


Dataflow でストリーミングの重複除去を試したい
投稿者:jyokoyama

はじめに
アドベントカレンダー 初参戦となります。記念すべき初投稿が締切ギリギリアウトとなってしまいましたが、一生懸命書きましたのでご勘弁ください。
さて、Dataflow といえば Pub/Sub の at-least-once なメッセージの重複除去で有名ですよね。
重複除去の実装って実際はどんな感じになるのかが気になったので、公式のチュートリアル に沿ってストリーミング処理を実装してみました。
※ ネタバレで恐縮ですが Pub/Sub 起因の重複除去は Dataflow が自動で行ってくれる らしく、今回は意識する必要はありませんでした。
Dataflow とは
Dataflow はフルマネージドなデータ処理サービスです。
Apache Beam のランナーとして働きます。
Apache Beam は OSS のデータパイプライン用のプログラミングモデルで、バッチデータ処理にもストリームデータ処理も行うことができます。
名前の由来も B(atch & Str)eam -> Beam という噂です。
込み入ったデータ処理をする場合は Beam でプログラミングする必要がありますが、今回は簡単なパイプラインなので Dataflow のテンプレートを指定するだけで対応できます。
ノーコードです。
テンプレートについて詳しく知りたい方は こちら をどうぞ。
いざ実装
実行環境
- Windows 10
- Google Cloud SDK
- コマンドはすべて PowerShell で実行
完成イメージ
こんな感じを目指します。

数分おきに Cloud Scheduler から Pub/Sub に JSON 形式のメッセージをパブリッシュ。
Dataflow がそれをサブスクライブして表形式に変換して BigQuery にロードするという構図です。
手順
概要
こんな感じで進めます。
- IAM 権限の設定やら認証やら。
- Dataflow が裏で使う Cloud Storage のバケットを作成。
- Pub/Sub のトピックとサブスクリプションを作成する。
- Cloud Scheduler で Publish ジョブを作成して開始する。
- BigQuery にデータロード先のデータセットとテーブルを作る。
- Dataflow でパイプラインを実行する。
- BigQuery で実行結果を確認する。
具体的な手順に進む前に、以降の読み方について一点注意させてください。
