


Amazon Redshift ML を使って機械学習モデルを作成してみた
投稿者:NI+C 池田
こんにちは、NI+C AWSチームの池田です。
今回は2020年頃に発表された Amazon Redshift ML というサービスを使って、機械学習モデルを作成するまでの一連の流れを解説します。
AWSにおける機械学習といえば、多くの方が SageMaker を思い浮かべるかと思いますが Redshift ML はご存じでない方もいらっしゃるかもしれません。
このブログでは、まず Redshift ML の特徴やユースケースを紹介し、後半では実際にモデルを作成する手順をご紹介します。
目次
1. Amazon Redshift MLとは
Amazon Redshift MLは、AWSのデータウェアハウスサービスであるAmazon Redshiftの機能拡張で、機械学習モデルを簡単に作成およびデプロイできるプラットフォームです。
特徴として、SQLを使用することでデータをRedshift内に保持したままモデルを構築できます。
また、AutoML(自動機械学習)機能も利用でき、モデルの自動トレーニングが可能です。
これにより、データ移動や外部ツールの必要性が減り、プロセスが大幅に効率化されます。
またRedshift MLは、Amazon SageMakerと連携して動作します。
Redshift内のデータをそのまま使用してSageMakerでトレーニングされたモデルをデプロイできるため、SQLだけで強力な機械学習モデルを作成できます。
2. SageMakerとの比較
Amazon Redshift MLとAmazon SageMakerは、どちらもAWSの機械学習サービスですが、それぞれ異なる特徴を持っています。以下にそれぞれの特徴や適用例を示します。
Redshift ML
特徴
SQLを使用して簡単に機械学習モデルを作成・デプロイ
データをRedshift内に保持したまま機械学習が可能
主にデータ分析と機械学習の統合を重視
適用例
データウェアハウス内のデータを直接使用する予測分析
Redshiftのデータを活用したリアルタイムなビジネスインサイトの提供
SQLを駆使したデータ分析と機械学習の統合
SageMaker
特徴
機械学習のエンドツーエンドのサービス(データ準備、トレーニング、チューニング、デプロイまで一貫して対応)
各種機械学習アルゴリズムやフレームワーク(TensorFlow、PyTorchなど)のサポート
カスタムモデルの作成・トレーニングが容易
適用例
大規模データセットを使用した高度な機械学習モデルのトレーニング
カスタムアルゴリズムを使用した専門的なモデル開発
フルマネージドのMLパイプラインの構築と運用
利用する際は、その用途や対象者によってどのサービスを利用するか検討が必要になります。
