


watsonx Assistantからwatson DiscoveryとChatGPTを呼び出してRAGを構築してみた!(Part1)
投稿者:泉
こんにちは!
日本情報通信の泉です。
お客様から社内情報に対して単純にキーワード検索ではなく、生成AIを活用してより高度で示唆に富んだ回答をしてほしいといったようなご相談をよくお伺いします。
この社内情報(生成AIが学習していないデータ)に基づいて生成AIに回答させるために、RAG(Retrieval-Augmented Generation)という方法を利用することができます。
そこで実際にIBM社のチャットアプリであるwatsonx Assistantと検索エンジンのwatson Discovery、OpenAI社の生成AIであるChatGPTを利用して実際にRAGを構築してみようと思います!(2回のTechBlogに分けてご紹介します。)
■RAGとは
RAGとは生成AIが学習していないデータから情報を検索し、回答を生成するAIの自然言語処理の技術のことを指します。RAGには以下のようなメリットがございます。
メリット1:LLMだけでは回答できない情報を得ることができる
専用の知識ベースで検索を実行するため、LLMだけを使った回答よりもより専門的な回答や最新情報を提供することが可能になります。
メリット2:質問の文脈を踏まえた回答を得られる
検索とLLMを組み合わせることで多くの情報源から情報を収集し、文書検索と比較して人間のような自然な回答を生成することができます。
メリット3:モデル学習に必要なデータ準備と作業労力を削減
LLMの追加学習には大量のデータとリソースが必要ですが、RAGは自社ドキュメント/自社データが利用可能なためモデルへ学習データを取り込む必要がなく、労力やリソースが削減できます。
■RAGの構成図と質問から応答が返ってくるまでの流れ
今回構築するRAGの構成図は以下の通りになります。
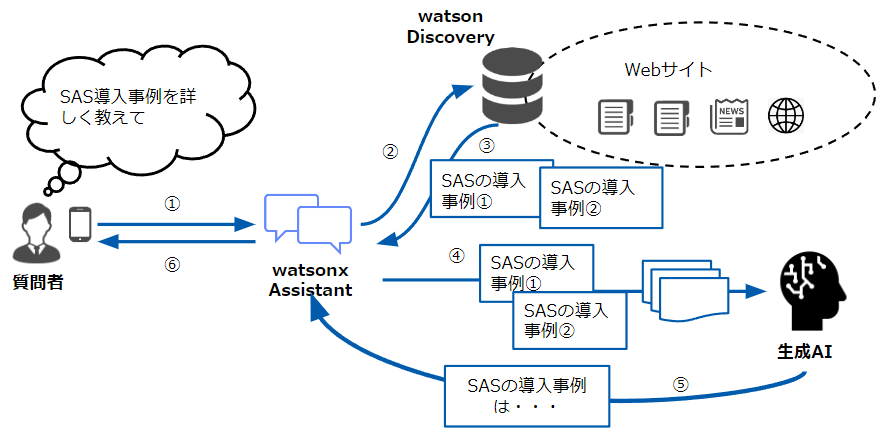
質問から応答が返ってくるまでの流れは以下の通りとなります。
※今回は弊社HPのSAS導入事例について質問してみます。
※SASとはSAS社が提供する統計解析や機械学習&AIが利用可能なデータ分析ソリューションです。
①弊社HPのSAS導入事例についてwatsonx Assistantに質問を入力
②入力した質問を元にwatson DiscoveryにクロールしているSAS導入事例の情報を抽出
③SAS導入事例の情報をwatsonx Assistantに連携
④watsonx AssistantがSAS導入事例の情報とプロンプト(生成AIに出す命令文)をChatGPTに連携
⑤ChatGPTが導入事例の情報とプロンプトを元に回答を生成し、watsonx Assistantに連携
⑥watsonx Assistantで出力された内容を見て、質問者がSAS導入事例について把握
■構築手順
それでは早速RAGを構築していこうと思います!