以下文中の [] で囲んでいる文字列は、あなたの環境に合わせて読み替えてください。
キャプチャの中の文字列は [] で囲んでいませんが、察して読み替えていただけると…
1. IAM の設定
チュートリアル に従って IAM の設定や認証などを行います。
(あからさまに IAM への興味が薄くてごめんなさい。)
2. バケットの作成
gsutil mb -l asia-northeast1 gs://dataflow-expt-bucket
3. Pub/Sub のトピックとサブスクリプションの作成
# トピックの作成
gcloud pubsub topics create [dataflow-expt-topic]
# サブスクリプションの作成
gcloud pubsub subscriptions create --topic [dataflow-expt-topic] [dataflow-expt-topic-sub]
4. Cloud Scheduler ジョブの作成
メッセージの内容 (‘positive’, ‘negative’) には特に意味はないので気にしないでください。
# 1分おきに'positive'メッセージを公開するパブリッシャージョブの作成
gcloud scheduler jobs create pubsub [dataflow-expt-scheduler-job-positive] --schedule="* * * * *" --location=asia-northeast1 --topic=[dataflow-expt-topic] --message-body='{"url": "https://beam.apache.org/", "review": "positive"}'
# ジョブの開始
gcloud scheduler jobs run --location=asia-northeast1 [dataflow-expt-scheduler-job-positive]
# 2分おきに'negative'メッセージを公開するパブリッシャージョブの作成
gcloud scheduler jobs create pubsub [dataflow-expt-scheduler-job-negative] --schedule="*/2 * * * *" --location=asia-northeast1 --topic=[dataflow-expt-topic] --message-body='{"url": "https://beam.apache.org/", "review": "negative"}'
