


Treasure Data CDP<第7弾>Treasure Workflow とは(後編)
投稿者:吉田 英利

NI+C マーケソリューションチームです:)
本Tech Blogでは、NI+Cで取り扱っているTreasure Data CDPを紹介していきます。
前回は、Treasure Workflow の概要・ワークフロー画面(前編)についてご紹介させていただきました。
今回は、Treasure Workflow の実践編(後編)のご紹介させていただきます。
本編は、Treasure Workflow のワークフローの記述方法と実行方法のご紹介となります。
Treasure Workflow の概要についてご興味ある方は、前編をご覧ください。
これまでのブログををご覧になっていない方は
「Treasure Data CDP <第1弾>Audience Studio の機能でセグメント作成してみた!!」
「Treasure Data CDP <第2弾>Audience Studio の機能 Activation を使ってみた!」
「Treasure Data CDP<第3弾>Audience Studio の機能 Predictive Scoring のご紹介」
「Treasure Data CDP<第4弾>Treasure Data にデータをインポートしてみた」
「Treasure Data CDP<第5弾>SQL を使ってデータ抽出してみた!」
「Treasure Data CDP<第6弾>Treasure Workflow とは(前編)」
を是非ご覧下さい!
~Treasure Data CDP についてのおさらい~
第1弾でご紹介をしましたが、
Treasure Data CDP はトレジャーデータ社が提供するカスタマーデータプラットフォーム(CDP)です。
データの収集、統合、分析、施策への連携の機能があり、これらを柔軟に実行ができる強みを持っています。
ただデータを管理するのではなく、170を超える連携コネクタを使い多種多様なデータを収集することや、ワークフローを使いデータ処理の自動化、
セグメンテーションを用いて顧客1人ひとりに最適な施策を実行できることが可能となっています。
主にTreasure Data CDP で実現できることは
「データ整理と一元管理」 「データの見える化」 「デジタル戦術」….
など、その他にも様々な分析や活用の仕方があります。
今回は、Treasure Data が提供している Treasure Workflow についてご紹介したいと思います。
※Treasure Data CDP の特徴について詳しく知りたい、という方は下記のトレジャーデータ社のHPをご覧ください。
「https://www.treasuredata.co.jp/press_release_jp/20181003_arm_treasure_data_audience_suite/」