今回はRAGを構築する上で以下の作業が必要になります。
※本TechBlogでは作業内容の手順3までを実施します。
1.ChatGPTのAPIkey発行
2.watson Discoveryで弊社HPの情報をクロール
3.watson DiscoveryのProject id・APIkey・URLの取得
4.watsonx Assistantの環境作成
5.watsonx AssistantからChatGPTへの接続設定
6.watsonx Assistantからwatson Discoveryへの接続設定
7.watsonx Assistantのアクション設定
1.ChatGPTのAPIkey発行
ChatGPT側の作業としてAPIkeyを発行する必要が有ります。
APIkeyを発行するためにChatGPTにログイン後、”SETTINGS”→”Your profile”からAPIkeyを発行します。
※後の手順で使用するためメモします。
※予めChatGPTのアカウントを作成しておく必要が有ります。
2.watson Discoveryで弊社HPの情報をクロール
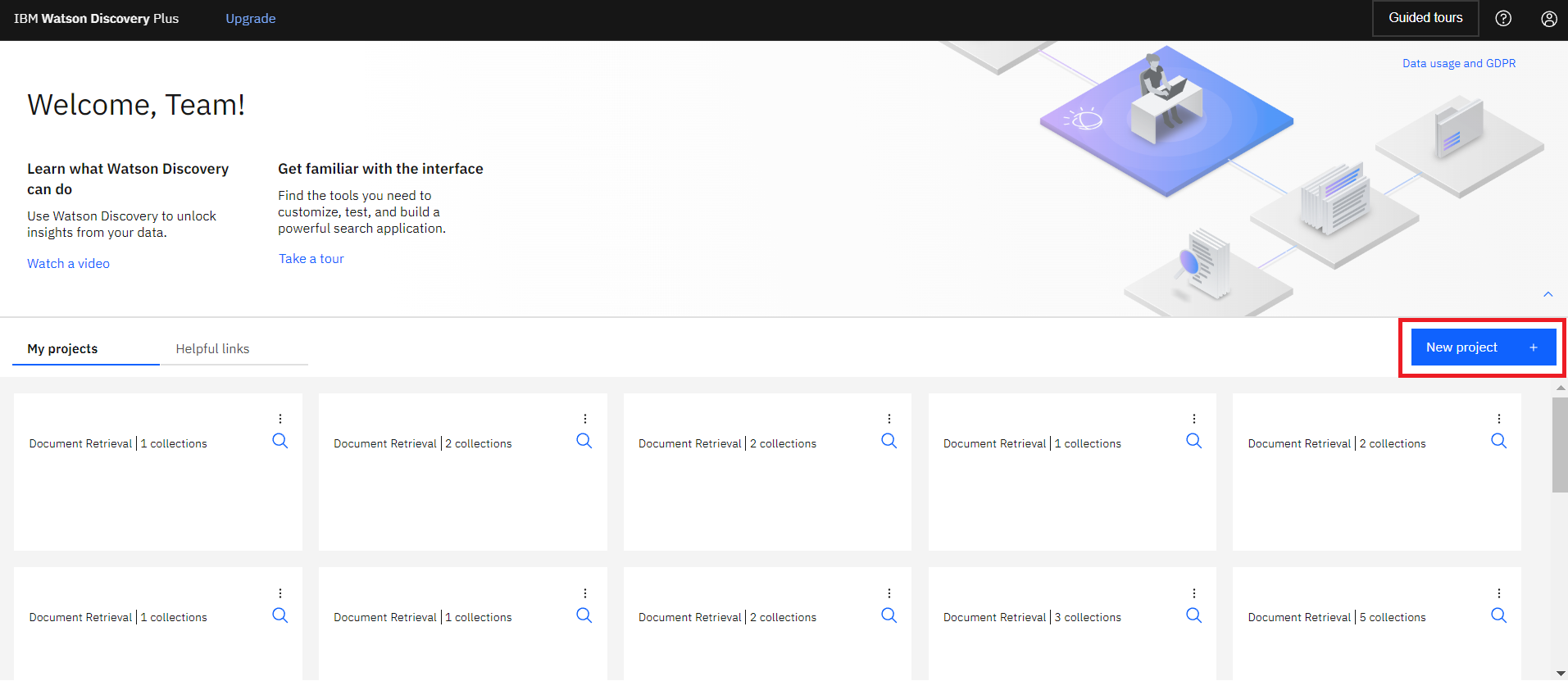
watson Discoveryにログインし、ホーム画面の右側にある”New project”から新規にプロジェクトを作成します。