# ジョブの開始
gcloud scheduler jobs run --location=asia-northeast1 [dataflow-expt-scheduler-job-negative]
実は ↑ のコマンド設定だけでは動きません。
Cloud コンソールから Cloud Scheduler のジョブの定義を以下のように修正する必要があります。
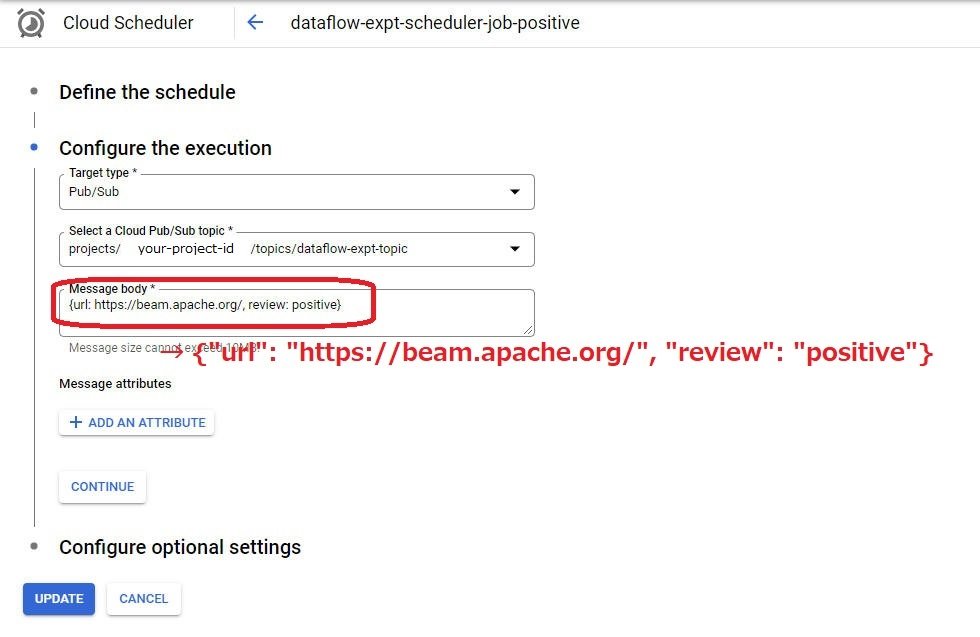
なぜ gcloud で確かに指定したダブルクォーテーションが外れてしまうんでしょうか…
困るなあ。
5. BigQuery にデータセットとテーブルを作成する
# データセットの作成
bq --location=asia-northeast1 mk [your-project-id]:[dataflow_expt_dataset]
# テーブルの作成
bq mk --table [your-project-id]:[dataflow_expt_dataset].[dataflow_expt_table] url:STRING,review:STRING
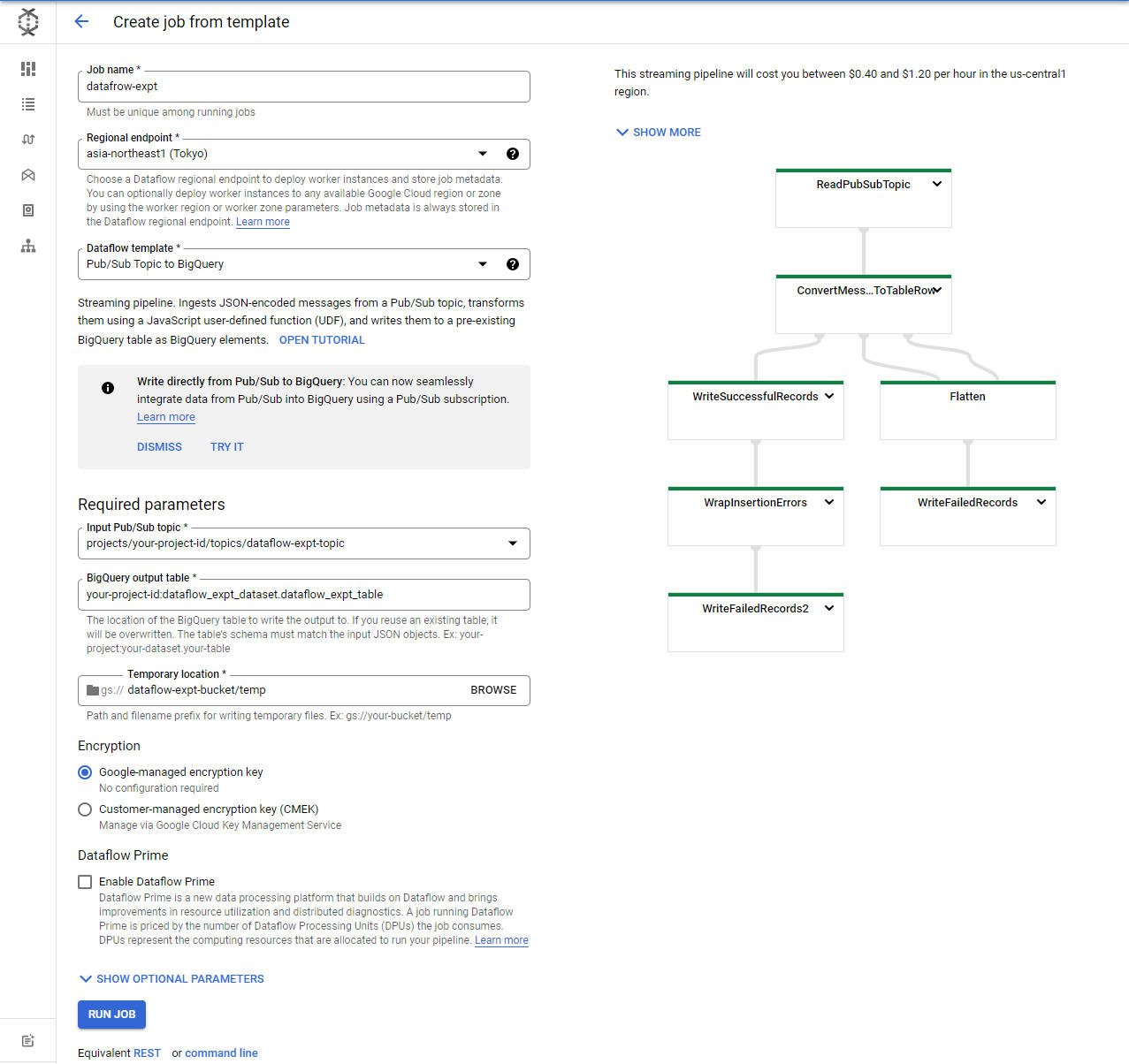
6. Dataflow でパイプラインを実行
gcloud ではどうしてもうまくいかなかったので、Cloud コンソールから。
以下のように設定してください。
※ “Temporary location” の入力の末尾に “/temp” をつけるのを忘れないように注意してください。
7. BigQuery で結果を確認
Cloud コンソールよりテーブルの中身を確認してみます。
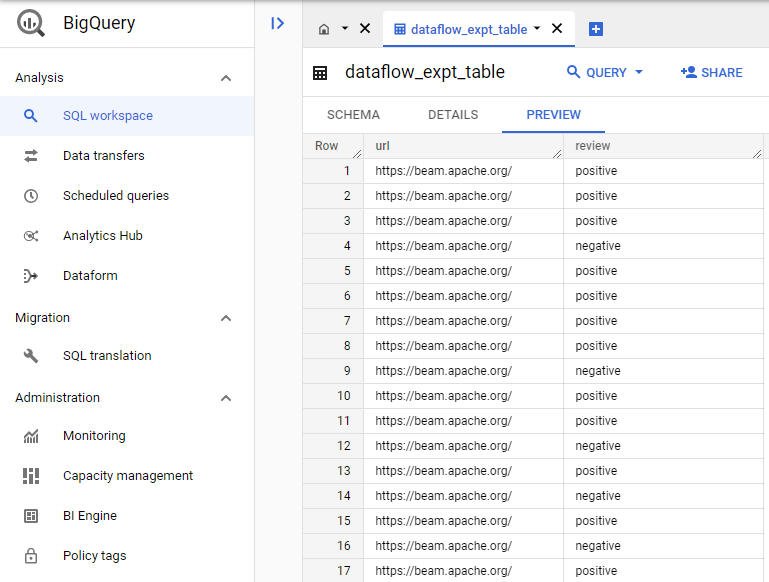
わー入ってる入ってる!
今回はデータの重複が確認できるようなスキーマではありませんが、冒頭にネタバレした通り重複除去はしっかり行われていると信じ、チュートリアルを終了したいと思います。
おわりに
冒頭にリンクを貼ったブログ にありました通り、重複データの発生箇所によって重複除去のやり方は異なります。
パイプライン実装の際には注意が必要ですね。
最後まで読んでくださいましてありがとうございました。
参考資料
Pub/Sub から BigQuery へのストリーミング
Dataflow と Pub/Sub を使用して、ストリーミング パイプラインの重複データを処理する