


生成AI時代のDX化を支えるデータレイクハウス「IBM watsonx.data」について調べてみた
投稿者:watsonx.data担当
はじめまして、NI+CのIBM watsonx.data担当の田原です
次世代のDX基盤データレイクハウス「IBM watsonx.data(※)」について、まとめさせていただきます。
※以後、watsonx.dataと記します。
もくじ
- そもそも「データレイクハウス」とは?
- データレイクハウスの特徴
- なぜデータレイクハウスを利用するのか?
- watsonx.dataとは?
- watsonx.dataの利用例
- まとめ
そもそも「データレイクハウス」とは?
近年、データ基盤はクラウドやオンプレミスといった異なるロケーションや、データベース、データウェアハウス、データレイクなど多種多様な形態が存在します。
しかしながら、これらはアプリケーション要件による最適なデータ管理方式が採択されるため、企業が持つデータのサイロ化が進んでしまい、データの所在を把握できない、データが十分に活用しきれない、基盤の管理コストが増加するといった問題が発生します。
そこで、上記の問題を解消するために注目されているデータ統合のアプローチが「データレイクハウス」です。
「データレイクハウス」は、「データレイク」と「データウェアハウス」の強みを組み合わせた基盤となっています。
表1

データレイクハウスの特徴
1.多種多様なデータフォーマットをサポート
データウェアハウスは、主にブロックストレージを採用しており、テーブル形式で構造化データを管理するためのシステムでした。
しかし、データレイクハウスは、データレイクと同様にユニークIDによりデータ種別を区別しない管理方式を採用してるため、構造化データに加えて画像や動画といった非構造化データも一元的に管理することができます。
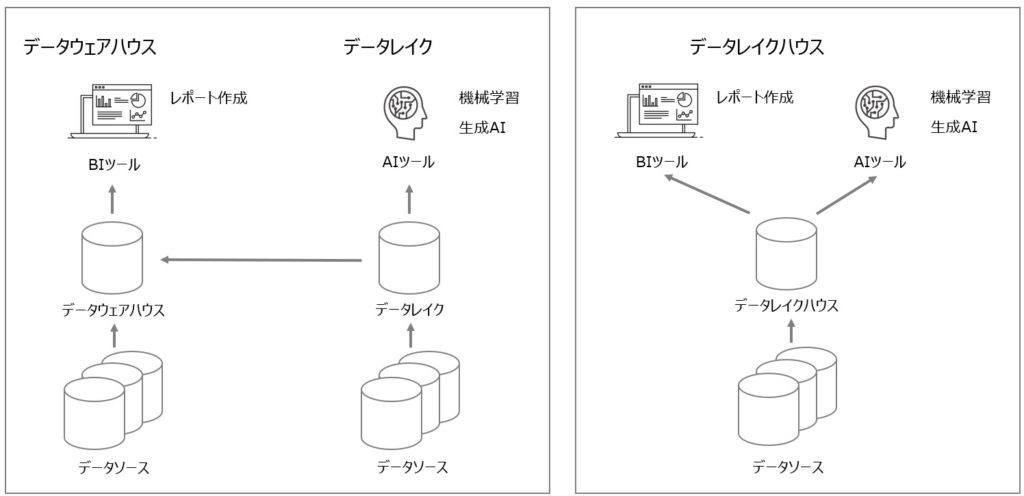
図1
2.データの一貫性
データレイクはACIDトランザクションに対応しておらず、データの一貫性を維持することが難しい点が課題となっていました。
しかし、データレイクハウスでは「オープンテーブルフォーマット」を採用することで、この課題を解決しています。
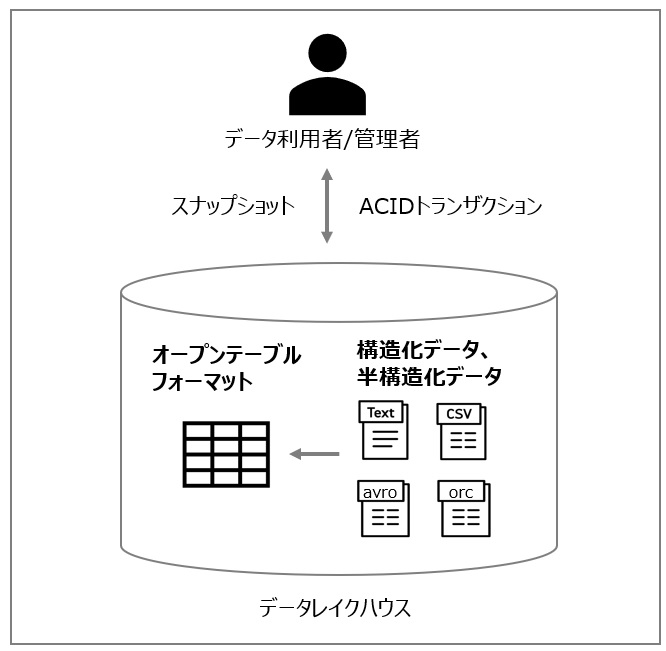
図2
データレイクハウス上のオブジェクトストレージにて、構造化データ / 半構造化データ(※1)を保存できます。