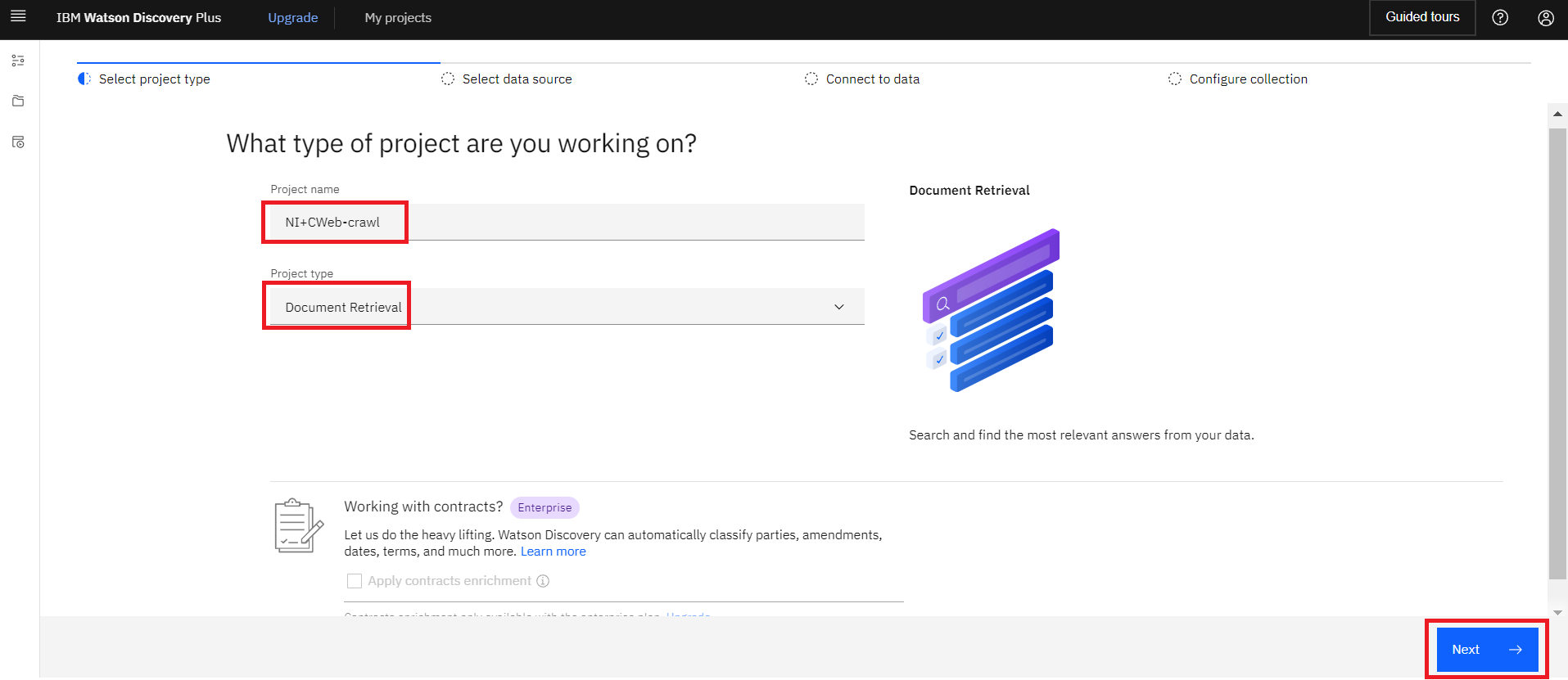
次に”Project name”とProject type”を指定し、右下のNextをクリックします。
・Project name:NI+CWeb-crawl
・Project type:Document Retrieval
下にスクロールすると”Need to connect to a data source? Click here.”とあるので”here”をクリックします。
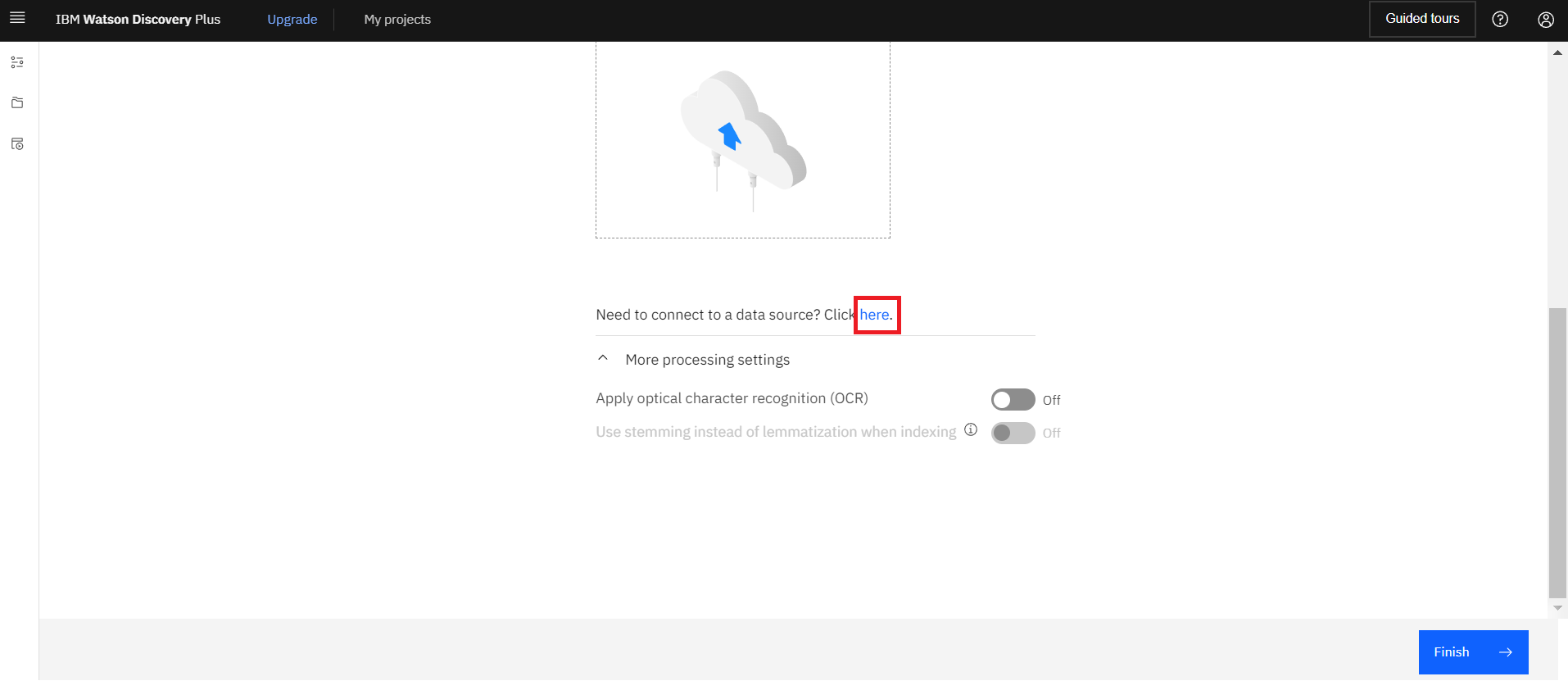