~ Treasure Workflow ~
前編でもご紹介させていただきましたが、
Treasure Data では、Treasure Workflow を使用してワークフローの作成と実行ができます。
Treasure Workflow では、
定期的、定型的にSQLを自動実行・外部データのデータロードの処理内容を定義・エラー時の再実行など
様々な機能を持っています。
それでは実際に Treasure Workflow のワークフローの記述方法と実行方法を見ていきましょう!
まずは、ワークフローの記述方法からみていきましょう。
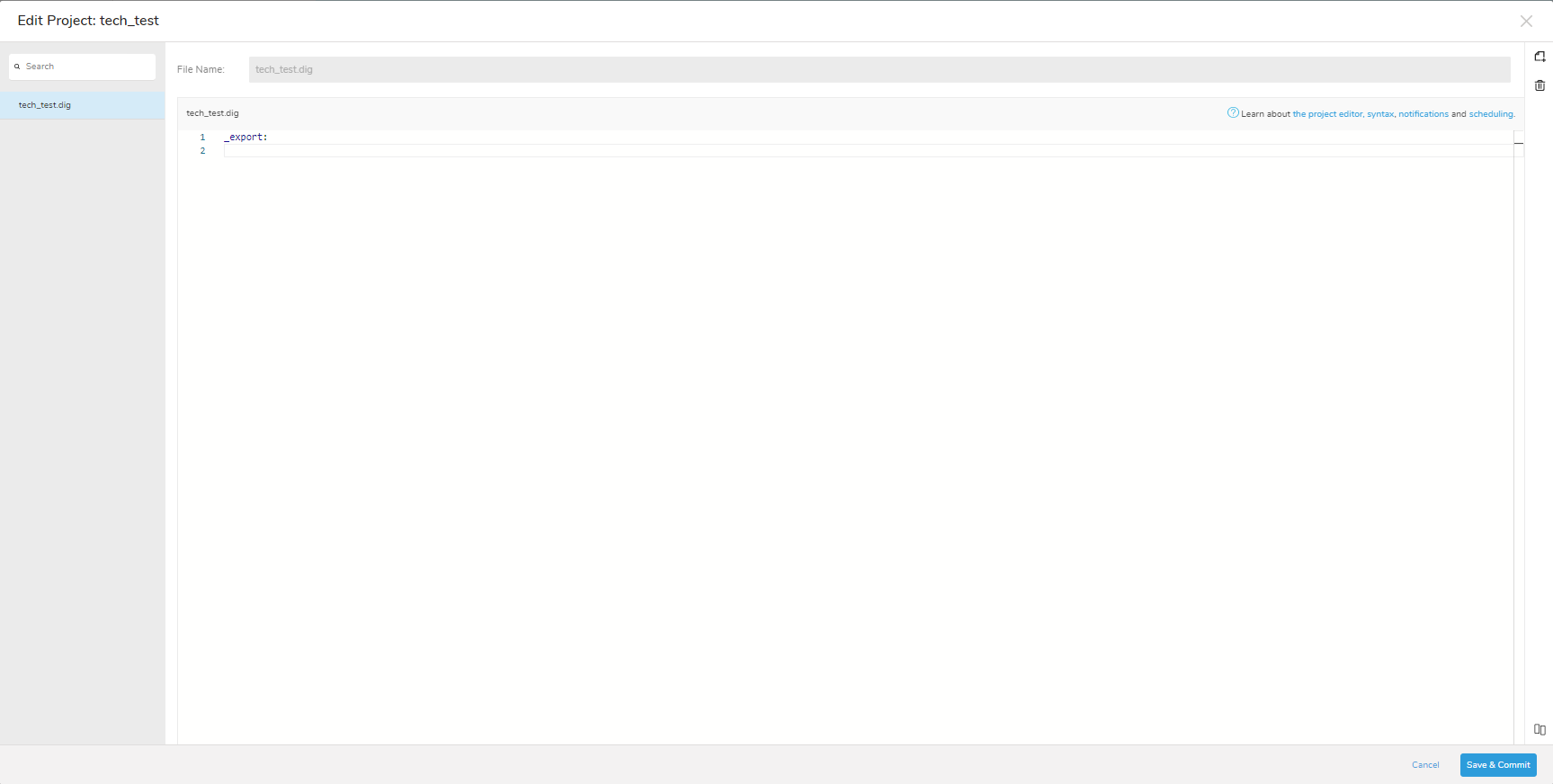
今回は、2つのテーブルのデータを結合してデータ件数を抽出するワークフローを作成して実行していきます!
(データベース「tech_data」とテーブル「tech」、「tech_data1」を使用します)
テキストファイルにワークフローコードを入力していきましょう。
テキストファイルの中に「○○>:」と入力されている箇所があります。
「○○>:」はオペレーターといって実際の処理内容を定義したものとなっています。
オペレーターは Treasure Workflow の中で定義されているものが使用でき、クエリの実行や繰り返しなどを定義できるようになっています。
