


Lookerのデータガバナンスが良いらしい
投稿者:Akihiko Ito
本記事は、Looker Advent Calendar 2020 の4日目の記事です。
はじめに
「Lookerってデータガバナンス良いらしいじゃん?」的なことを聞かれることが増えてきておりますので、その都度説明していることを整理してみようと思います。そして次に聞かれた時にはそっとこの記事をご紹介しようかと。。。
まず自己紹介をさせて頂きますと、私はお客様にLookerをご紹介したり、Lookerを導入してお客様のデータ活用をご支援したりといったことを日々行っています。
お伝えしたいこと
- ・Lookerで実現できるデータガバナンスについて具体的なイメージを持って頂きたいです。
- ・ユーザーの業務視点でどんなイメージになるかをお伝えしたいと思うのでテクニカルは話はあまりありません。
データは新しい「資源」だとか、「データの民主化」といった言葉はここ数年聞くことが増えていますし、昔に比べて専門家でない一般の担当者の方でもデータに関連する業務が増えているかと思います。
そこで、
- ・そのデータは正しいものなのか?
- ・誰でも見れてよいものなのか?
ということが必然的に重要になってきます。
データを身近なものにするのは大事なことですが、何でもかんでも自由に見れれば良いのではない!という話ですね。
そもそもデータガバナンスって
データガバナンス。最近良く聞く言葉ですね。
まずこの言葉の定義を確認してみたいと思います。
ガバナンスというと、なんか、だれかが管理する仕組みでしょと思っている方もいらっしゃると思いますが、データマネージメント知識体系ガイドによると、「データ資産の管理(マネジメント)に対して、職務権限を通し統制(コントロール)すること」だそうです。