Redshift MLは、既存のRedshift環境とSQLベースのワークフローを活用したい場合や、データ分析と機械学習を統合して迅速に結果を得たい場合に適しています。
一方、SageMakerは、複雑でカスタマイズ可能な機械学習モデルの開発や、大規模データセットのトレーニングを行いたい場合に適しています。
3. 環境構築手順
ここからは実際にRedshift MLを使ってモデルを作成する手順をご紹介します。
● IAMロール作成
まず、Redshift MLを使用するために必要なIAMロールを作成します。
AWSマネジメントコンソールから「IAM > ロール」にアクセスし、「ロールを作成」をクリックします。
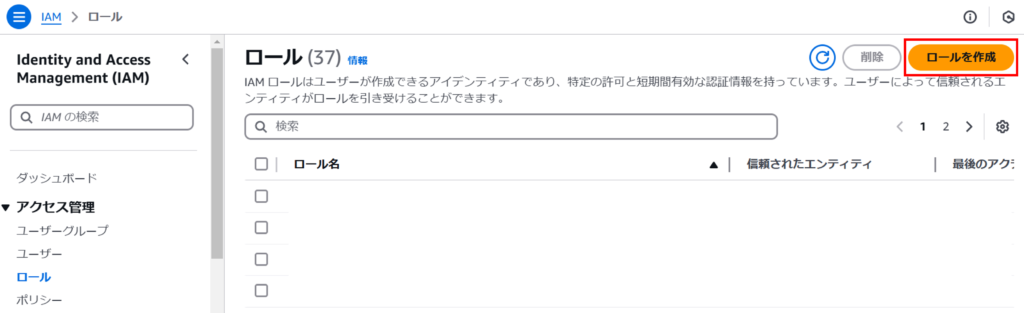
ステップ1では信頼されたエンティティタイプから「カスタム信頼ポリシー」を選択します。
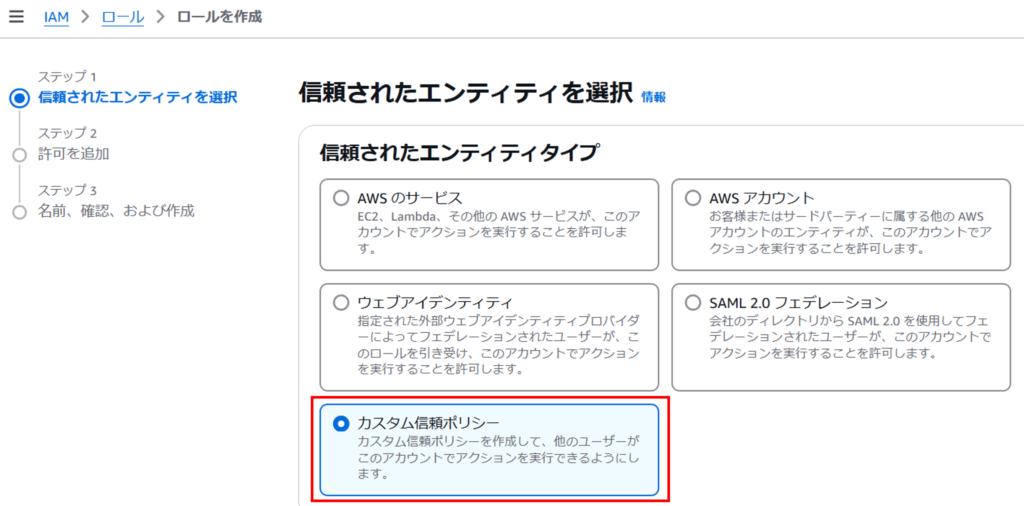
カスタム信頼ポリシーに以下を入力して、「次へ」を押下します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": [
"sagemaker.amazonaws.com",
"redshift.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
]
}
ステップ2の「許可を追加」では何もせず「次へ」を押下します。
ステップ3ではロール名を設定し(例:AWSRedshiftMLRole)、これまでの内容を確認して「ロールを作成」を押下します。

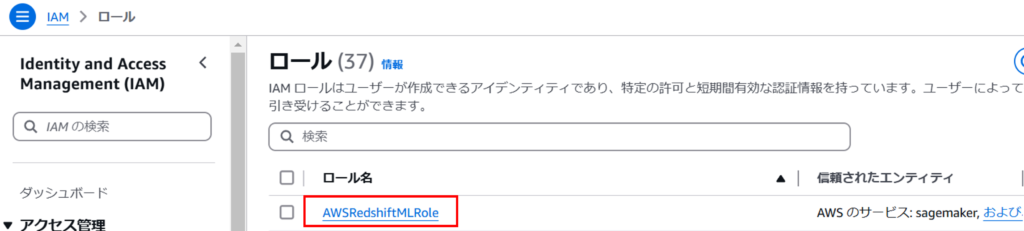
ロールが作成されたことを確認し、再度ロール名を押下します。
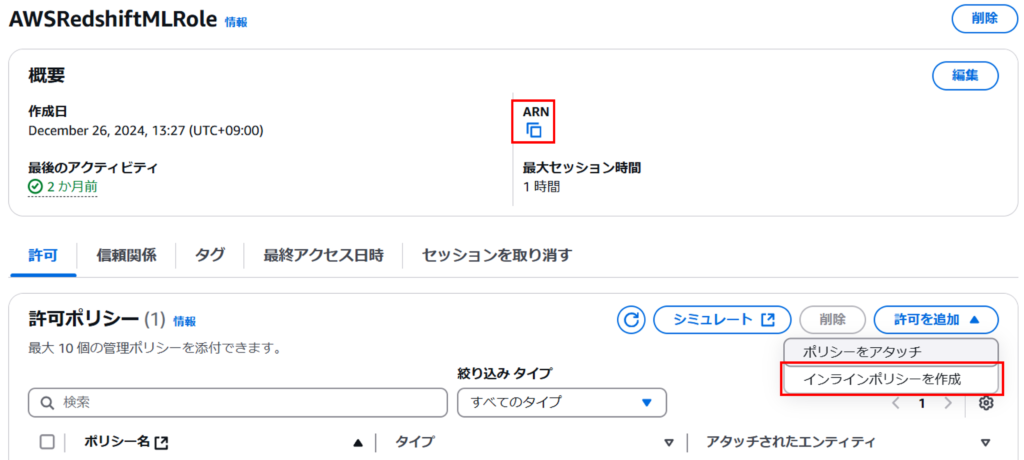
「許可を追加」を押下し、「インラインポリシーを作成」を押下します。
また、ここでIAMロールのARNをコピーしておきます。
ポリシーエディタに以下を入力して「次へ」を押下します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "sagemaker:*Job*",
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject"
],
"Resource": [
"*"
]
},
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "<作成したIAMロールのARN>"
}
]
}
ポリシー名を設定し(例:AWSRedshiftMLPolicy)、これまでの内容を確認して「ポリシーの作成」を押下します。
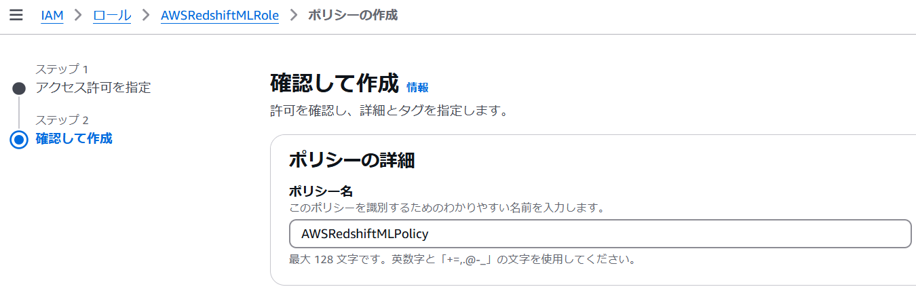
以上でIAMロールの作成は完了です。
● クラスター作成