今回はよく使用するオペレーターを入力しています。
それぞれの枠のコードを見ていきましょう。
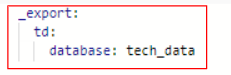
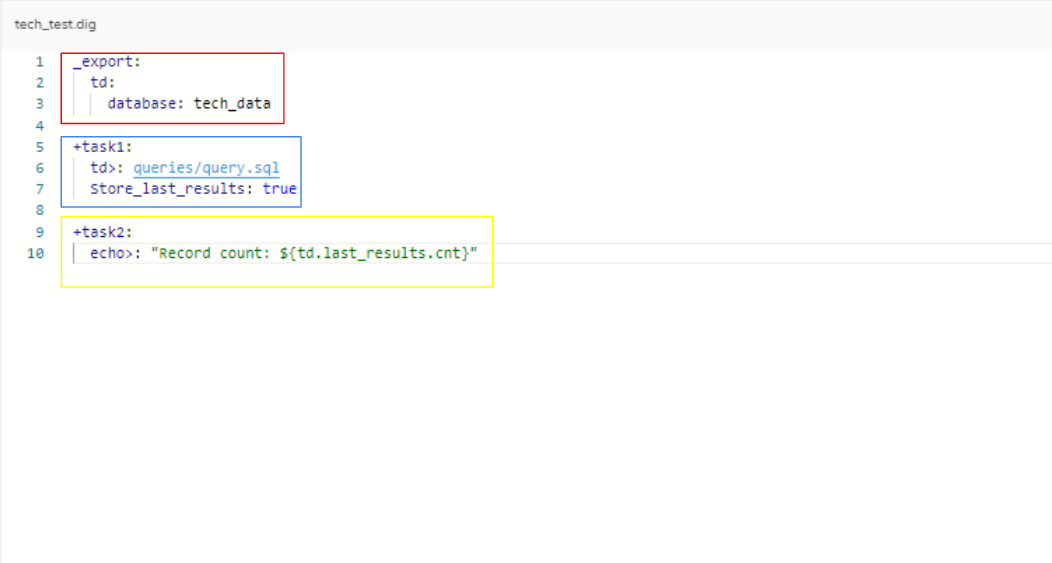
赤枠では変数定義をしています。
「_export:」で定義した変数をワークフロー内で使用することができます。
「td: database:○○」で変数(データベース)を指定します。
今回は「tech_data」のデータベースを入力しています。
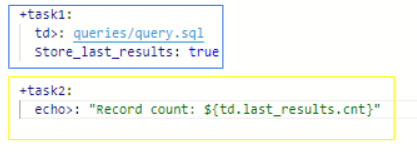
青枠と黄枠で共通して入力されている「+task〇:」は、タスクといってワークフロー内で実行される処理単位を示しています。
「+○○」と入力されている○○はタスク名となっていて、任意の名前を指定できるようになっています。
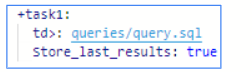
青枠のタスクでは、最初に処理されるコードが入力されています。
「td>:○○」で Treasure Data のクエリを実行します。
実行するクエリはワークフロー内で作成して使用することができます。
「○○」は、このワークフロー内に作成したクエリが保存されているファイルのファイル名を指定することで、クエリを処理に埋め込み実行することができます。
