


【Alteryx】大規模言語モデル (LLM) をワークフローに統合するGenAI (生成AI) の全ツールを触ってみた【Part2】
投稿者:四至本
こんにちは。NI+C Alteryxチームです。
本Blogは、【Alteryx】大規模言語モデル (LLM) をワークフローに統合するGenAI (生成AI) の全ツールを触ってみた【Part1】の続きとなります。
【Part1】ではAlteryx GenAIの全体像と接続設定、「生成AIツール」の「LLM Override Tool (LLM上書き設定ツール)」と「Prompt Tool (プロンプトツール)」の検証結果をご紹介しました。
今回は、「生成AI支援ツール (LLMにて特定のデータ処理タスクを行うツール)」の検証結果と一連の検証を通して見えてきたAlteryx GenAIの考察をご紹介します。
各GenAIツールの検証・紹介 (生成AI支援ツール編)
Alteryx Designer上で「GenAI (生成AI支援ツール)」を配置しどのような処理ができるのか、簡易的なシナリオを想定して検証した結果をご紹介します。
※LLMモデルの性能やプロンプトの書き方によって精度は変化します。
※GenAIは確率的に出力を返すため、ハルシネーションの発生や同じ入力でも必ず同様の結果にならない点に留意してください。
③Invoice Extractor Tool (請求書抽出ツール)

請求書やレシート(PDFや画像)を読み込み、項目とメタデータを自動的に抽出するツールです。
【検証シナリオ】
スーパーのレシート(PNGファイル)を読み込ませ、明細とヘッダー情報が正しく抽出できるか検証
【入力データ:レシート画像】

