


【AI駆動開発検証】#2 対話でコードを磨き上げる。BobとAntigravityの「修正プロセス」の違い
投稿者:土橋
はじめに
こんにちは!NTTインテグレーションの土橋です。
今回のブログは、新人エンジニアによる【AI駆動開発検証】の第2弾です。
前回のブログでは、IBM BobとGoogle Antigravityを使ってみて感じた、それぞれの特徴や使用感について、新人エンジニア目線からご紹介しました。
(前回のブログもぜひご覧ください!→【AI駆動開発検証】BobとAntigravityを触って感じたリアル」)
前回の検証は、比較的簡単なお題だったこともあり、コードの生成完了までスムーズに行うことができました。
しかし、実際の開発現場ではそうはいきません。開発現場でAIにコードを生成させる際、「1発で完璧なコードが出来る」ことは稀で、要件通りのコードが生成されなかったり、予期せぬエラーが出たりと、うまく動かなかったりするのが日常茶飯事です。
AI駆動開発ツールを本格的に開発業務へ取り入れるなら、「最初の一歩」だけでなく、追加要件の実装やエラー対応といった「粘り強い修正」にどこまで付き合ってくれるかが非常に重要になってきます。
そこで、第2弾となる今回は、前回よりも少し難しいお題を与えて、IBM BobとGoogle Antigravityの「修正力」がどれほどのものか試してみることにしました。
追加の要件が来た時どう対応するのか、エラーが出たときにチャットでの対話を通じてどうやってコードを磨き上げていくのか。
今回のブログでは、そんな試行錯誤のプロセスを通じて見えてきた、IBM BobとGoogle Antigravityの修正における個性や検証結果について詳しくお伝えします!
検証のお題:VoCデータの可視化と多角的分析
はじめに、今回の検証のお題をご紹介します。
今回の検証では、前回の検証よりも難しいテーマである「VoCデータの可視化と多角的分析」をお題としました。
また、今回はIBM BobとGoogle Antigravityの修正力を試すために、追加の要件を与えることにしました。
お題
- 実行環境:Google Colab
- 使用ツール:Jupyter Notebook
- 実装要件:VoCデータを元に、頻出単語をワードクラウド形式で表示する
- CSVファイルをアップロードできること
- pandas dataflameにデータロードできること
- 形態素解析し、名詞を抽出できること
- 抽出したデータをワードクラウドとして出力/表示できること
- 追加要件:複数観点での分析を実施する
- 感情分析ができること
- トピック分類ができること
はじめに与えるプロンプトとして、両ツールには、全く同じ以下のプロンプトを渡しました。
プロンプト①
以下のゴールと要件を満たし、Jupyter Notebookで動くコードを作成してください。
返答や出力は必ず日本語で行ってください。
作成したファイルは、Google Colab上にアップロードし実行します。Google Colab上で問題なく動くファイルを作成してください。
#ゴール:
・VoCデータを元に、頻出単語をワードクラウド形式で表示できる
#要件:
・CSVファイルをuploadできる
・pandas dataflameにデータロードできる
・形態素解析し、名詞を抽出できる
・抽出したデータをワードクラウドとして出力できる
・抽出したデータをワードクラウドとして表示できる