まぁおおよそ思っていることと同じだと思いますが、もう少しブレークダウンしますと以下のようになります。
①データ定義の集中管理
一元的に管理してユーザー間のずれをなくす
②権限によるアクセス制御
適切なデータを適切な人に適切な形で提供しそれを容易に管理する
③データカタログ(データの辞書)
エンドユーザーにデータの意味を正しく理解して正しく使ってもらう
の3つが必要になります。
それでは1つ1つを見ていきましょう。
①データ定義の集中管理
まずデータ定義を集中管理していない場合は、担当者や組織ごとにレポート結果のずれが生じてしまう可能性があります。
いやいやまさか~。と思う方もいるかと思いますがBIではわりとよくある話です。
原因としては売上に含める定義が違っていたり、利益率といっても分子分母の変数が違っていたり、繰り上げ繰り下げで微妙に数字が異なったり、売上に合算するテーブルのデータ項目や条件が異なるなどです。
これでは担当者もしくは別の人が見たときに、レポート結果からの判断やアクションを誤る可能性があります。
Lookerはこの部分を制御するLookMLというLooker最大の魅力といってもよい(勝手にそう思っている)素晴らしい機能があり、多くの方がいろいろ紹介しているかと思いますのでここでは割愛しますが、LookMLによるデータガバナンスレイヤーを持つことで、主に2つのメリットがあります。
・全員が同じ定義をもつ数字を利用することで、認識の相違がなくなり正しい意思決定ができる。
・ユーザがデータを利用する時に、その項目の意味を正しく理解して利用できる。
②権限によるアクセス制御