次にRedshiftのクラスターを作成します。
すでにクラスターが作成済みの場合は、こちらの手順のみ実施し「機械学習モデル作成手順」に進んでください。
AWSマネジメントコンソールから「Redshift > クラスター」にアクセスし、「クラスターを作成」をクリックします。
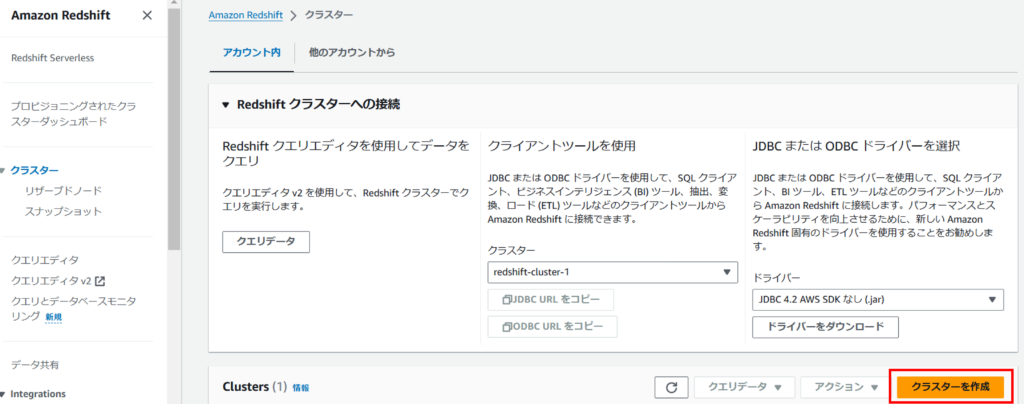
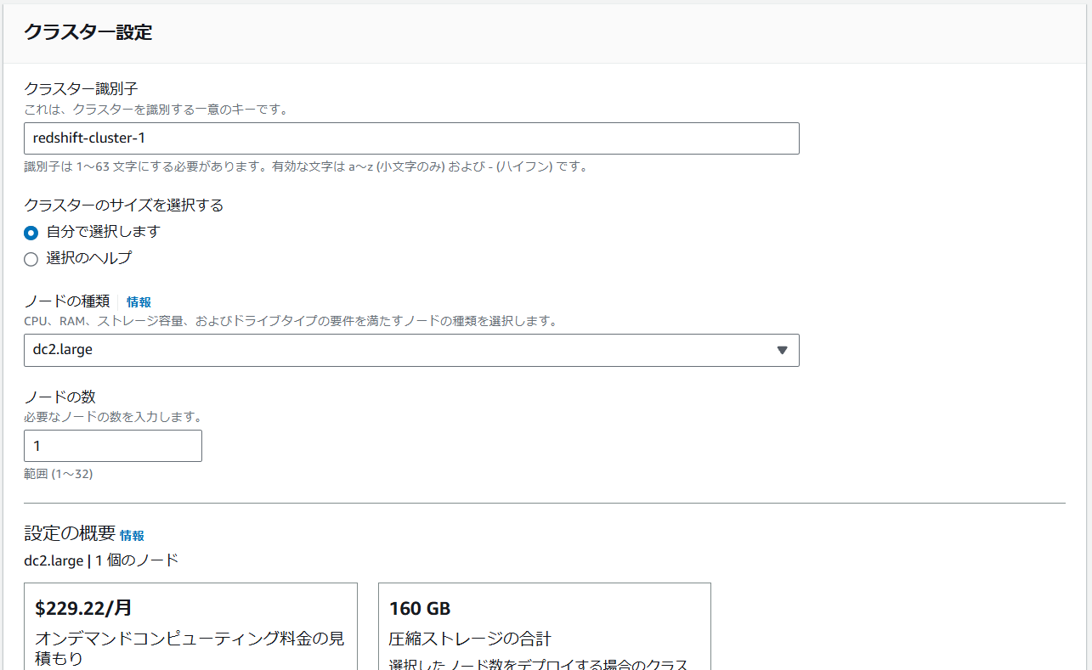
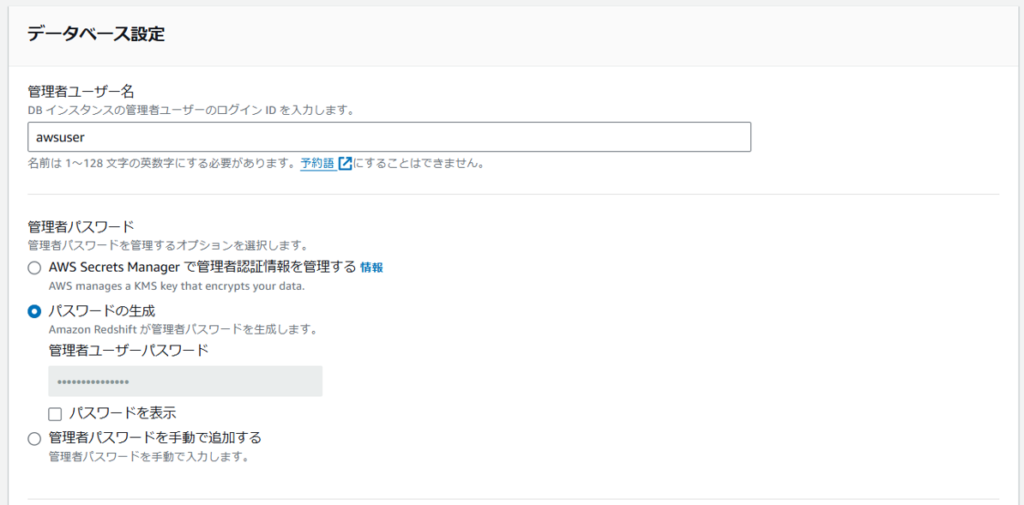
各パラメータを設定します。
先ほど作成したIAMロールをクラスターに関連付けます。
「IAMロールを関連付ける」をクリックします。
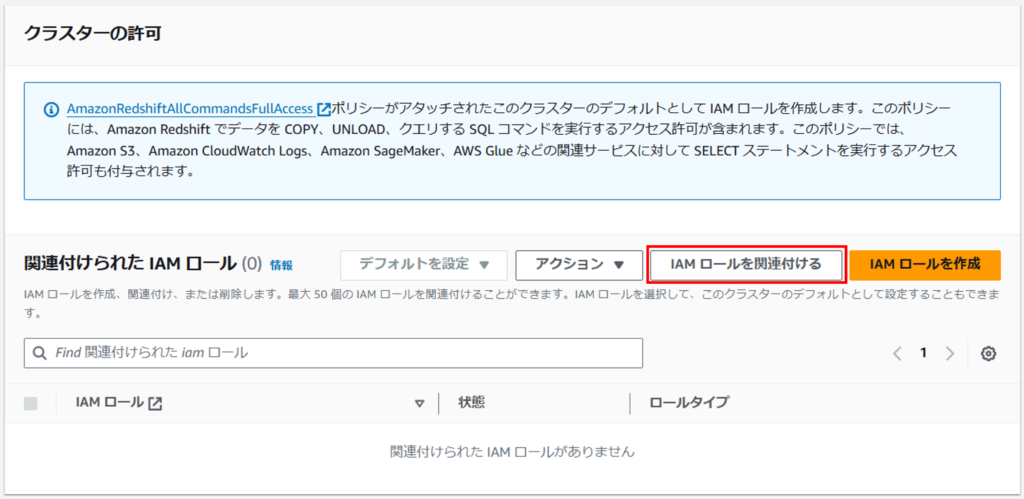
作成したIAMロールを選択し、「IAMロールを関連付ける」をクリックします。
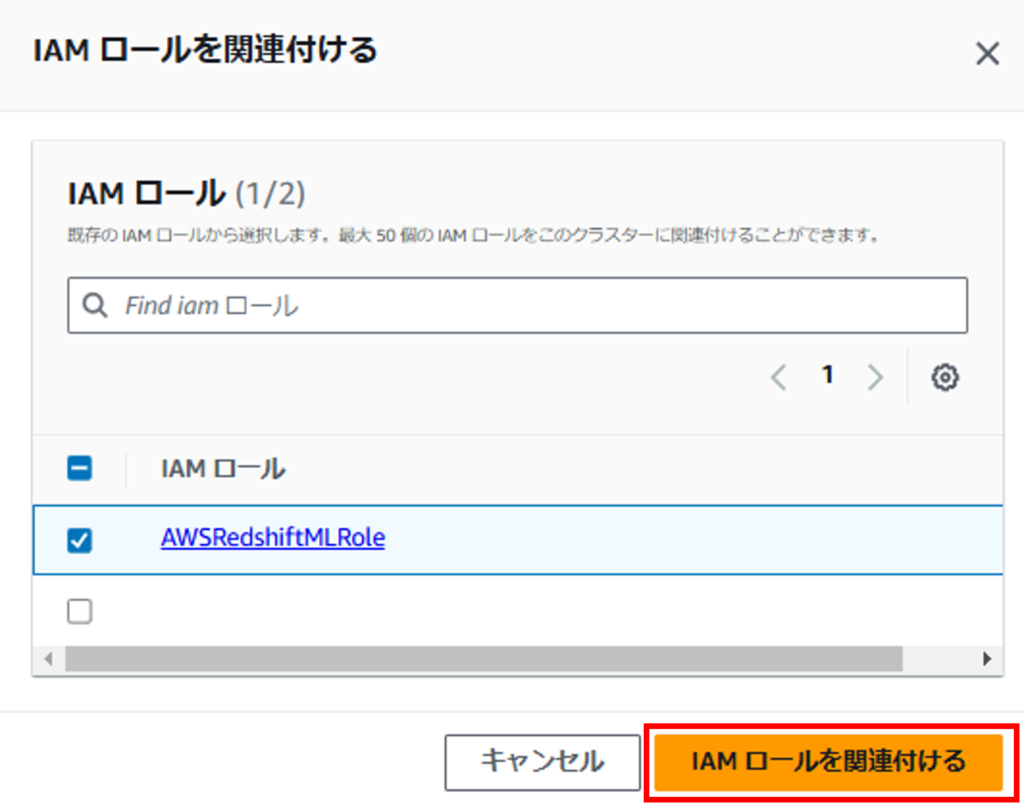
IAMロールが関連付けられたことを確認します。
追加設定を設定し、「クラスターを作成」を押下します。
クラスターが正常に作成されたことを確認します。
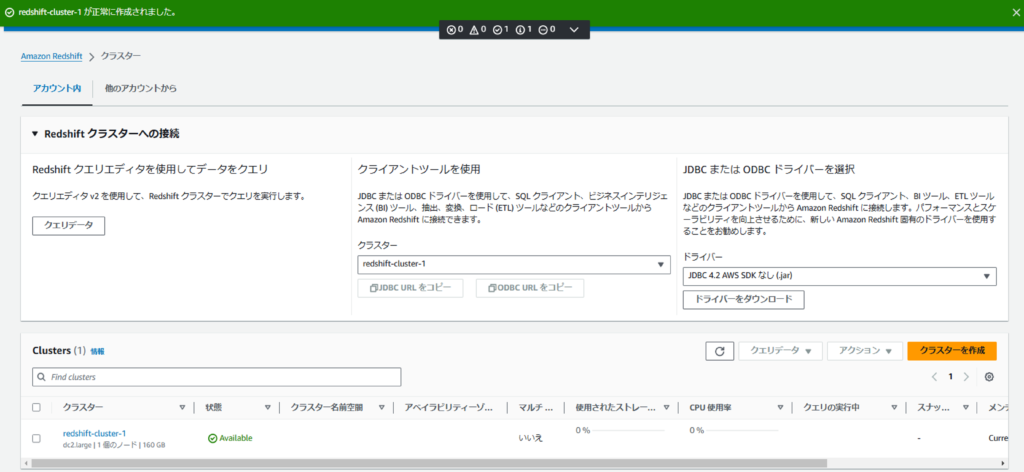
以上でRedshiftクラスターの作成は完了です。
4. 機械学習モデル作成手順
ここまでRedshift MLを使用するための準備をしてきました。
いよいよここからは機械学習モデルの作成をしていきます。
まずはモデル作成に使用するデータの準備を行います。
すでにRedshiftに機械学習に使用できるデータが存在する場合は、「モデル作成」手順まで進んでください。
● 前処理
今回使用するデータは、以下のKaggleデータセットに独自に計算した顧客離反ラベル(churn)を付与したものです。
Customer Personality Analysis | Kaggle
このデータセットには、顧客の個人情報や購買履歴が含まれています。
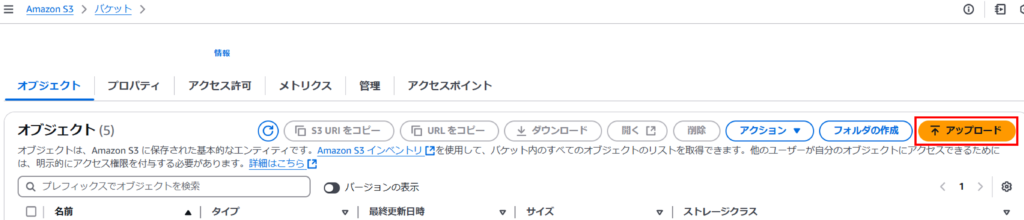
○ S3にファイルアップロード
S3にバケットを作成し(例:redshift-data-test)、「アップロード」を押下するか、ファイルをドラッグ&ドロップして格納します。
○ テーブル作成
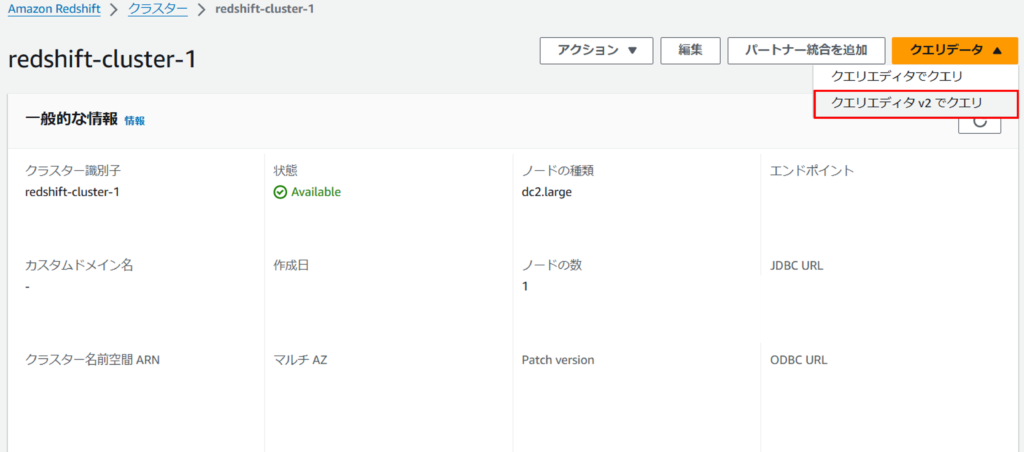
既存、もしくは先ほどの手順で作成したクラスターを選択し、「クエリデータ > クエリエディタv2でクエリ」を押下します。
※クエリエディタv2を使用する際は、個別のIAMポリシーをIAMユーザーにアタッチすることが必要になります。
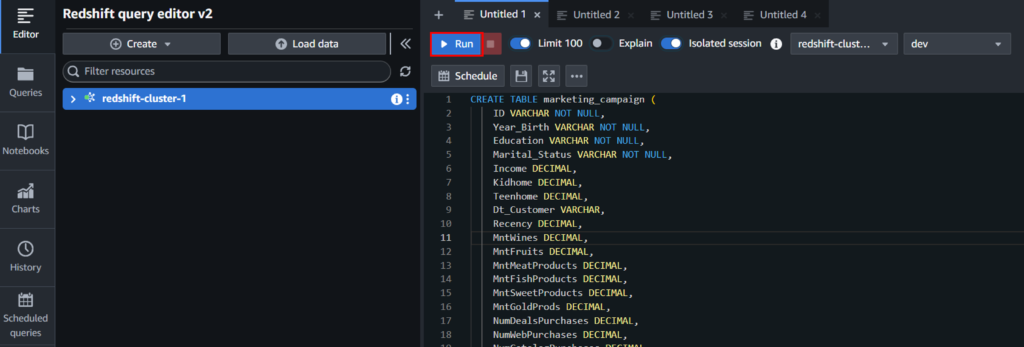
クエリエディタを開いたらawsuserアカウントでログインし、以下のクエリを実行してテーブルを作成します。