また、追加の要件として与えたプロンプトは以下の通りです。
プロンプト②
【プロンプト①で作成したファイル名】に対し、追加で感情分析と、トピック分析を実装してください。
分析対象データ
今回の検証では、VoCデータ(顧客の声)の可視化と分析を行わせるため、iPhoneに対する架空のVoCデータとして、csvファイルを用意しました。
VoCデータはAIに作成させました。実際に検証に用いたVoCデータの一例は以下の通りです。
| 日付 | 性別 | 年代 | 口コミテキスト |
| 2025/11/15 | 男性 | 30代 | 薄くて軽いのが本当に最高!長時間持っていても手が疲れなくて、まるでディスプレイだけ持っているみたいだ。 |
| 2025/11/16 | 女性 | 20代 | デザインがとにかくスタイリッシュで美しい。チタンフレームの質感が上品で、裸で使いたくなる。 |
Bob – プロンプト①の検証結果
プロンプト①をIBM Bobに与えた検証結果を、「コード生成の流れ」と「Google Colab上での成果物」に分けてお伝えします。
■ コード生成の流れ
IBM Bobでは、コード生成は以下のような流れで行われました。
- Todoリストの作成 (人のタスク:Todoリストの確認・作成許可)
- Jupyter Notebookファイルの作成 (人のタスク:生成コードの確認・保存)
- READMEファイルの作成 (人のタスク:READMEファイルの確認・作成許可)
- Todoリストの更新 (人のタスク:Todoリストの確認・更新許可)
また、コード生成過程における実際の画面遷移は以下の通りでした。(生成過程は左から右の流れです)
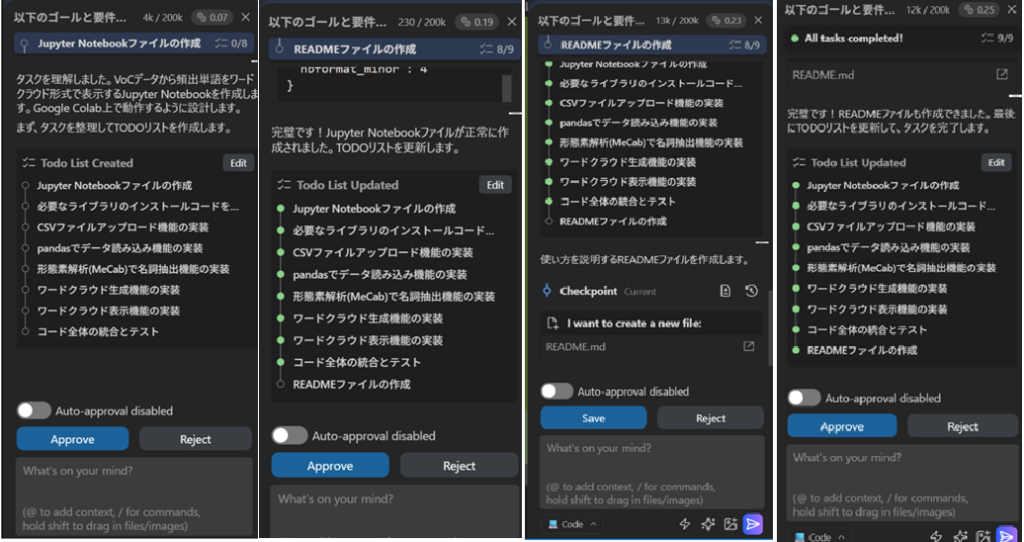
■ Google Colab上での成果物
コード生成が完了したら、Bobに生成してもらったJupyter NotebookファイルをGoogle Colabにアップロードし、挙動確認を行いました。
はじめに、生成されたコードで実装された結果の概要をお伝えします。
- CSVファイルをuploadできる → ◎
- pandas dataframeにデータロードできる → ◎
- 形態素解析し、名詞を抽出できる → ◎
- 抽出したデータをワードクラウドとして出力できる → ◎
- 抽出したデータをワードクラウドとして表示できる → ◎
プロンプト①で与えていた要件をすべて満たすことができていました!
また、実際に生成されたワードクラウド画像は以下の通りです。

非常にわかりやすいワードクラウド画像が生成されています。
また、今回のBobの検証では、プロンプト①を与えた結果、以下のオプション機能の実装まで行われました。
- 頻出単語のランキング表示
- 生成画像のダウンロード保存
- 頻出単語データのエクスポート
実は、先ほど表示したワードクラウドの画像もオプション機能で保存した画像でした。
プロンプト①の検証結果より、
- IBM Bobは、形態素解析やワードクラウドの作成・表示レベルであれば、簡単なプロンプト1回でコードを生成できる
- IBM Bobは、与えられた要件を基に、あったら便利なオプション機能まで実装してくれる
ということがわかりました。
前回の検証でもありましたが、やはりIBM Bobは与えた要件以上のものまで作ってくれることが多いようですね。
今回の検証はブログに掲載しようと考えていたため、ワードクラウドの画像を保存するオプション機能は、非常にありがたい実装でした!