権限によるアクセス制御は大きく3つあります。
1、2はまあそうだよねといった感じで、大事なのは3ですのでここでは3をご紹介します。
1.コンテンツアクセス
・作成したレポートやダッシュボードの参照に関するアクセス制御
2.機能アクセス
・機能に関するアクセス制御
例:データモデル機能はデータ管理グループのみ許可
3.データアクセス
・データに関するアクセス制御
例:本部グループはすべてのデータを閲覧可能。東エリア担当営業グループは東エリアのデータのみ許可
・テーブルや列に関するアクセス制御
例:顧客情報はデータ管理グループのみ許可
●データに関するアクセス制御
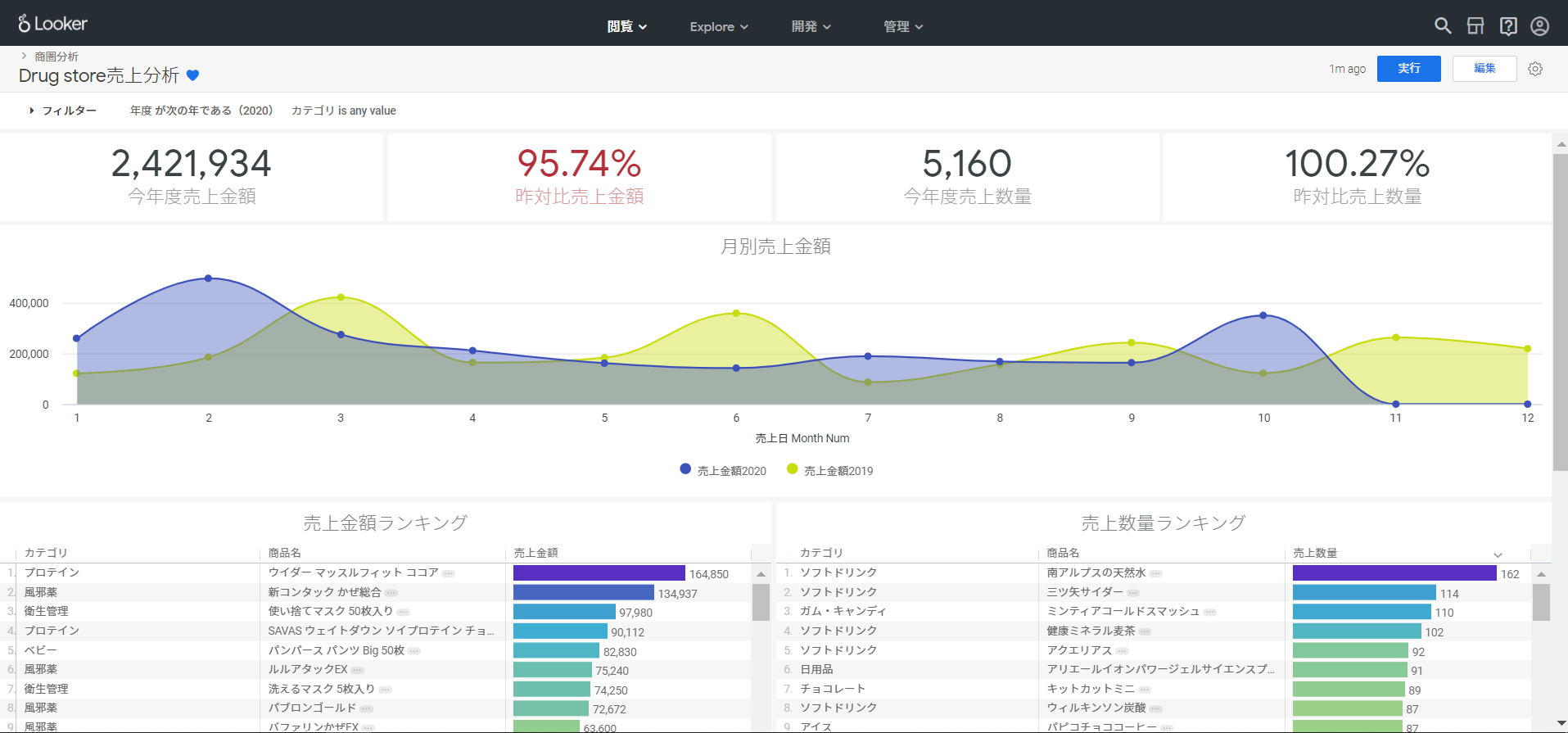
まずデータ(レコードや行)に関する制御です。下記のダッシュボードをご確認ください。
こちらはあるドラッグストアの商圏分析を行っているダッシュボードなのですが、権限の強い「本部ユーザー」の実行結果が下記です。
東京のすべてのエリアのデータを閲覧できています。
次に「東エリア担当ユーザー」の実行結果が下記です。
結果が東京の東エリアに絞られているのが分かるかと思います。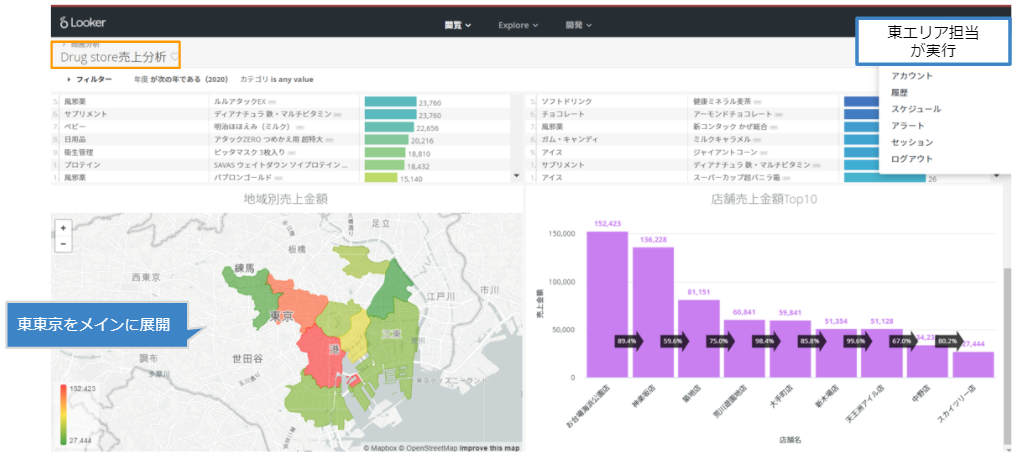
左上に表示されているダッシュボード名のとおり、上記2つは同じ1つのダッシュボードの実行結果でして、実行時に手動でフィルターを設定している訳ではなく権限に応じて動的にフィルターを適用させています。
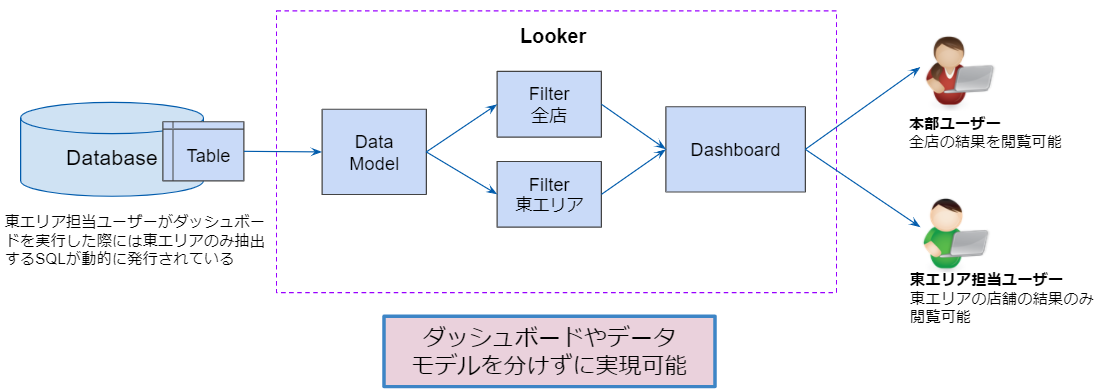
イメージとしては下記のとおりです。
ここでのポイントはダッシュボードやデータモデルを作り分けて実現しているのではなく、 動的に制御している点です。なので開発も管理も楽です。
