
リリース前のbeta版(2023年5月時点のBeta(*)版)となりますので、リリース版とは画面や機能が異なる可能性があります。
*:2023年7月7日に正式版リリース済(URL: https://www.ibm.com/jp-ja/products/watsonx-data )
■watsonx.dataとは?
すべてのデータ、分析、AI ワークロードを拡張するために最適化された、オープンでハイブリッド、かつ管理された目的に適したレイクハウスとなります。
レイクハウスといっても、他にもウェアハウスやデータレイク等の似たような製品もあり、何が違うのかイマイチ。。という方々のためにも、簡単にそれぞれの概要を紹介いたします。
- ウェアハウス:
csv等の構造化されたデータを蓄え、且つ分析系(select)の処理に特化したデータベース。 分析系の処理ではカラム単位の集計処理が多くなるため、ウェアハウスではカラムナー型の製品が主流となります。
- データレイク:
csv等の構造化されたデータに加えて、半構造化データ(xml、json等)や非構造化データ(テキスト、画像、動画等)もすべてまとめて保存するものとなります。これにより、AI/MLを使用した分析等もできるようになります。しかし、正しく運用ができない場合、様々なデータをとりあえず入れる領域となり、データスワンプ化してしまう場合があります。
- レイクハウス:
ウェアハウス、およびデータレイクの良いところをハイブリットすることにより、それぞれに蓄えられたデータを統合的に分析することができるオープンアーキテクチャとなります。

■watsonx.dataのユースケースは?
それではwatsonx.dataはどのようなケースで使用できるかを簡単にご紹介します。
- コストを最適化したいお客様は、watsonx.dataへのオフロードによりコスト最適化が可能です。
ウェアハウスを利用している際に陥りやすいこととして、分析頻度の少ないデータもウェアハウスにとりあえずロ ードしているケースはよく見かけます。しかしウェアハウスは高速処理に特化しておりますが、データ容量当たりの課金が高いです。このようなデータについては安く格納できるストレージにオフロードして、watsonx.data上の様々なエンジンを使用することで分析処理に対するコストを最適化することができます。
- 複数のウェアハウスをお持ちとなり管理や運用にお困りのお客様は、watsonx.dataで利活用できます。
社内に複数のウェアハウスがあり、これらのウェアハウスを統合的に分析したい際にはwatsonx.dataを利用することで既存のシステムに変更を与えることなく、複数のウェアハウスのデータを組み合わせた分析等ができるようになります。
- 複数ベンダーのデータレイクをお持ちとなりベンダー間の管理や運用にお困りのお客様は、watsonx.dataで垣根を無くすことができます。
データレイクはベンダー毎に様々な製品が存在し、AWSのS3、GCPのクラウドステージ、IBMのオブジェクトストレージ等があります。しかしこれらの製品は機能によっては同じベンダー環境のデータ間でしか分析できないケースがあります。そのような場合ではwatsonx.dataを利用することで、ベンダー間の垣根を無くしデータを柔軟に取り扱うことができます。
- 様々なウェアハウス、データレイクをお持ちとなり、これら製品を管理/運用したいお客様は、watsonx.dataで統合的な管理や分析が行えます。
オンプレに存在するウェアハウス、ストレージサービス、クラウド上に存在するウェアハウス、データレイク、これら様々なデータについて統合的に分析するようなケースでもwatsonx.dataを利用することで、柔軟にデータを扱うことができます。
■watsonx.dataの機能
watsonx.dataを導入するとシステム内の各ストレージやデータベースの情報を統合的に分析を行うことができます。
以下の画面がwatsonx.dataの構成図となり、システム内に存在する様々なデータを視覚的に統合していくことが可能です。

上記について説明となります。
①エンジン:
watsonx.dataで分析する際に使用するSQLエンジンを選択することができます。
watsonx.dataではspark、presto、Db2エンジン,NZエンジン等様々なエンジンが使用することができ、処理の用途に応じて最適なエンジンを選択することが可能です。
②カタログ(オープンテーブルフォーマット):
様々なオープンテーブルフォーマットがwatsonx.dataではサポートされており、当フォーマットを使用してバケットやデータベースの情報をカタログ化し、統合的にデータを取り扱うことができます。
③バケット:
様々なクラウドストレージとwatsonx.dataを接続することができます。例えば、AWSのS3、GCPのCloud Storage、IBM CloudのObject Storage等を使用することができます。
④データベース:
様々なデータベースとwatsonx.dataを接続することができます。
※オンプレ、クラウドどちらの環境上にあるデータベースと接続可能です。
■watsonx.dataの所感
goodポイント:
- 直感的に操作ができ、ユーザは箱を追加して線で結ぶだけで様々なクラウド上のストレージやデータベースのデータを統合的に分析できる点
- AWSのS3のデータとGCPのクラウドストレージのデータを統合して分析できる等、クラウド上のデータをベンダーの垣根無く分析することができる点
- エンジンを自由に組み替えれる為、処理に応じて最適なリソースを使用することができる点
今後の期待ポイント:
- beta版の為、GUIからのロード時のでリミッター等が選択ができませんでした。(リリース版では改良されているはずです。 )
- columやテーブル名としては日本語文字が対応していないので、いずれサポートされることを期待。(データは日本語文字入ります。)
- watsonx.dataに対して自然言語で調査や分析をする機能もリリース版では使用できます。 (以下画面の左側で言語による会話で分析や確認したいデータを表示できます。)
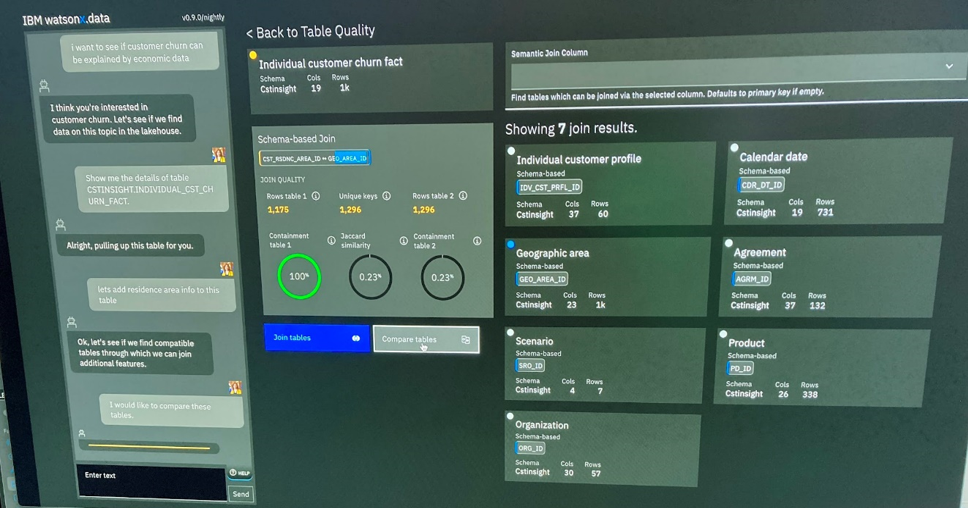
■Beta版を触ってみた。
以下は実際にwatsonx.dataのbeta版を触ってみた際の紹介となります。
1.ホーム画面