CREATE TABLE marketing_campaign (
ID VARCHAR NOT NULL,
Year_Birth VARCHAR NOT NULL,
Education VARCHAR NOT NULL,
Marital_Status VARCHAR NOT NULL,
Income DECIMAL,
Kidhome DECIMAL,
Teenhome DECIMAL,
Dt_Customer VARCHAR,
Recency DECIMAL,
MntWines DECIMAL,
MntFruits DECIMAL,
MntMeatProducts DECIMAL,
MntFishProducts DECIMAL,
MntSweetProducts DECIMAL,
MntGoldProds DECIMAL,
NumDealsPurchases DECIMAL,
NumWebPurchases DECIMAL,
NumCatalogPurchases DECIMAL,
NumStorePurchases DECIMAL,
NumWebVisitsMonth DECIMAL,
AcceptedCmp3 DECIMAL,
AcceptedCmp4 DECIMAL,
AcceptedCmp5 DECIMAL,
AcceptedCmp1 DECIMAL,
AcceptedCmp2 DECIMAL,
Complain VARCHAR,
Z_CostContact VARCHAR,
Z_Revenue VARCHAR,
Response VARCHAR,
churn VARCHAR NOT NULL
);
○ S3からデータ読み込み
以下のクエリを実行し、S3のデータをテーブルに格納します。
COPY marketing_campaign
FROM 's3://<S3のバケット名>/marketing_campaign_label.csv'
DELIMITER '\t' IGNOREHEADER 1
IAM_ROLE '<作成したIAMロールのARN>'
REGION '<リージョン名>';
○ 新規テーブル作成&再度データ格納
テーブルのデータを機械学習に使用できる形式にするため、以下のクエリを実行し新テーブルを作成します。
型変換などが必要ない場合は、そのまま「モデル作成」手順まで進んでください。
CREATE TABLE marketing_campaign_new (
ID VARCHAR NOT NULL,
Year_Birth VARCHAR NOT NULL,
Education VARCHAR NOT NULL,
Marital_Status VARCHAR NOT NULL,
Income DECIMAL,
Kidhome DECIMAL,
Teenhome DECIMAL,
Dt_Customer TimeStamp,