Bob – プロンプト②の検証結果
続いて、プロンプト②をIBM Bobに与えた検証結果を、「コード生成の流れ」と「エラー対応の感想」に分けてお伝えします。
■ コード生成の流れ
プロンプト②を与えると、プロンプト①で作成したファイルの読取・編集を行いたいと表示が出てきました。
それぞれ許可し、既存ファイルの修正、さらにファイルの保存を行わせます。
(IBM Bobは、既存ファイルを修正する際、修正箇所を「削除したい記述(赤)」と「追加した記述(黄色)」で表示してくれました。)
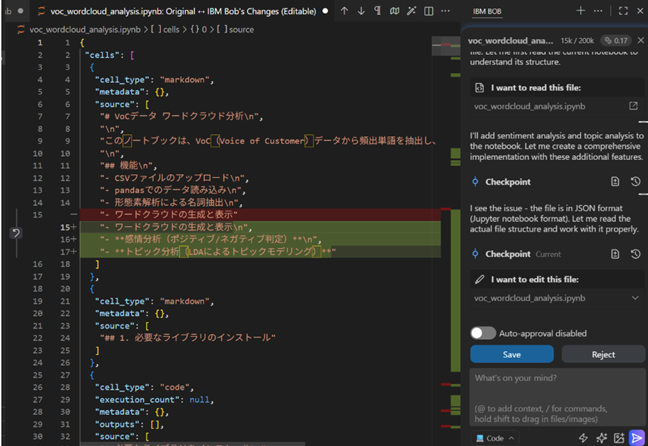
今回はGoogle Colab上で動くことを確認するため、コード内容は軽く確認するだけとし、
ファイル保存を許可→Google Colab上で動作確認→エラーログの送付→ファイルの修正、という事を繰り返してコード生成を進めました。
今回の追加実装は、上記のコード生成フローからも察せると思いますが、、、
一筋縄ではいきませんでした!!
プロンプト①の検証では1回で要件通りの動くコードが作れましたが、同じ温度感で難易度の高い追加要件を与えるのでは、上手くいかないようです。
やはり難しいお題を少ない手数で実現するには、プロンプトの工夫が必要ですね。
今回のエラー修正では、わかりやすいプロンプト入力は敢えてせず、
エラーログの送付と要望だけ簡単に入力するだけで、エラー修正を試みてみました。
エラー修正の流れもすべてお見せしたいのですが、すべて載せると膨大な画像・分量になってしまうため、
今回はどのようにエラーを解消していったのか、その概要をお伝えします。
生じたエラーとエラー対応は以下の通りでした。
- ライブラリの互換性エラー ⇒ バージョンを固定し不整合を防ぐ例外処理を追加
- 依存ライブラリのインポートエラー ⇒ 古いライブラリ削除と整合する特定版を導入
- モデルの読み込みエラー ⇒ 順次試行する自動復旧機能を実装
今回の追加実装では、Google Colab特有のライブラリ競合(emojiやtransformersのバージョン問題)に何度も直面しました。
ですが、エラーログを渡すたびに、Bobはエラーログから原因・解決策を導き出して修正を行い、結果として4回ほどのやりとりで追加機能を実装した動くコードが完成しました!
