


watsonx.dataでAWS S3とデータベースを繋いでみた。
投稿者:ビックデータ担当
■はじめに
今回はwatsonx.data上でAWS S3とデータベースを接続検証を行った記事となります。
2023年10月時点のバージョンとなります。バージョンにより画面や機能が異なる可能性がありますのでご注意ください。
※watsonx.dataの概要等はこちらをご参照ください。
■今回実施したこと
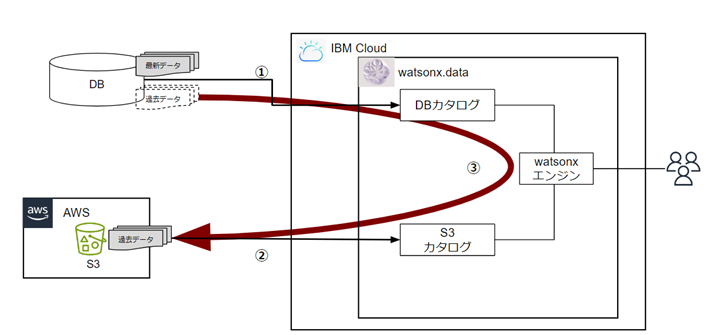
AWS S3とデータベース(AWS RDS)を用意し、watsonx.data上にそれぞれを接続設定を行いwatsonx.data上からデータベースのデータをS3に連携させる検証を行いました。
本検証として以下のステップでご紹介します。
①watsonx.dataにDBを設定
②watsonx.dataにS3を設定
③DBのデータをS3に連携
・実施イメージ図
■用意した環境
バケット: S3
データベース: AWS RDS
■実施手順
①watsonx.dataにDBを設定します。
※こちらの”4.クラウド環境のRDSとwatsonx.dataの接続”を参照してDBを接続します。
設定するDBの情報は以下。
データベース・タイプ:PostgreSQL
データベース名:postgre
ホスト名:postgres.XXXXXXXXXXXXXXXXX.ap-northeast-1.rds.amazonaws.com
ユーザ名:postgreDBユーザ
②watsonx.dataにS3を設定します。
設定するS3としては接続できる為に、以下の設定を実施します。
※実際にご利用いただく際は環境に応じてセキュリティを設定ください。
・ブロックパブリックアクセス
パブリックアクセスをすべて ブロック オフ・バケットポリシー
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Statement1",
"Effect": "Allow",
"Principal": "*",
"Action": "s3:*",
"Resource": "arn:aws:s3:::バケット名/*"
}
]
}
1) インフラストレクチャー画面から”バケットの追加”をクリックします。

2) バケット情報を入力します。
※エンドポイントはS3ご利用の際は以下となります。
s3.リージョン名.amazonaws.com
今回は東京リージョンなので以下となります。
s3.ap-northeast-1.amazonaws.com
参考)カタログタイプとしては現時点では以下のオープンフォーマットテーブルを指定可能です。
今回はIcebergを選択します。(他のタイプでも問題ございません。)

3) 追加が完了するとInfrastructure画面にて追加したデータベースのアイコンとwatsonx.data内でカタログ化されたアイコンが確認できます。

4) 追加されたカタログにマウスを合わせると、コネクタのアイコンが表示されます。そこをクリックするとカタログとエンジンを紐づけることができます。

5)紐づけるエンジンを選択して[保存してエンジンを再起動する]をクリックします。

6)エンジンの再起動後、エンジンとカタログの紐づけが完了します。
7)データ・マネージャー画面から[図式の作成]をクリックします。
※S3の紐づけが完了した段階では、まだwatsonx.dataとS3で連携はできず、以下の画面操作にて登録したS3ディレクトリがwatsonx.data上でデータ連携できます。
※現在は当操作で作成したS3バケット内のディレクトリ配下のみのデータをwatsonx.dataと連携きますが、今後の改修でカタログ化S3バケット内の全てのデータを参照できるようなるとのことです。

8)S3バケット内にディレクトリを作成します。

9)S3バケット内にディレクトリを作成されたことが確認できます。

参考) S3から確認すると以下のように表示されます。
※test_watsonxのディレクトリが作成されます。

10)S3バケット内にディレクトリを作成されたことが確認できます。
③DBのデータをS3に連携します。
今回は”sales_data”テーブルの古いデータ(2004年より前のデータ)をS3にコピーするものとします。
1) 対象データの件数を確認します。
2024年12月より前のレコードの件数を確認するSQLを実行します。

件数を確認します。

2) 対象データをS3にコピーします。
S3にコピーをする際は、ctasコマンド(create table コピー先テーブル名 as select コピー元テーブル)で作成できます。
今回の場合はRDSの”rds_postgres”.”public”.”sales_data”のデータを
S3領域の”s3_nic_test”カタログの”test_watsonx”バケット内に”sales_data_archive”を作成します。

3)カタログ上からはS3上のカタログ配下にsales_data_archiveテーブルができました。

4)S3からは以下のようにファイルが作成されています。
作成したテーブル名のフォルダが作成されています。

中身はdataフォルダとmetadataフォルダになります。

dataフォルダにはデータがparquet形式で保存されています。

metadataフォルダにはテーブル構造等のメタ情報が格納されています。

■watsonx.dataとS3連携の感想
watsonx.dataとS3連携も非常に簡単で、数分程度の操作でつなげることができました!
当初はS3側でアクセスポイントを別途作成する必要があるかな?と考えていたりしましたが、S3側でアクセスポイントを作成せずに接続可能となります。
今回の紹介ではAWS S3とAWS RDSとの連携の紹介となりましたが、wastonx.dataにIBM ObjectStorageやオンプレのデータベース等も設定することにより、オンプレ/クラウド間の垣根なくwatsonx.data上で様々な場所にあるデータを分析できるようになります。