今回は「queries/query.sql」とファイル名を入力しています。
※「queries/query.sql」の作成は後にご紹介させていただきます
「store_last_results: true」では、「queries/query.sql」の処理結果を黄枠の「td.last_results.cnt」の変数に保存します。

黄枠のタスクでは、2番目に処理されるコードが入力されています。
「echo>:”Record count: ${td.last_results.cnt}」で、青枠タスクの処理結果をワークフローの結果として表示させるようにしています。
「${td.last_results.cnt}」で保存していた変数の内容を参照します。
今回の場合、2つのテーブルのデータを結合したデータ件数が表示されるようになっています。
メインのファイル編集は完了しましたが、
実行させるクエリのファイルの作成ができていないので作成していきましょう!
ファイル追加を選択します。
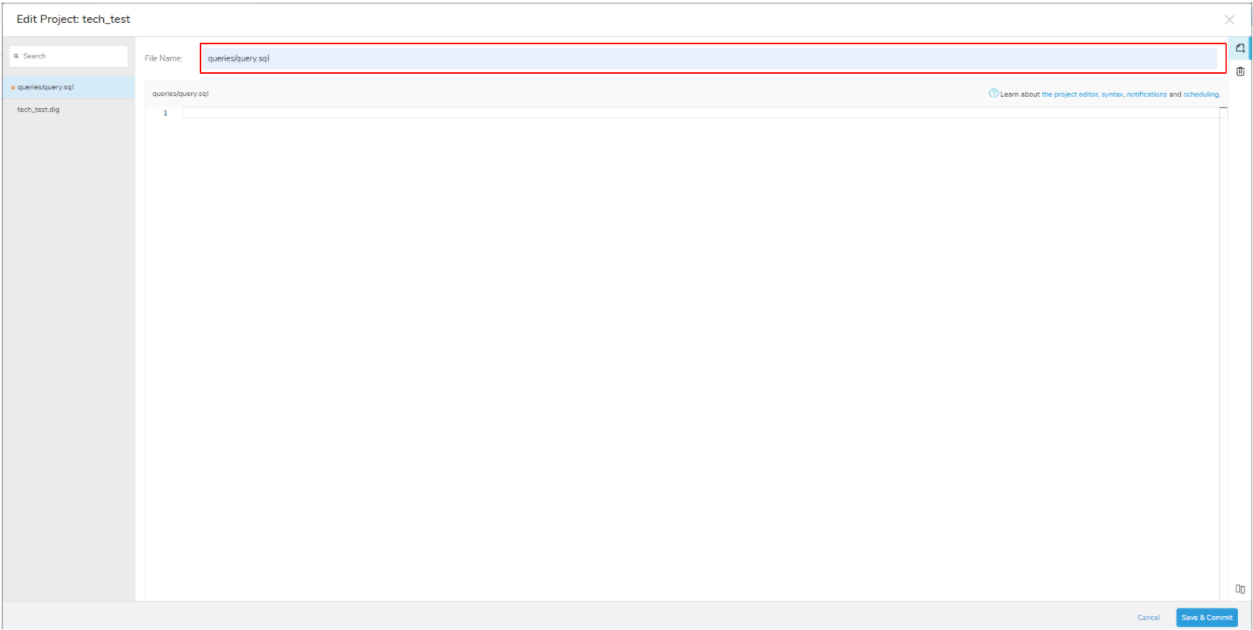
File Name にファイル名を入力します。
(今回は「queries/query.sql」と入力します。)
テキストファイルの中に今回使用するクエリを入力していきましょう。
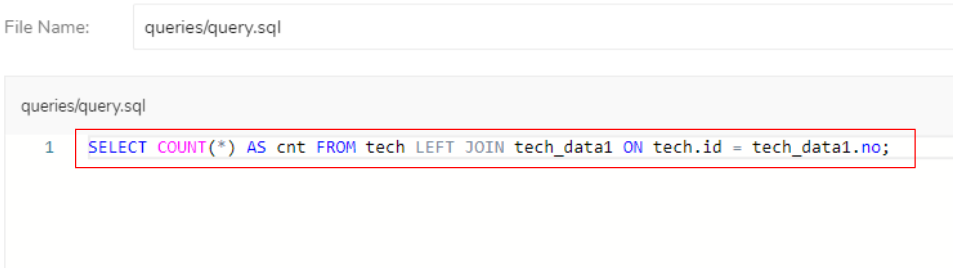