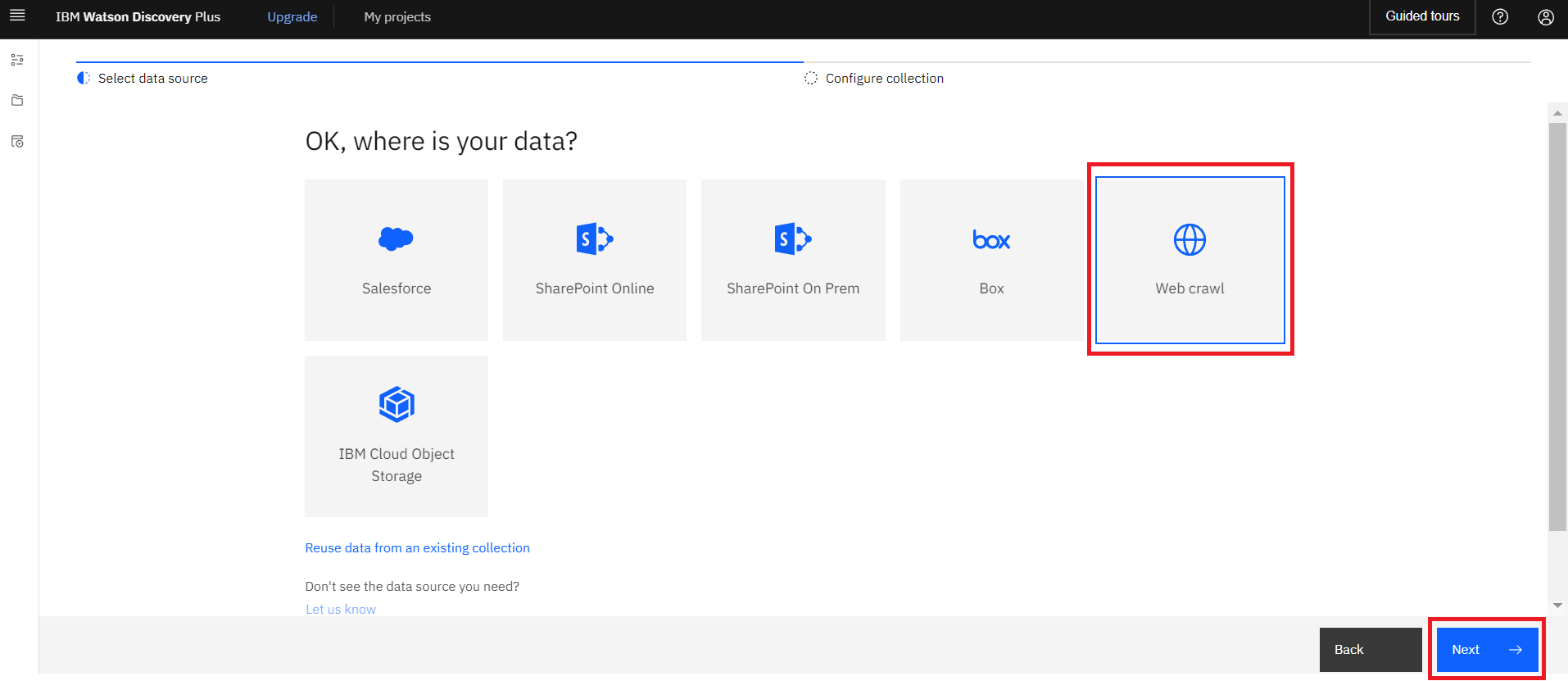
“Web crawl”を選択し、右下の”Next”をクリックします。
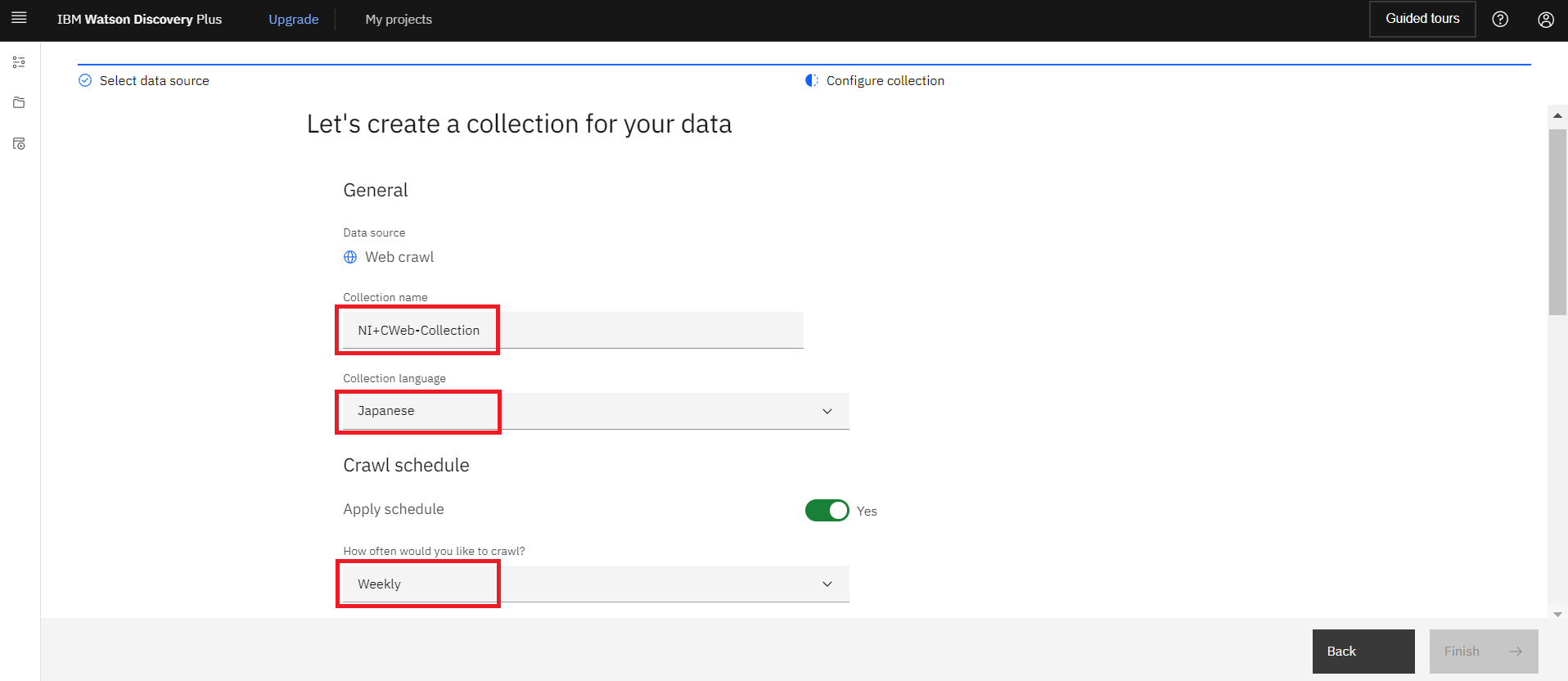
“Collection name”と”Collection language”からコレクション名と使用言語を指定します。
・Collection name:NI+CWeb-Collection
・Project type:Japanese
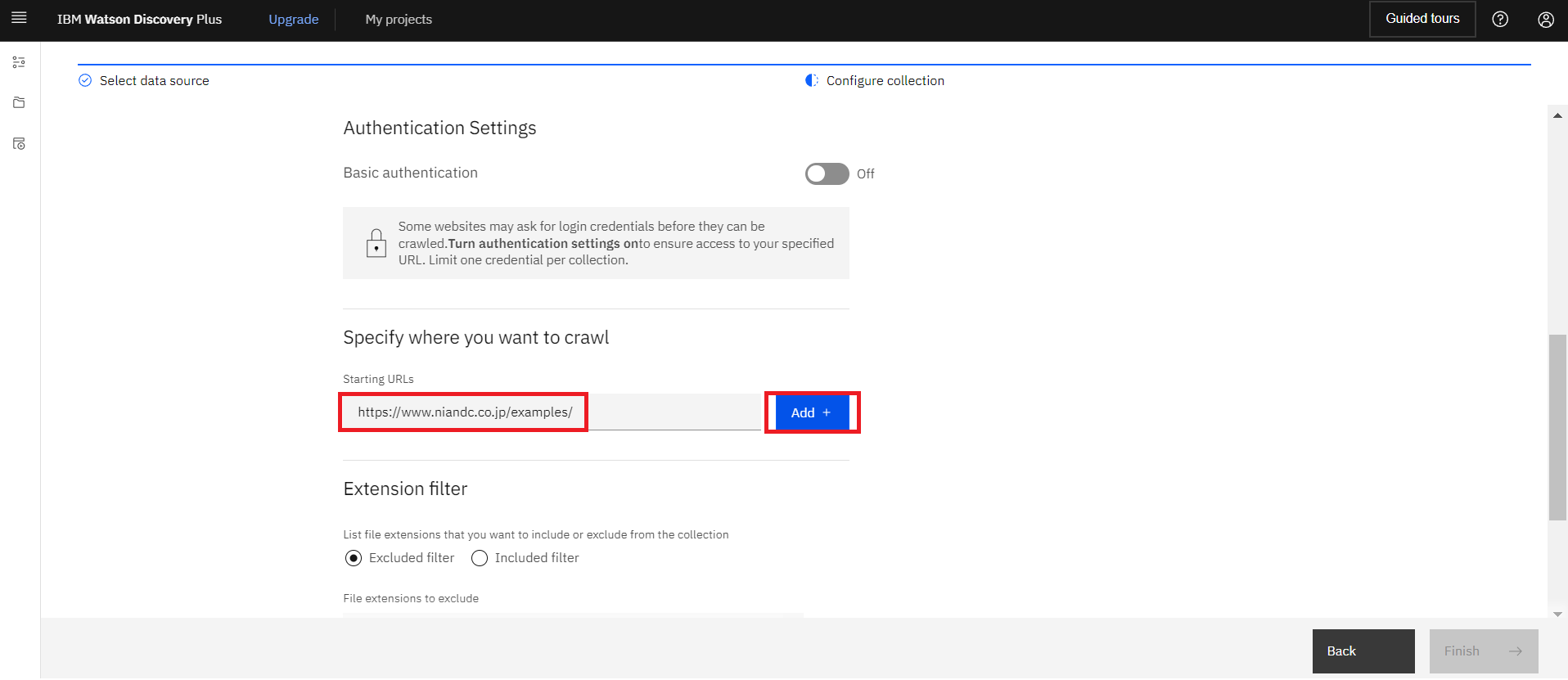