2.メニュー画面


3.Ingestion hub画面からcsvをwatsonx.dataへロード
3.1.[Create ingestion job]をクリック

3.2.[Drag and drop files here or click to upload]にcsvファイルをドラッグ&ドロップします。

3.3.csvの場合、データから自動的に各カラム名とカラム名に対応するデータ型が選択されます。
※赤枠をクリックすることで任意のデータ型を選択することも可能。

3.4.既存or新規のカタログテーブルにいれるか等の情報を入力して[Next]を押下するとデータロードできます。

3.5.ジョブの実行結果はIngestion hubの画面から確認可能です。

4.クラウド環境のRDSとwatsonx.dataの接続
4.1.今回はAWS環境上に構築したRDSをwatsonx.dataから接続する際の流れをご説明します。
まずはメニュー画面からInfrastructure manager画面に遷移し、右上の[Add component]から[Add database]を選択します。

4.2.[Add database]ウィンドウの中で接続するデータベースの情報を入力します。
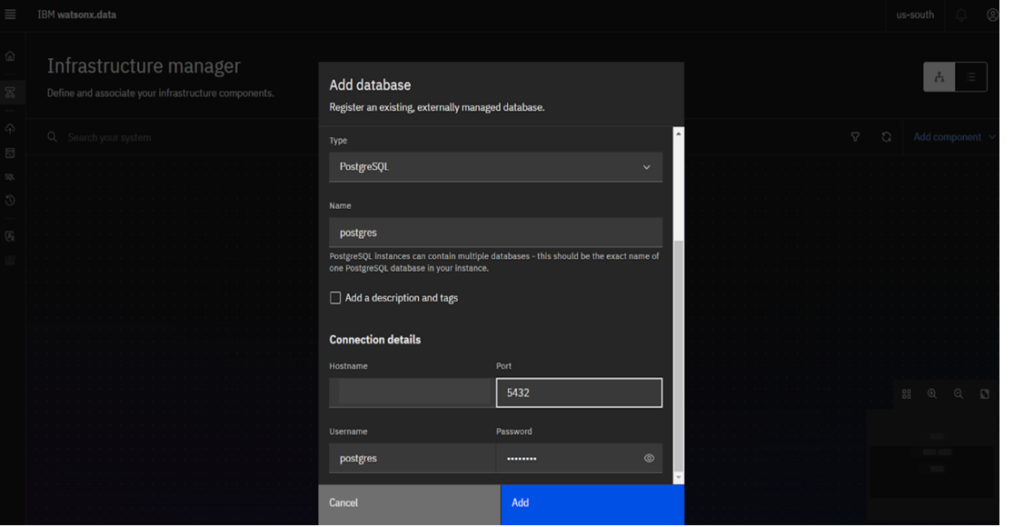
4.3.追加が完了するとInfrastructure画面にて追加したデータベースのアイコンとwatsonx.data内でカタログ化されたアイコンが確認できます。

4.4.追加されたカタログにマウスを合わせると、コネクタのアイコンが表示されます。そこをクリックするとカタログとエンジンを紐づけることができます。

4.5.紐づけるエンジンを選択して[Associate and restart engine]をクリックします。

4.6.カタログとエンジンの紐づけに伴いエンジンが再起動します。

4.7.エンジンの再起動後、エンジンとカタログの紐づけが完了し、watsonx.dataから追加したRDSに対してクエリ実行ができるようになります。

4.8.Data explore画面からも追加したデータベース情報が参照できるようになります。

5.外部環境からwatsonx.dataへの接続
5.1.メニュー画面の[Access control]画面からwatsonx.dataへの接続情報が確認することができます。

5.2.watsonx.dataへの接続情報はエンジンコンポーネントに関連付いています。

5.3.watsonx.dataのエンジンの接続情報が確認できます。

5.4.DB接続ツール(今回はフリーツールであるDbeaverを使用)にて接続設定を行います。
※ユーザ名/パスワードはibm cloudのIamの設定でAPIキーを取得し、その情報を入力します。

5.5.DB接続ツールからwatsonx.data内のカタログ情報へ接続可能となります。

watsonx.dataサイトへのリンクはこちら。