格納された構造化データ / 半構造化データを「Iceberg」、「Delta Lake」といったオープンテーブルフォーマットと呼ばれる形式で管理することで、各レコードの更新や削除、追加にも対応できるようになっています。
そのため、データレイクでは課題となっていたACIDトランザクションやスナップショット(※2)などの機能が利用できるようになりました。
オープンテーブルフォーマットは、例えばcsvやAvro、ORCといった形式のファイルに対応し、カラム指向のデータ管理を行います。
(※1) 半構造化データ:
データの形式が完全に規則化はされていないですが、ある程度の構造を持ち、タグ付けがされているデータを指します。例としてはXMLファイルやJSONファイルとなります。
(※2) スナップショット:
データの一時点での状態を記憶する機能です。例えば、誤って重要なデータを上書きしてしまった際に、スナップショットを取得した時点の状態にデータを戻すことができます。
3.コスト効率
増え続けるデータをオンプレミスやクラウドのブロックストレージから、データレイクのストレージ層として採用されているオブジェクトストレージに移行することで、コストを低減することが可能です。
オブジェクトストレージは様々な種類のデータを管理できるため、データウェアハウスやデータレイクで管理されていたデータをデータレイクハウスのオブジェクトストレージに統合することで、既存のデータを一元管理することができます。
その結果、データ管理者の負担を減らすことにもつながり、コスト効率を高めます。
なぜデータレイクハウスを利用するのか?
冒頭でも述べてさせていただきましたが、アプリケーション要件による最適なデータ管理方式が採択されるため、データのサイロ化が進んでいる企業が増えています。
データレイクハウスを導入することで、既存のデータをデータレイクハウス上に統合または仮想化(図3)し、社内のデータを横断的に管理できるようになります。
これにより、基盤コストの削減やサイロ化の解消が可能となり、分析ツールや生成AIの利活用に向けたインフラを整えることができます。
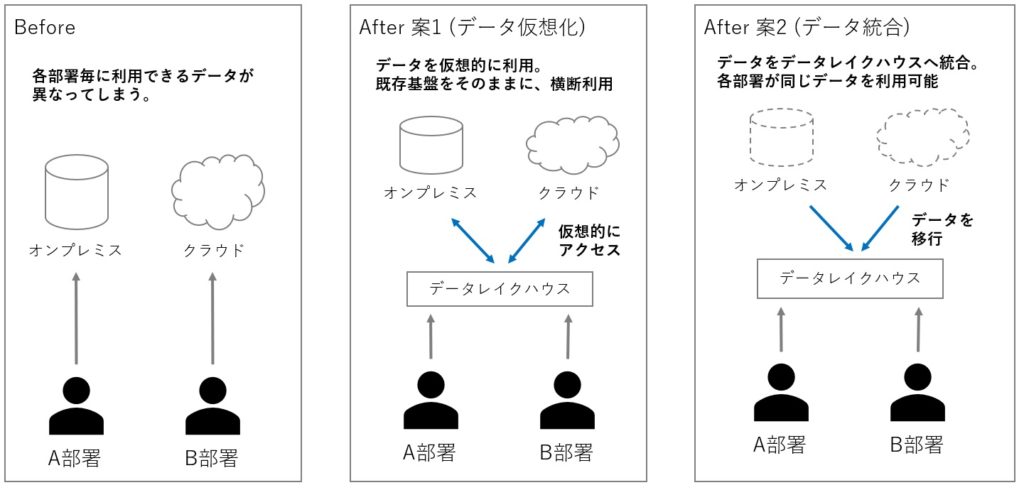
図3
データレイクハウスを実現するソリューションはいくつか存在しておりますが、このブログでは
「watsonx.data」をベースに説明していきます。
watsonx.dataとは?