Recency DECIMAL,
MntWines DECIMAL,
MntFruits DECIMAL,
MntMeatProducts DECIMAL,
MntFishProducts DECIMAL,
MntSweetProducts DECIMAL,
MntGoldProds DECIMAL,
NumDealsPurchases DECIMAL,
NumWebPurchases DECIMAL,
NumCatalogPurchases DECIMAL,
NumStorePurchases DECIMAL,
NumWebVisitsMonth DECIMAL,
AcceptedCmp3 DECIMAL,
AcceptedCmp4 DECIMAL,
AcceptedCmp5 DECIMAL,
AcceptedCmp1 DECIMAL,
AcceptedCmp2 DECIMAL,
Complain VARCHAR,
Z_CostContact VARCHAR,
Z_Revenue VARCHAR,
Response VARCHAR,
churn VARCHAR NOT NULL
);
以下のクエリを実行し、新テーブルにデータを格納します。
INSERT INTO marketing_campaign_new (
ID,
Year_Birth,
Education,
Marital_Status,
Income,
Kidhome,
Teenhome,
Dt_Customer,
Recency,
MntWines,
MntFruits,
MntMeatProducts,
MntFishProducts,
MntSweetProducts,
MntGoldProds,
NumDealsPurchases,
NumWebPurchases,
NumCatalogPurchases,
NumStorePurchases,
NumWebVisitsMonth,
AcceptedCmp3,
AcceptedCmp4,
AcceptedCmp5,
AcceptedCmp1,
AcceptedCmp2,
Complain,
Z_CostContact,
Z_Revenue,
Response,
churn
)
SELECT
ID,
Year_Birth,
Education,
Marital_Status,
Income,
Kidhome,
Teenhome,
TO_TIMESTAMP(Dt_Customer, 'DD-MM-YYYY') AS Dt_Customer,
Recency,
MntWines,
MntFruits,
MntMeatProducts,
MntFishProducts,
MntSweetProducts,
MntGoldProds,
NumDealsPurchases,
NumWebPurchases,
NumCatalogPurchases,