「SELECT COUNT(*) AS cnt FROM tech LEFT JOIN tech_data1 ON tech.id = tech_data1.no;」を入力して、テーブル「tech」のデータをテーブル「tech_data1」のデータと結合したデータ件数を抽出するファイルを作成します。
(今回の各テーブルの主キーは、テーブル「tech」は「id」、テーブル「tech_data1」は「no」となっています)
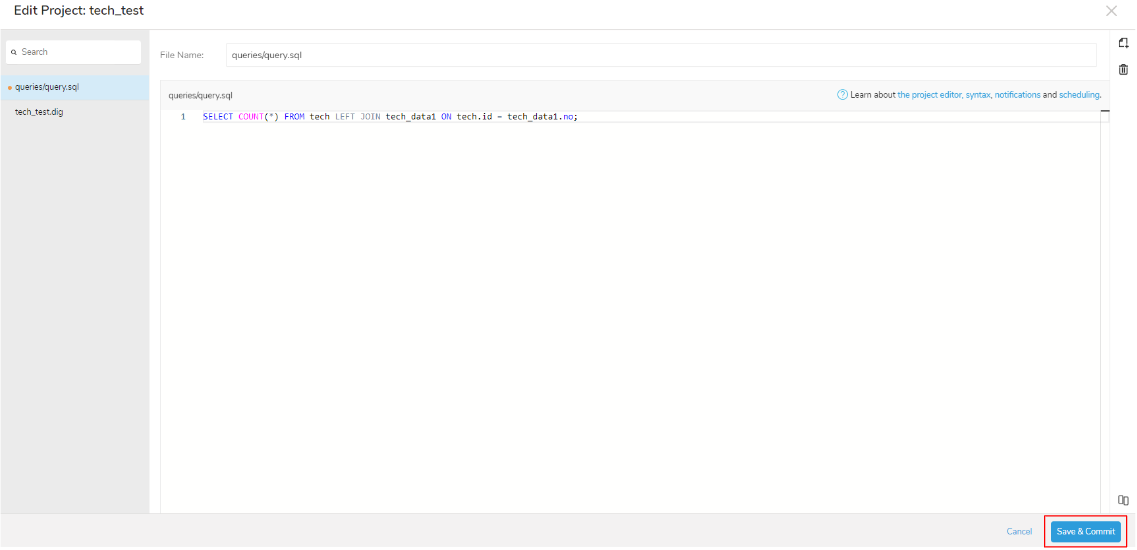
クエリの入力が完了しましたら「Save & Commit」を選択して保存します。
保存後「queries/query.sql」が実行され、結果が ${td.last_results.cnt}に保存されます。
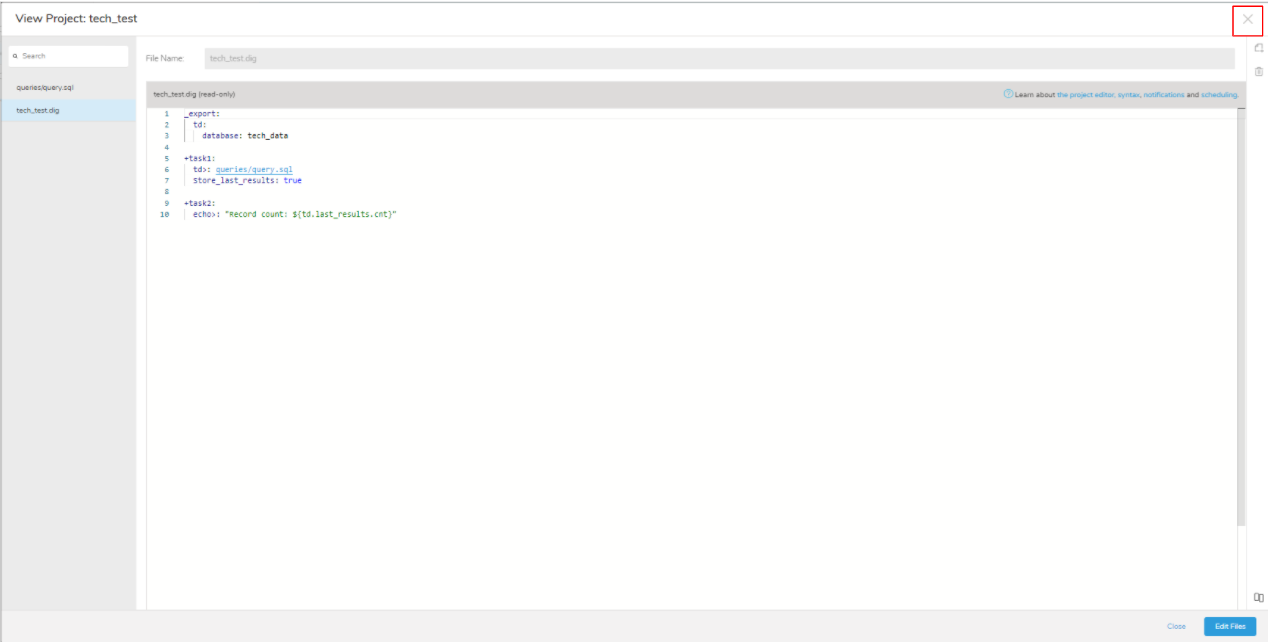
ワークフローの編集が完了したら「×」を選択して編集画面を閉じます。
設定と編集が完了したのでワークフローを実行していきましょう。
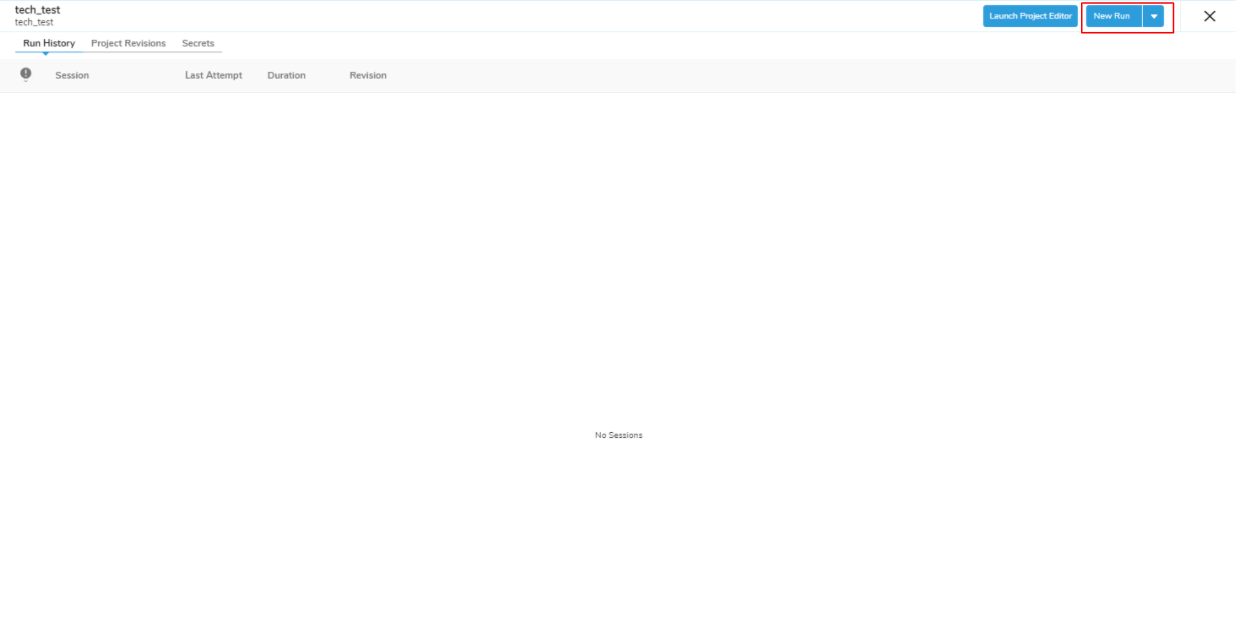
「New Run」を選択します。

表示されたセッションを選択します。
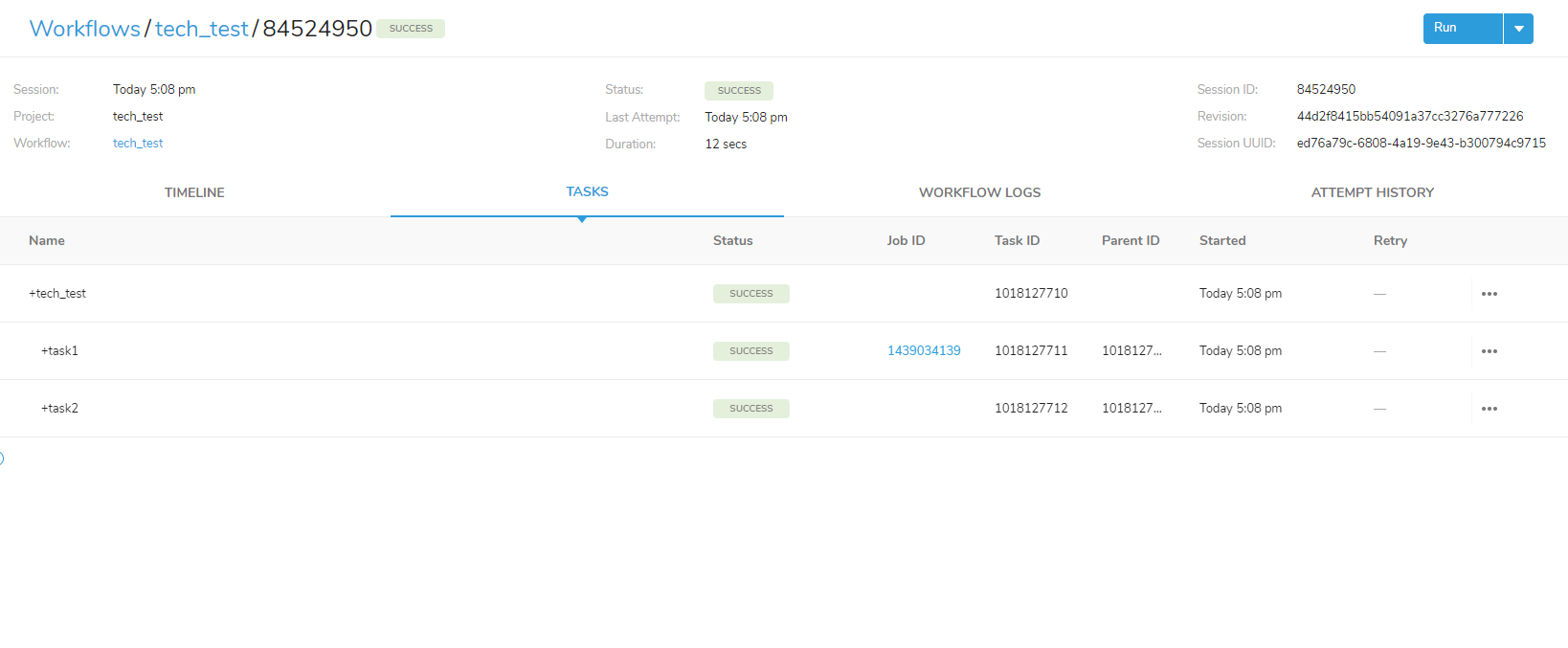
「SUCCESS」と表示されているため、ワークフローの実行が無事にできました!