※ ちなみにLookerは、TopoJsonファイル形式の地図情報を取り込んで表現することが可能なので、お客様の要件に合わせたカスタム・マップの表示ができる点が気に入っています。
そして管理が楽という点を具体的にお伝えしますと、このような設定を下記の画面で一元的に管理できるので変更時のメンテナンスも非常に簡単です。
ビジネス要件に合わせて柔軟に管理を継続させる上で容易性は非常に重要ですよね。
(楽じゃないと継続できないじゃないですか。。)
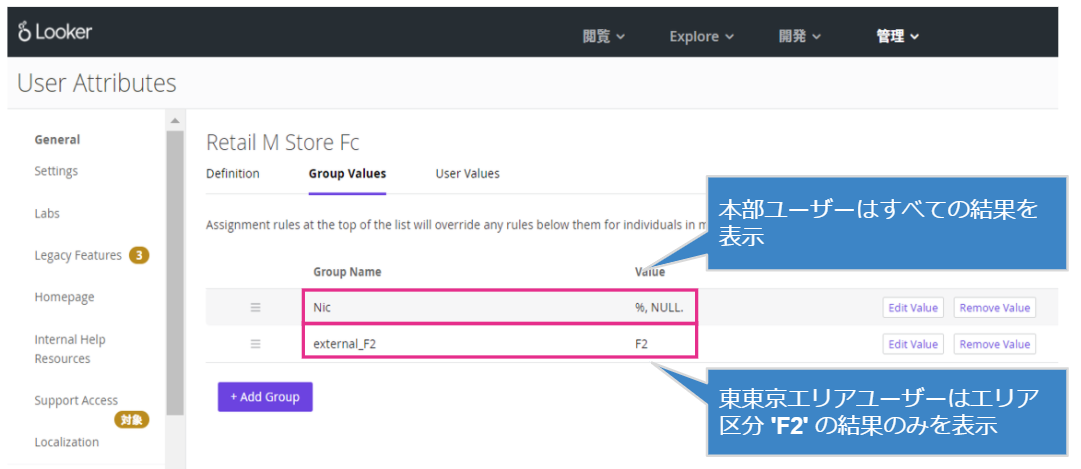
●テーブルや列に関するアクセス制御
先ほどがデータ(レコードや行)の制御でして、次はテーブルや列に関する制御です。
これも画面イメージを見ていただいた方がわかりやすいと思います。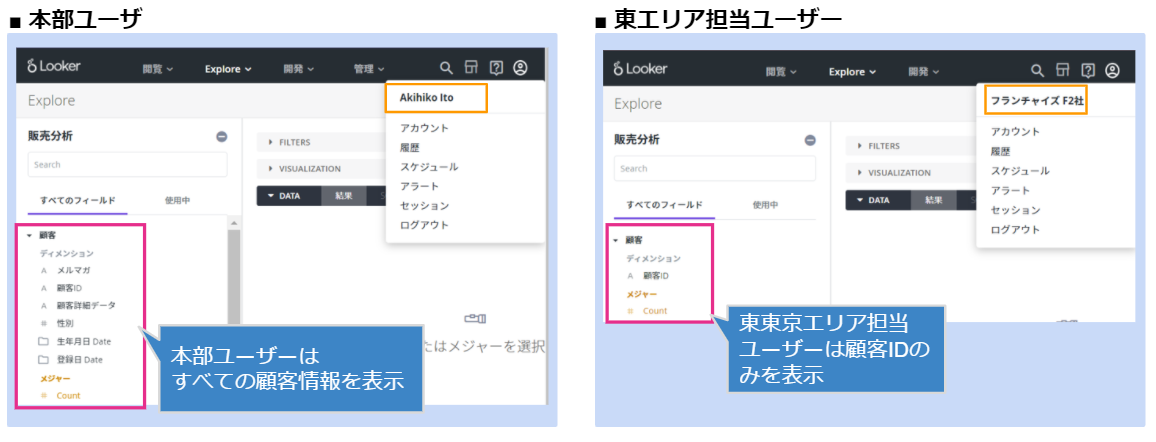
こちらはレポートの結果画面ではなくデータ探索を行う画面でして、本部ユーザはすべての顧客情報にアクセスできるが、東エリア担当ユーザーは「顧客ID」のみ参照可能という形で動的に制御をかけています。
もし東エリア担当ユーザーが顧客情報を含んだレポートを実行したとしても、エラーとせず顧客情報のみを出力させないといった設定も可能です。
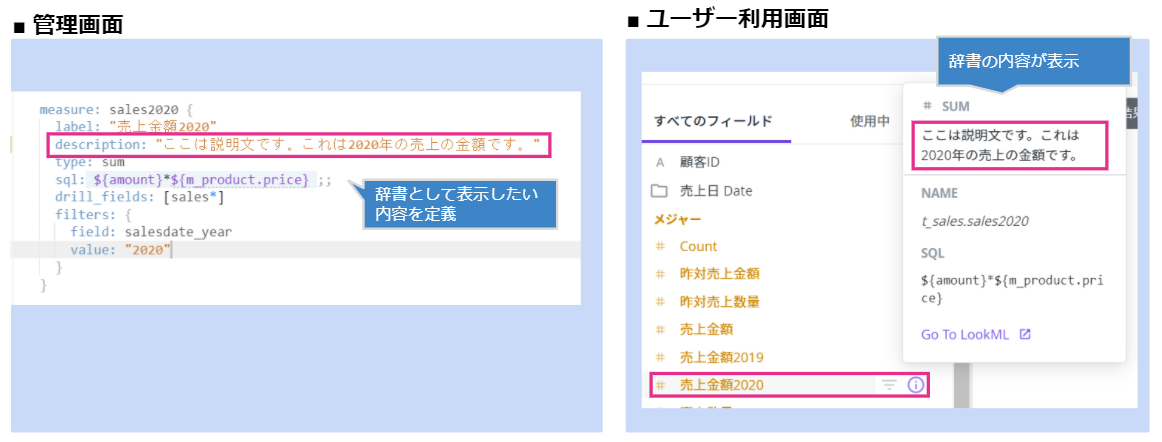
③データカタログ(データの辞書)
最後にデータカタログ(データの辞書)についてです。
見たい指標が増えてしまい○○率みたいなデータ項目が溢れかえってしまうことってよくあると思います。