下にスクロールするとStarting URLsがあるので、クロールするWebサイトのURLを貼り付けて”Add”をクリックします。
※今回クロールするURLはこちらになります。
URLが追加されていることを確認し、画面右下の”Finish”をクリックします。
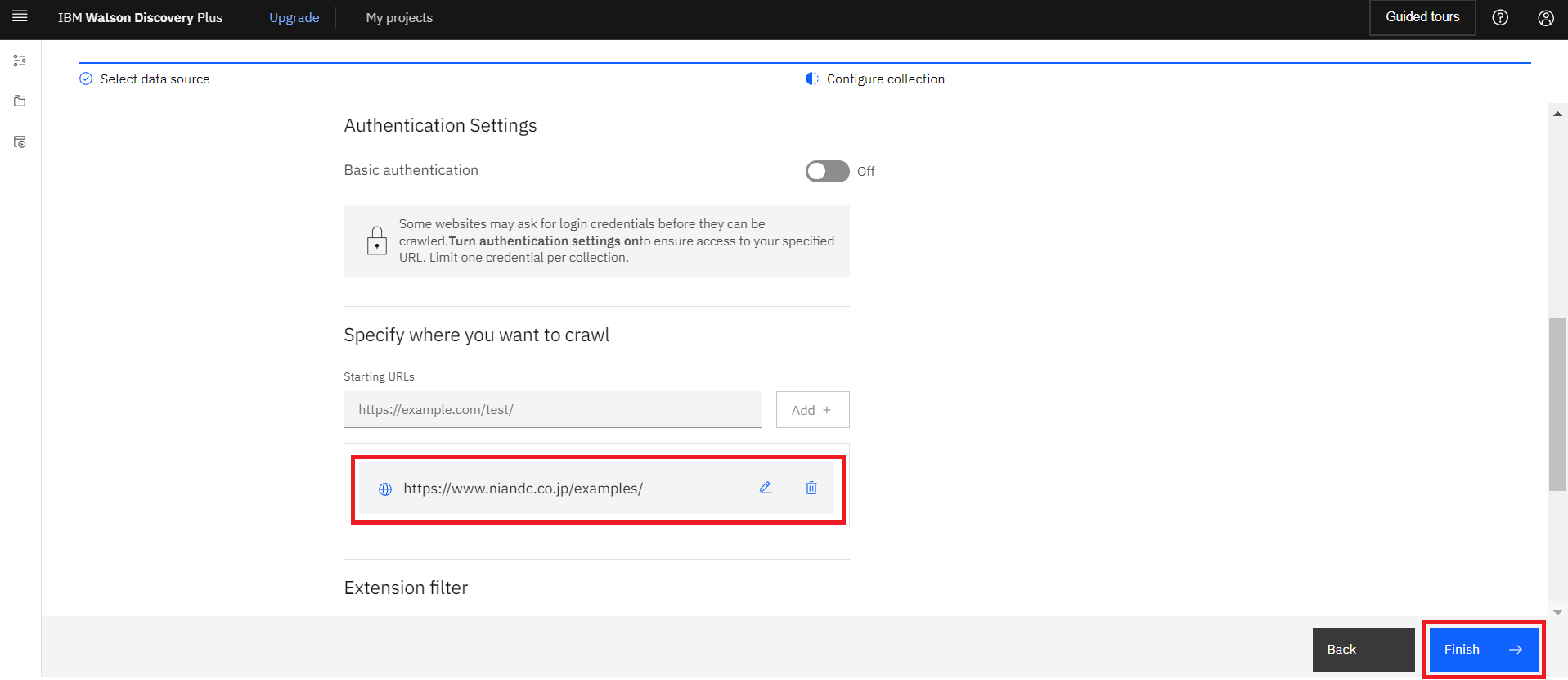
Finishをクリック後、すぐにWebサイトのクロールが始まります。
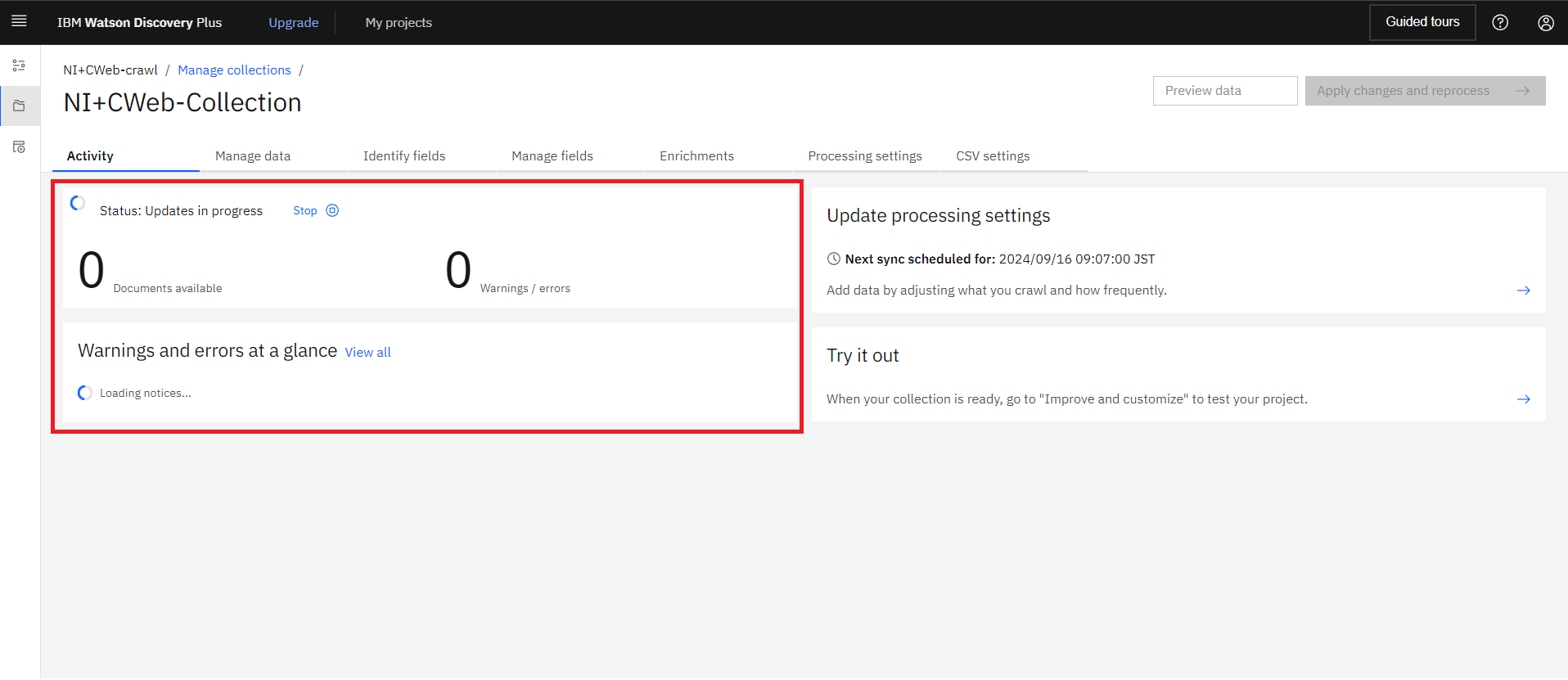
クロールが実行されるとDocuments availableにクロールされたドキュメント数が表示されていきます。