入力したタスクの処理も無事に実行されています。
タスクの処理内容も見てみましょう。
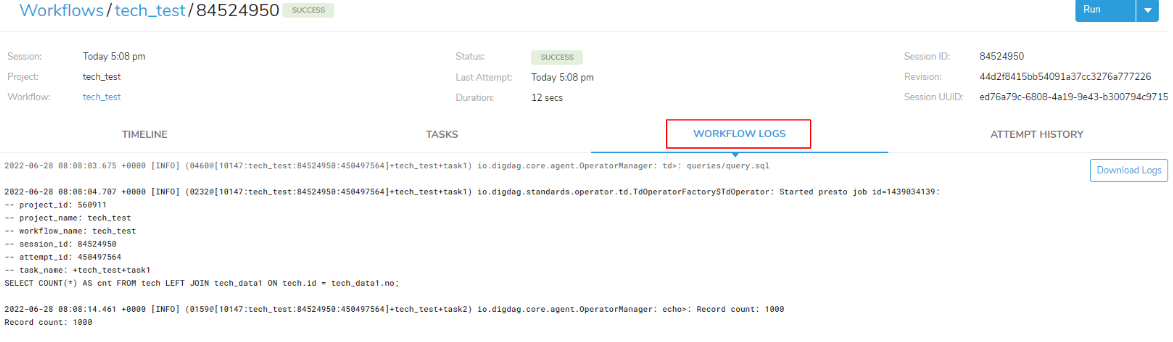
今回のタスク処理内容は赤枠の「WORKFLOW LOGS」から確認することができます。

task1 では、「td>: queries/query.sql」の処理が無事に完了してクエリの「SELECT COUNT(*) AS cnt FROM tech LEFT JOIN tech_data1 ON tech.id = tech_data1.no;」の実行をしています。

task2 では、task1 のクエリ結果が「echo>:”Record count: ${td.last_results.cnt}」の ${td.last_results.cnt} に保存され 1000 と表示されています。
また、ワークフローの処理結果として「Record count:1000」と表示されています。
task1 と task2 のように詳細にワークフローの処理内容を確認することができます。
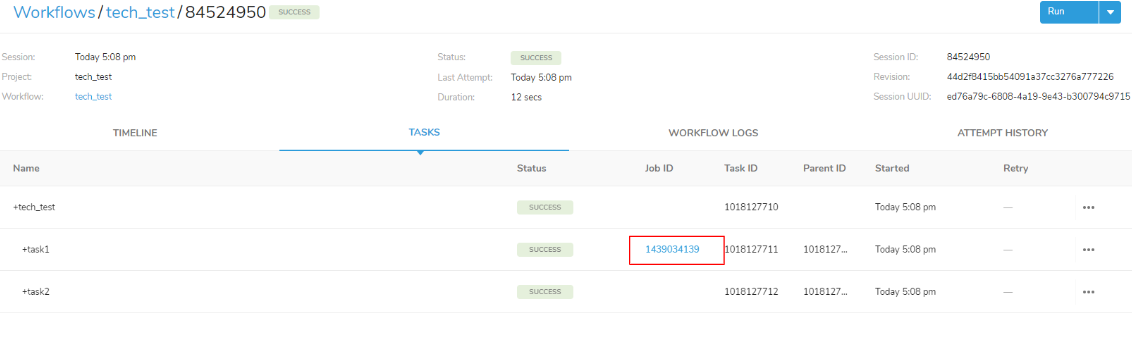
実行されたクエリの結果は、赤枠の「Job ID」を選択して頂いても確認することができます。
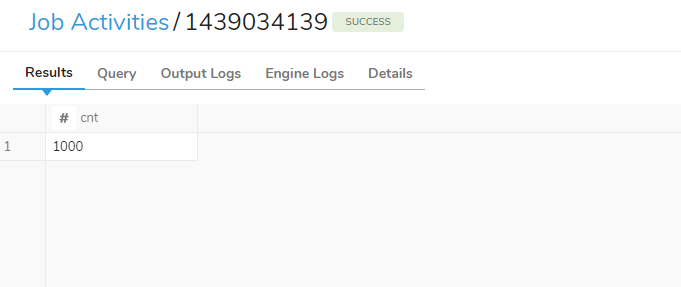
「Job ID」を選択すると、クエリの実行結果を確認することができます。
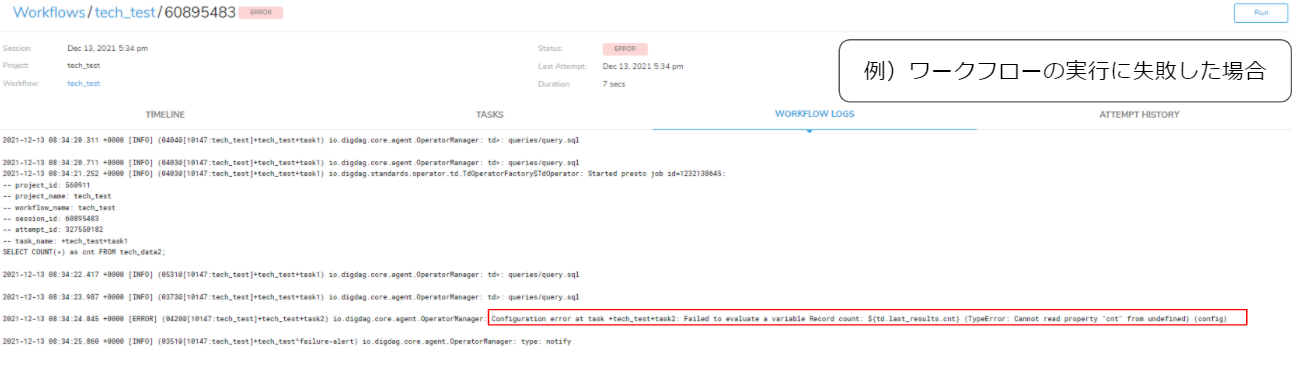
もし、ワークフローの実行に失敗してエラーが出た場合は、赤枠のようにエラーの原因とワークフローコードを示してくれます。
エラー内容を示してくれるため、素早くワークフローの修正ができるようになっています。
ワークフローを実行した際は「WORKFLOW LOGS」で処理内容を確認してみてください。
今回は Treasure Workflow を使用してデータ件数を取得しましたが、