IBMは生成AI時代へのアプローチとして、watsonxシリーズ「watsonx.data」、「watsonx.ai」、「watsonx.governance」をリリースしています。
その中で、生成AIとデータをシームレスに繋ぐデータレイクハウスを構成する製品が「watsonx.data」となります。
watsonx.dataは前述のデータレイクハウスの基本機能に加えて、次のような特徴を備えています。
1.IBM watsonxシリーズ製品との連動
watsonx.dataは、watsonx.ai、watsonx.governanceと連動することで、生成AIの利活用に必要となる基盤をパッケージ化された形で提供し、生成AIの利用を補助・促進します。
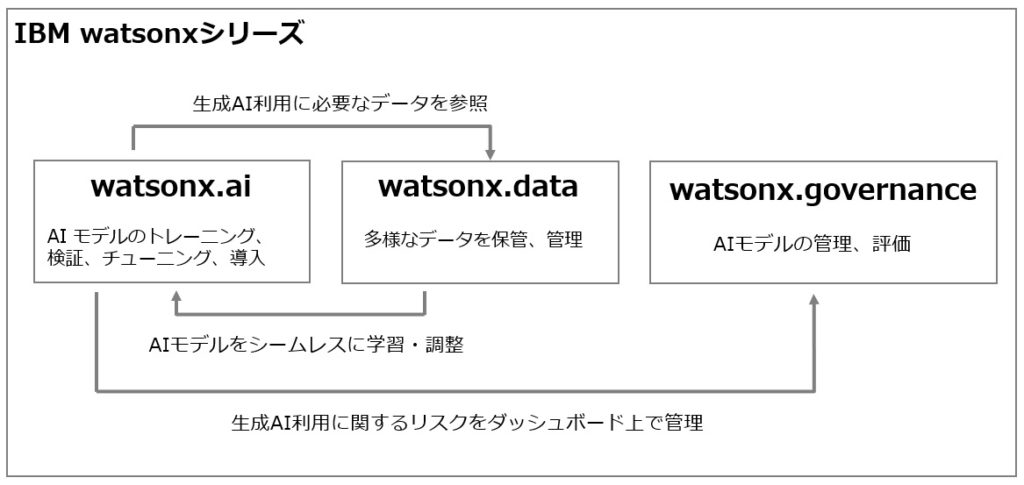
図4
2.VectorDB の包含
watsonx.dataは、VectorDB(※3)製品であるMilvusを含んでおり、生成AIと組み合わせによってRAG(※4) 構成を実現できます。
これにより、データの統合から生成AIの利活用までを一挙に実施できます。
生成AIの利用における大きな課題であるハルシネーション(事実に基づかない情報を生成する現象)を防ぐ対策にもなり、生成AIを利用する際の回答の信頼性を高めるアプローチとなります。
(※3) VectorDBは、テキスト形式のデータだけではなく、画像や音声といった非構造化データを対象に類似度検索を可能とするデータベースです。
(※4) RAGは生成AIにおける検索対象を拡張するフレームワークです。例えば、生成AIの回答を自社データを交えた形にすることなどができます。
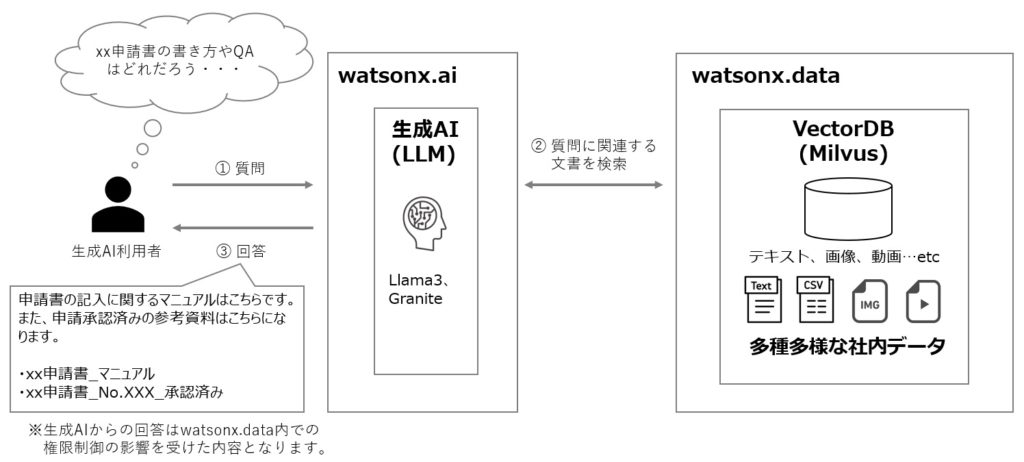
図5
3.柔軟なクエリエンジンの選択
大規模データへのクエリ処理をサポートするPrestoやSparkを使用でき、多種多様なBIツールや分析ツールと親和性を持ちます。
ユーザーは、データレイクハウス上に統合したデータを用いて既存の分析フローを即座に実行できます。
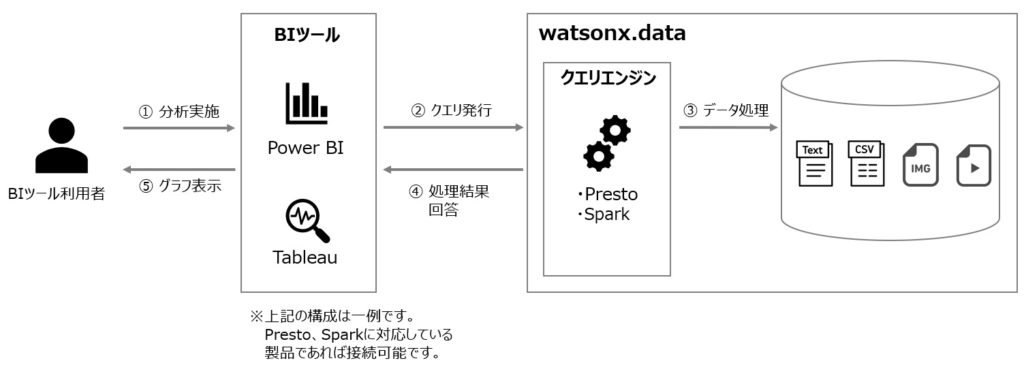
図6
4.データへのアクセス制御
データレイクハウス上では、アクセス権限の制御を通じてデータガバナンスを実現します。
これにより、管理者はテーブル単位やユーザー単位など、細かいレベルで大規模なデータへのアクセスを制御することができます。
また、生成AIはデータに付与されている権限の影響を受けた形でデータを扱います。
watsonx.dataの利用例
- 多種多様なデータフォーマットをサポート