NumStorePurchases,
NumWebVisitsMonth,
AcceptedCmp3,
AcceptedCmp4,
AcceptedCmp5,
AcceptedCmp1,
AcceptedCmp2,
Complain,
Z_CostContact,
Z_Revenue,
Response,
churn
FROM
marketing_campaign;
以上でデータの準備は完了です。
ここからモデルの作成になります。
● モデル作成
以下のクエリを実行し機械学習モデルを作成します。
今回はモデル作成に使用する項目を個別に選択しており、年齢、収入、登録日数、最近のHP閲覧、直近2か月で苦情を入れたかどうか、の項目を使用しています。
またデータの都合上、基準日を2015年1月1日としています。
CREATE MODEL customer_churn_model
FROM
(
SELECT 2015 - CAST(Year_Birth AS INT) AS Age,
Income,
DATEDIFF(day, Dt_Customer, '2015-01-01') AS Days_from_enrollment,
Recency,
Complain,
churn
FROM marketing_campaign_new
WHERE CAST(ID AS INTEGER) < 9000
AND Income IS NOT NULL
)
TARGET churn FUNCTION predict_churn_function
IAM_ROLE '<作成したIAMロールのARN>'
SETTINGS (
S3_BUCKET '<S3のバケット名>'
);
※モデルを作成する際のパラメータなどはこちらの公式ドキュメントを参照してください。
今回は「MODEL_TYPE」を指定しないことで、Amazon SageMaker AutopilotのAutoML機能を使用してモデル作成を行っています。
モデル作成のクエリを実行したら、以下のクエリを実行してモデルの作成状況を確認します。
SHOW MODEL customer_churn_model;
モデル作成時は以下のような出力になります。
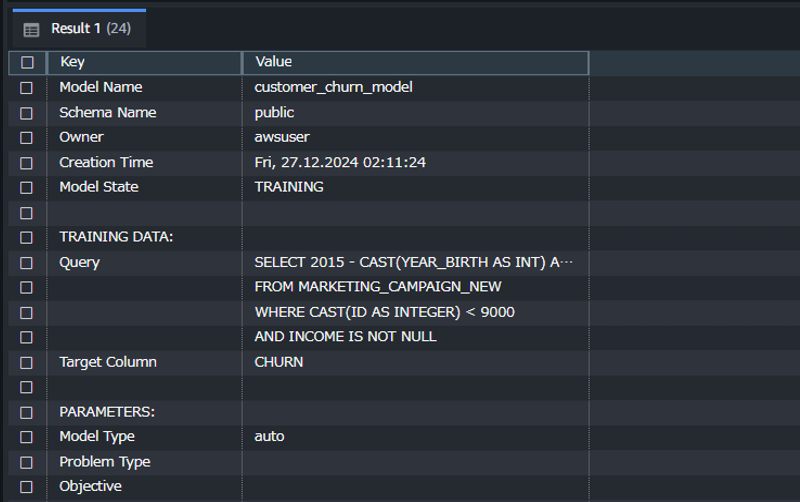
Model StateがREADYになればモデルの作成が完了です。
データ量等にもよりますが、今回は約1時間でモデル作成が完了しました。
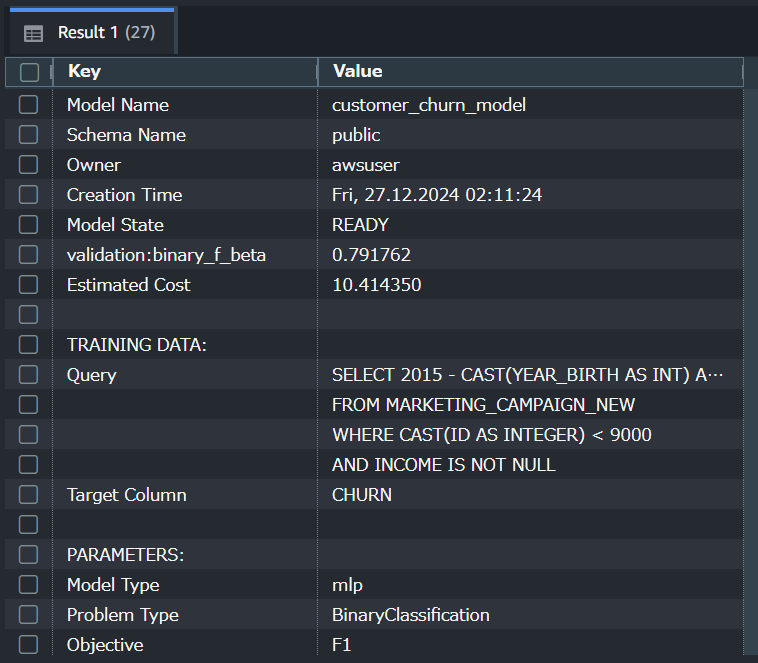
● 効果検証
最後に効果検証を行います。
以下のクエリを実行し、学習に使用しないで残しておいたデータで正解率と適合率、再現率、F値を確認します。
WITH predicted AS (
SELECT
ID,
churn,
predict_churn_function(