・スケジュールを設定して定期的にSQLを実行するワークフロー
・S3に配置されているデータファイルのインポートをするワークフロー
など他にも沢山の用途でTreasure Workflow を使用することができます。
使用する機会がありましたら、是非試してみてください。
長くなってしまいましたが、Treasure Workflow について少しでもイメージを持つことができたでしょうか?
ご興味を持たれた方はぜひ「こちら」からお問い合わせください!
※セグメント作成についてまだご覧になっていない方は、↓↓
Treasure Data CDP <第1弾>Audience Studio の機能でセグメント作成してみた!!
Activationについてまだご覧になっていない方は、↓↓
Treasure Data CDP <第2弾>Audience Studio の機能 Activation を使ってみた!
Predictive Scoring についてまだご覧になっていない方は、↓↓
Treasure Data CDP <第3弾>Predictive Scoring のご紹介
データのインポートについてまだご覧になってない方は、↓↓
Treasure Data CDP <第4弾>Treasure Data にデータをインポートしてみた
SQLを使ったデータの抽出方法についてまだご覧になっていない方は、↓↓
Treasure Data CDP<第5弾>SQL を使ってデータ抽出してみた!
Treasure Workflow(前編)についてまだご覧になっていない方は、↓↓
Treasure Data CDP<第6弾>Treasure Workflow とは(前編)
を是非ご覧下さい!!
今回は、Treasure Data の Treasure Workflow(後編) についてのご紹介でした。
では、次回もお待ちしております。
ありがとうございました!