■ IBM Bobのエラー対応の感想
Google Colab上でトピック分析と感情分析を実行することができたため、ここでは成果物の詳細ではなく、IBM Bobによるエラー対応で感じたことをお伝えします。
① エラー対応力
Google Colab特有のライブラリ競合により修正回数は多くなりましたが、エラーログと要望を渡すだけで原因特定から対策まで完結することができました。
今回の検証を通じて、IBM Bobはエラー修正を容易に行うことができるとわかり、実際に開発現場で使う際にも頼もしい相棒になると感じました。
② 先回りした機能提案力
IBM Bobは指示通りの実装に留まらず、UXより豊かにするプラスアルファの機能を提案してくれる傾向があります。
自分では気づかなかった実装アイデアをBobが形にしてくれることで、新たな発見に繋がり、自動生成ツールならではの強みを実感しました。
③ 優れたUI/UX
IBM Bobの画面は、「次に何をすべきか」「AIがどこまで進めたか」が視覚的に整理されており、開発プロセスの透明性が非常に高いと感じました。
特に、エラー修正や追加実装時には、AIがどこを書き換えたいのかが一目でわかるようになっています。
これにより、人間によるレビューがしやすいくなっており、AIの挙動をコントロールしやすい、良いコード生成ツールだと感じました。
Antigravity – プロンプト①の検証結果
プロンプト①をGoogle Antigravityに与えた検証結果を、「コード生成の流れ」と「Google Colab上での成果物」に分けてお伝えします。
Google Antigravityでは、コード生成に使用するモデルが選択可能ですが、今回はGemini 3 Pro(High)を選択しました。
■ コード生成の流れ
Google Antigravityでは、コード生成は以下のような流れで行われました。
- 実行計画書の作成 (人のタスク:実行計画書の確認)
- Jupyter Notebookファイルの作成
- walkthroughファイルの作成
IBM Bobに比べて、Google Antigravityは実行計画書の生成後はすぐにコードを生成する流れになっています。
また、コード生成過程における実際の画面遷移は以下の通りでした。(生成過程は左から右の流れです)
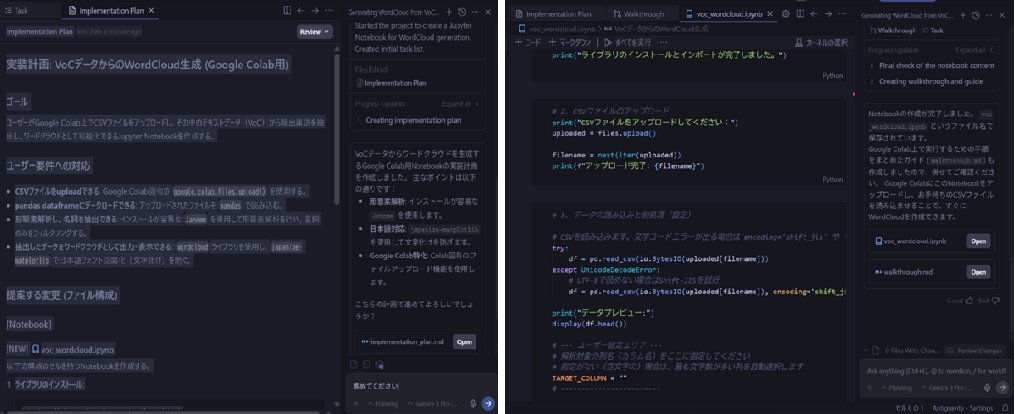
■ Google Colab上での成果物
コード生成が完了したら、Antigravityに生成してもらったJupyter NotebookファイルをGoogle Colabにアップロードし、挙動確認を行いました。
はじめに、生成されたコードで実装された結果の概要をお伝えします。
- CSVファイルをuploadできる → ◎
- pandas dataframeにデータロードできる → ◎
- 形態素解析し、名詞を抽出できる → ◎
- 抽出したデータをワードクラウドとして出力できる → ◎
- 抽出したデータをワードクラウドとして表示できる → ◎
Antigravityにおいても、プロンプト①で与えていた要件をすべて満たすことができていました!