2015 - CAST(Year_Birth AS INT),
Income,
DATEDIFF(day, TO_DATE(Dt_Customer, 'YYYY-MM-DD'), TO_DATE('2015-01-01', 'YYYY-MM-DD')),
Recency,
Complain
) :: varchar AS predict_churn
FROM marketing_campaign_new
WHERE CAST(ID AS INTEGER) >= 9000
AND Income IS NOT NULL
),
confusion_matrix AS (
SELECT
SUM(CASE WHEN churn = '1' AND predict_churn = '1' THEN 1 ELSE 0 END) AS true_positive,
SUM(CASE WHEN churn = '0' AND predict_churn = '0' THEN 1 ELSE 0 END) AS true_negative,
SUM(CASE WHEN churn = '1' AND predict_churn = '0' THEN 1 ELSE 0 END) AS false_negative,
SUM(CASE WHEN churn = '0' AND predict_churn = '1' THEN 1 ELSE 0 END) AS false_positive
FROM predicted
),
metrics AS (
SELECT
true_positive,
true_negative,
false_negative,
false_positive,
(true_positive + true_negative) * 1.0 / (true_positive + true_negative + false_negative + false_positive) AS accuracy,
true_positive * 1.0 / NULLIF((true_positive + false_positive), 0) AS precision,
true_positive * 1.0 / NULLIF((true_positive + false_negative), 0) AS recall,
2.0 * true_positive * 1.0 / NULLIF((2.0 * true_positive + false_positive + false_negative), 0) AS f1_score
FROM confusion_matrix
)
SELECT
'true_positive' AS metric, true_positive AS value FROM metrics
UNION ALL
SELECT
'true_negative' AS metric, true_negative AS value FROM metrics