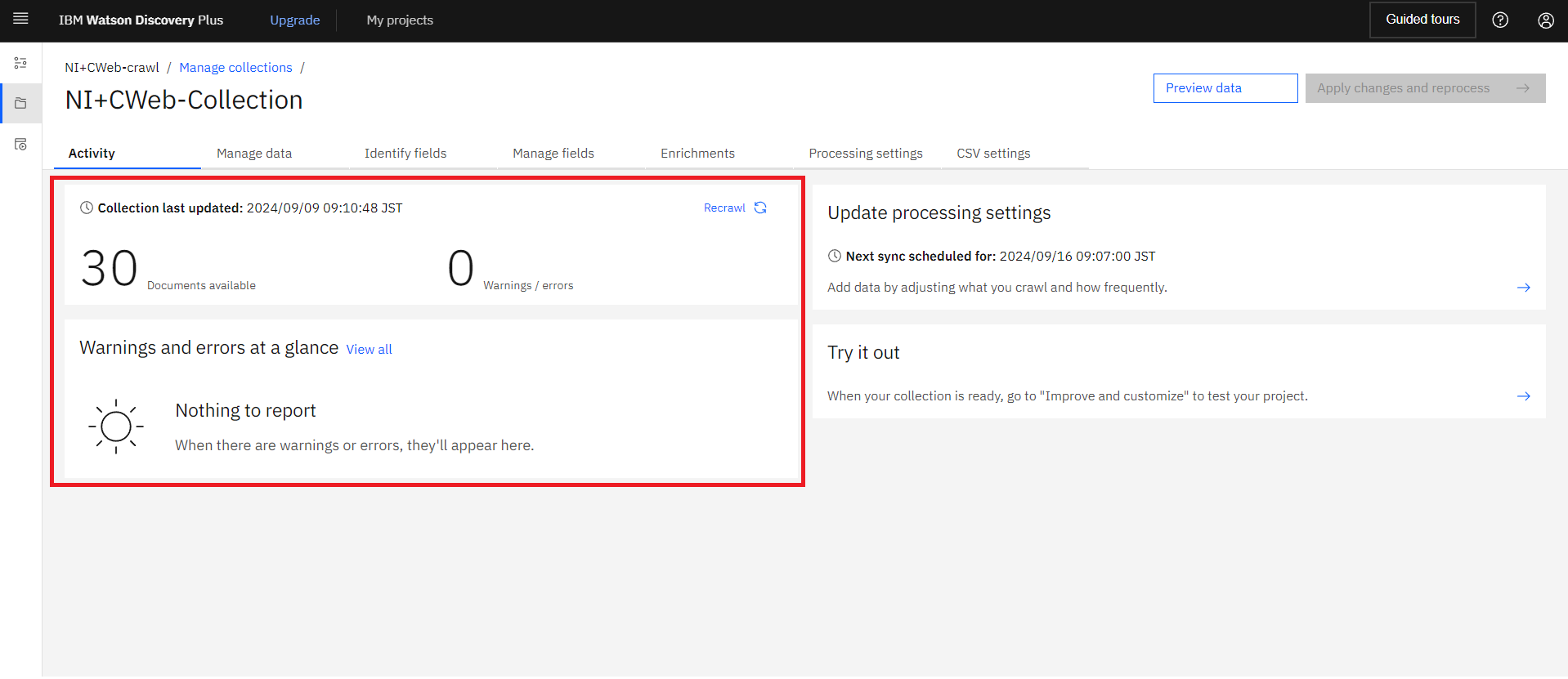
3.watson DiscoveryのProject id・APIkey・URLの取得
クロールが完了したらナビゲートメニュー”Integrate and deploy”の”API Information”からwatson DiscoveryのProject idをメモします。
※後の手順で使用するためメモします。

次にwatson DiscoveryのAPI keyとURLを取得するためにIBM Cloudにログインします。
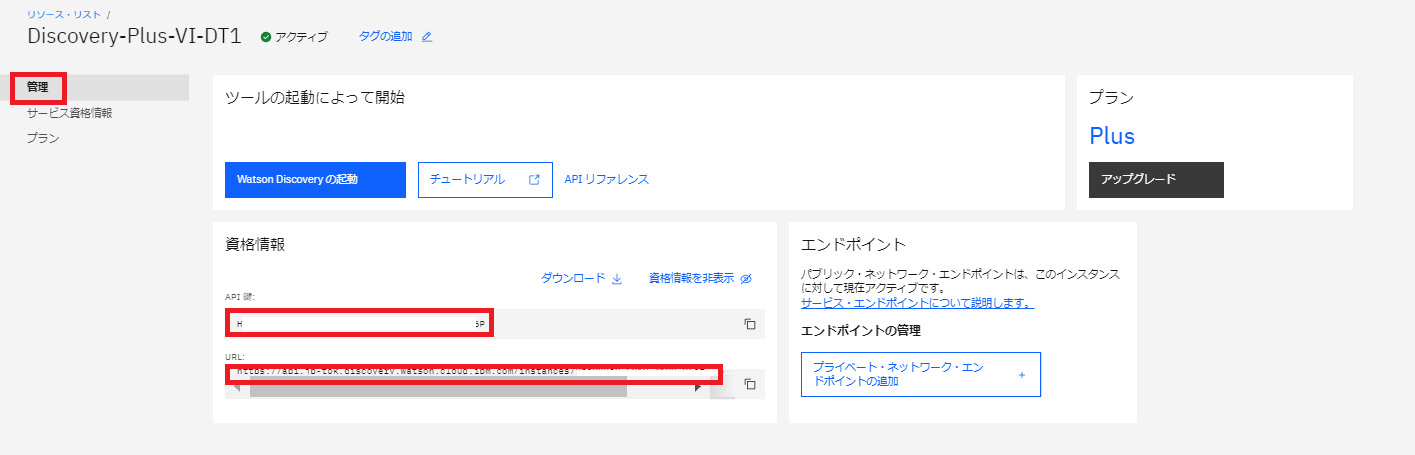