集中管理で適切に定義してもユーザーが、データ項目を間違えて使ってしまうと意味がないので、各データ項目にわかりやすい説明を付けてユーザーに正しく利用してもらう必要があります。
地味ですがこれもデータガバナンスを行う上で大事ですね。
下記のようなイメージになります。
まとめ
今後データ共有の範囲は社内だけでなく外部に広がりると言われており、早い企業さんはどんどん取り組んでいます。
例えば下記などです。
- ・FC加盟企業と売上状況を柔軟に共有する
- ・取引先企業や会員顧客に売れ筋の商品情報を公開する
このような外部への公開は一般的に「External BI」などと言われていますね。
これまでお伝えしましたように、ただ見れれば良いのではなくデータガバナンスを効かせて、適切な人に適切な形で見てもらう必要があります。
さらに定型のダッシュボードやレポートの提供だけでなく、データ分析をする仕組み(データプラットフォーム)ごと共有して、各自で分析を実施してもらうこともできるようになります。
このようなデータプラットフォームを作りには、データガバナンスの機能が重要になりますね。
以上、データガバナンスについて私の理解を記載させて頂きました。
ありがとうございました。
弊社では12月10日(木)に「DXを成功させるためのデータマネージメント」と題しウェビナーを行います。
弊社からは「DX推進のカギとなるデータプラットフォームとは?」と題しまして、データレイク、データ分析、デジタルマーケティングなどのデータプラットフォーム構築からお客様の運用定着まで、システムの提供実績豊富な弊社がいかにしてDX推進を行いPJを成功裏に導いてきたかLookerの活用事例を交えてお話します。
⇓詳細・お申込みは以下のバナーからお願いいたします。