UNION ALL
SELECT
'false_negative' AS metric, false_negative AS value FROM metrics
UNION ALL
SELECT
'false_positive' AS metric, false_positive AS value FROM metrics
UNION ALL
SELECT
'accuracy' AS metric, accuracy AS value FROM metrics
UNION ALL
SELECT
'precision' AS metric, precision AS value FROM metrics
UNION ALL
SELECT
'recall' AS metric, recall AS value FROM metrics
UNION ALL
SELECT
'f1_score' AS metric, f1_score AS value FROM metrics;| metric | value |
|---|---|
| true_positive | 64 |
| true_negative | 349 |
| false_positive | 8 |
| false_negative | 27 |
| accuracy (正解率) | 0.921875 |
| precision (適合率) | 0.888888889 |
| recall (再現率) | 0.703296703 |
| f1_score | 0.785276074 |
今回の結果は全体的に良好ですが、特に再現率(recall)が低いためチューニングの余地はあります。
データの前処理、特徴量の選定、モデルのハイパーパラメータの調整などを行うことで、モデルを改善することが期待できます。
5. 最後に
今回のブログでは、Amazon Redshift MLについて詳しく解説しました。Redshift ML の特徴や SageMaker との比較を通じて、それぞれのサービスの強みや適用例について理解していただけたかと思います。
また、実際にRedshift MLを使用して機械学習モデルを作成する具体的な手順も紹介しました。前処理からモデル作成、効果検証までのプロセスを流れに沿って解説することで、実際の運用イメージを掴んでいただけたのではないでしょうか。
もし、これからRedshift MLを実際に使ってみたいと考えている方は、今回ご紹介した手順に従って進めていただければと思います。
今後も、AWSの機能やサービスについて情報を発信していきますので、お楽しみに!
※ 2024年10月にAmazon Bedrockとの連携により、Redshiftにて生成 AI タスクを活用することができるようになりました。詳細についてはこちらをご確認ください。