【請求書抽出ツールの設定】
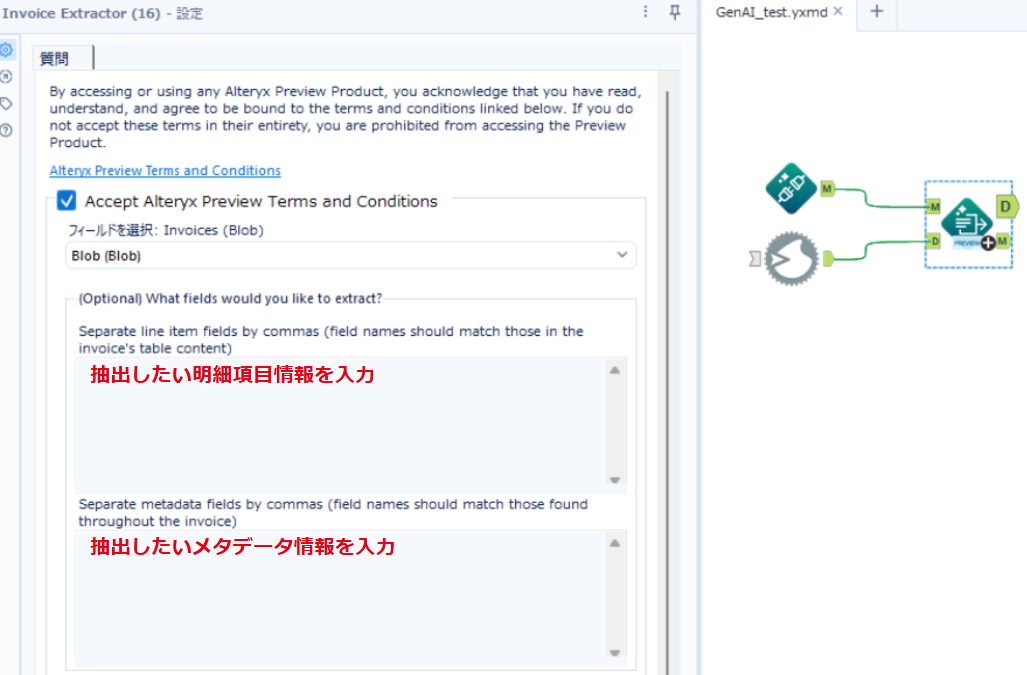
入力するPDFや画像データはBlob形式になります。設定内の「フィールドを選択」にBlobを選択します。
Optional (オプション)は取得したい情報のプロンプトを入力します。今回は、入力せず生成AIが画像を読んで判断してもらいます。
その他の設定項目はデフォルトになります。
※詳細な設定手順は、公式ヘルプドキュメント(請求書抽出ツール)になります。
【出力結果】
明細項目用とメタデータ用に分かれて結果が出力されます。
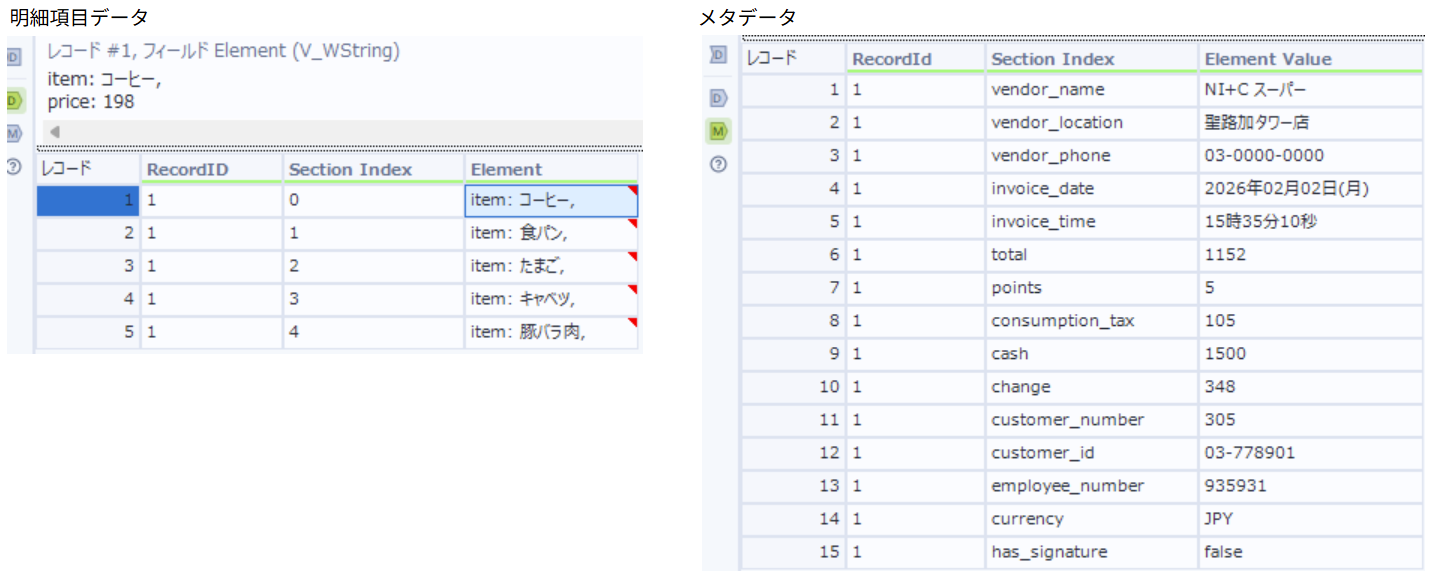
メタデータについては、店舗名 (vendor_name)や合計金額 (total)などが正しく抽出され、さらに画像には明記されていない「通貨(currency): JPY 」まで文脈から補完して出力してくれました。
明細項目データについては、商品名 (item)と金額 (price)のリスト化に成功しました。レシートの1行目にある 「コーヒー」をはじめ、各項目が綺麗に抽出されています。
非構造化の画像データが、Alteryxで後続処理しやすい「表形式 (構造化データ)」に一瞬で変換されるのは非常に強力です。
④Precision Match Tool (表記標準化ツール)

ファジーマッチツールのような機能で、表記ゆれのあるデータを文字の類似度だけでなく「意味の近さ」で名寄せ・標準化してくれるツールです。
【検証シナリオ】
「都道府県名」の表記ゆれを含むデータを、正しい正解マスタに合わせて標準化できるか検証
【入力データ】