ファイルの種類を問わず、利活用が可能になります。 - データの一貫性を維持
データレイクでは一貫性維持の観点から管理できなかった構造化データをデータレイクハウス上では管理できるようになります。 - コスト効率
バイト当たりの単価の安いオブジェクトストレージに保管可能になります。
また、オブジェクトストレージに集約して一元管理することで管理コストも削減可能です。
上記を踏まえ、以下のような利用例が挙げられます。
- データウェアハウス、データレイク基盤の横断分析
既存のデータウェアハウスやデータレイクをデータレイクハウス上に統合し、社内データを横断して分析。 - 既存基盤の管理・運用コスト削減
オンプレミスやクラウド上に存在する社内データを、watsonx.data(データレイクハウス)に統合することで、既存の基盤を縮小または撤去することができるようになり、既存基盤の管理・運用コストを削減。 - VectorDBの利用
RAGを活用した生成AIによる社内文書の検索。またはご利用中の生成AIにおける検索精度・信頼性の向上。
記載の製品/サービス名称、社名、ロゴマークなどは、該当する各社・団体の商標または登録商標です。
まとめ
今回、改めてデータレイクハウスについて整理して思ったことをまとめます。
- 保持するデータ量が増えることによってデータがサイロ化している企業にはデータ統合の観点で最適なソリューションと考えています。
watsonx.dataにおける統合化の強みは、データの管理を一元化できるだけでなく、OSSのクエリエンジンであるPrestoを採用していることから、他製品と組み合わせることが可能という拡張性も強みであると考えているためです。 - 生成AIの利用を始めようとしている方にこそ、AI製品と社内のデータをシームレスに連携させることが可能なwatsonx.dataが適しているのではないかと考えています。
環境の準備に手間をかけず、社内データを利用する形で生成AIを業務に適用すること(またはPoCの実施)が可能なためです。
- 上記のことから、中長期的に社内データの持ち方の見直しを考えている方はwatsonx.dataが自社システムに適する製品なのか一度ご検討ください。
なぜなら、自社データ基盤の統合後、watsonx.dataを既存システムと連動させることで、データ利活用の幅が一気に広がるため、各企業に適した新たなデータ基盤の在り方を見つけられると思われるためとなります。
生成AIの利活用において、RAGに興味を持たれている方々はたくさんいらっしゃると思いますので、次号ではデータレイクハウスにおけるVectorDB(Milvus)を軸に、RAGについて少し踏み込んだ内容を記載しようと考えています。お楽しみに!!!