また、実際に生成されたワードクラウド画像は以下の通りです。

Bobと同様、Antigravityでも非常にわかりやすいワードクラウド画像が生成できていますね。
Antigravityでは、Bobのようにオプション機能の実装はありませんでした。
しかし、Antigravityの生成したコードでは、csvファイルをアップロードするだけで、どのカラムが分析対象のカラムであるか自動で判定する機能がついていました。(Bobではカラム名を指定する必要あり)
プロンプト①の検証結果より、
- Google Antigravityは、形態素解析やワードクラウドの作成・表示レベルであれば、簡単なプロンプト1回でコードを生成できる
- Google Antigravityは、UXを踏まえて確実に必要要件の実装を行ってくれる
ということがわかりました。
やはり、Google Antigravityは与えられた要件を着実に、かつ高品質で実現してくれるという印象がありますね。
Antigravity – プロンプト②の検証結果
続いて、プロンプト②をGoogle Antigravityに与えた検証結果を、「コード生成の流れ」と「エラー対応の感想」に分けてお伝えします。
■ コード生成の流れ
Google Antigravityにおいても、追加機能の実装は一筋縄ではいきませんでした。
Bobと同様に、Antigravityのエラー修正においても、わかりやすいプロンプト入力は敢えてせず、
エラーログの送付と要望だけ簡単に入力するだけで、エラー修正を試みました。
Antigravityのコード生成で生じたエラーとエラー対応の概要は以下の通りです。
- リポジトリ参照エラー ⇒ 認証不要かつ公開されている適切なモデル識別子へ修正
- 辞書ライブラリ不足 ⇒ 必要な辞書と依存ライブラリを追加インストール
- トークナイザ不整合 ⇒ sentencepieceを導入
Antigravityで発生したエラーは、同じ原因から生じたというよりも、それぞれ別のエラーであり、一つ一つのエラーを着実に解消したようでした。
またAntigravityの修正対応は3回程度で、IBM Bobより少ない回数で、要件を満たした動くコードを完成させることができました。
■ Google Antigravityのエラー対応の感想
Google Antigravityにおいても追加実装の成果物ではなく、エラー対応で感じたことをお伝えします。
① エラー対応力
Antigravityは、一度エラーを伝えると、不足している要素を的確に把握し、一気に修正を完了させてくれました。
最初から環境依存のリスクが低い、堅牢な構成を選ぶ傾向があるため、手戻りが非常に少ないのが印象的でした。
② 要件への忠実な実装力
Antigravityはオプション機能の実装はなくとも、指定通りの要件を満たしたコードを仕上げてくれました。
過剰な提案がない分、自分の意図した通りのスマートなプログラムを最短で作りたい時に非常に頼りになると感じました。
③ UI/UX面において
Antigravityは余計なやり取りを省いてサクサク進める良さがある反面、次に何をすべきかのガイドが少ないと感じました。
また、コードのどの部分を書き換えたかがハイライトされないため、一目で修正箇所を把握するのが難しいと感じました。
そのため、Antigravityでは、Bobのように事前のレビューで制しえコードの把握を行うのではなく、
「エラーが出るたびにAIと会話を行い、対話でAIをコントロールしていく」という進め方がよさそうです。
まとめ
今回の検証では、あえて少し難しいお題を投げかけ、IBM BobとGoogle Antigravityの「修正力」に焦点を当ててみました。
一発で完璧なコードを出すのが難しい複雑なお題であっても、両ツールとも「追加実装やエラー修正を難なくこなせる」という実力を見せつけてくれました。たとえライブラリの競合や環境依存のエラーにぶつかったとしても、エラーログを渡して対話を重ねることで、最終的には「動くコード」へと確実に磨き上げることができます。
最後に、今回の検証のまとめです。
検証まとめ
- IBM Bobは、丁寧なUIとTODO管理で、「プロセスを共有しながら着実に」
- Google Antigravityは、堅牢な構成と的確な判断で、「最短ルートでスマートに」
AI駆動開発ツールは、単なる「コード生成ツール」ではなく、試行錯誤を並走してくれる「開発のパートナー」として、すでに十分頼もしい存在になっていると感じました。
今後はさらに複雑なシステムの設計やフレームワークを指定してAI駆動開発検証を行う予定です!
次回の検証レポートも、ぜひご期待ください!
最後まで読んでいただき、ありがとうございました!