ログイン後、”リソースリスト”の”AI/機械学習”から対象のwatson Discoveryをクリックします。
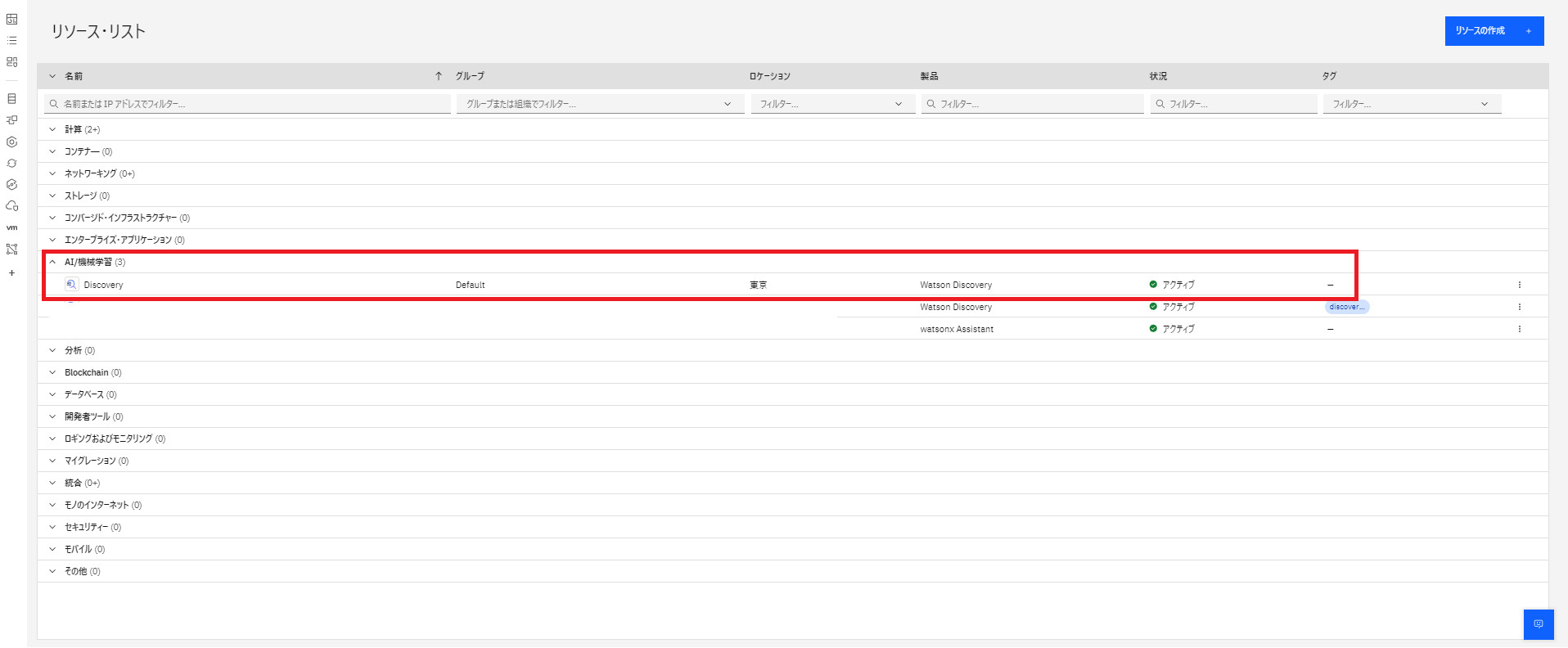
管理画面にAPI keyとURLが表示されているのでメモしておきます。
※URLのhttps://は必要ないので省いてメモします。
ChatGPTとwatson Discovery側での作業は以上となります!
次回のTechBlogでwatsonx Assistant側の構築作業(手順4以降)をご紹介します。
次回は10月に公開予定ですので是非ご覧いただけると幸いです。
ご覧いただき、ありがとうございました!