【表記標準化ツールの設定】
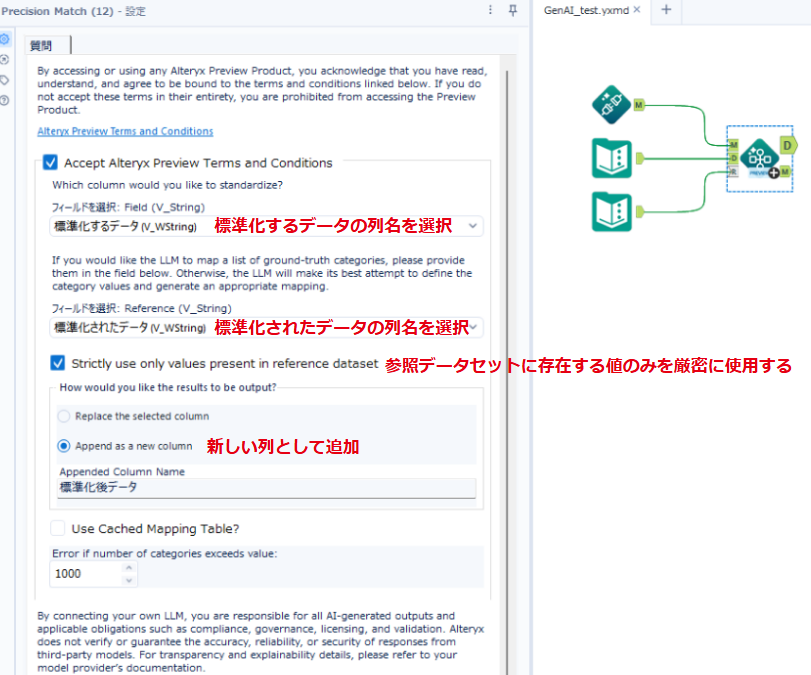
「フィールドを選択:Field」に標準化するデータの列名、「フィールドを選択:Reference」に標準化されたデータの列名を選択します。
出力方法として 、Append as a new column (新しい列として追加)を選択しました。
今回は標準化されたデータの値だけに統一したいため、Strictly use only values present in reference dataset (参照データセットに存在する値のみを厳密に使用する)にチェックを入れています。
その他の設定項目はデフォルトになります。
※標準化されたデータが定まっていない場合はR入力アンカーにデータを接続する必要はありません。
※詳細な設定手順は、公式ヘルプドキュメント(表記標準化されたツール)になります。
【出力結果】
一致した入力データとLLMから出力されるマッピングテーブルの結果が出力されます。
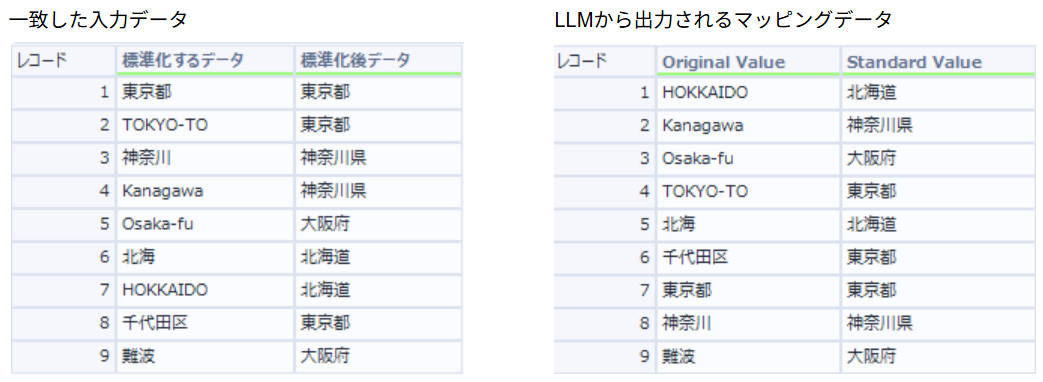
「TOKYO-TO」→「東京都」、「神奈川」→「神奈川県」のように、名寄せや表記ゆれの修正が正しく行われていました。また、「千代田区」→「東京都」 や 「難波」→「大阪府」 のように文字の見た目は全く異なりますが、AIが知識を持っているため正しい都道府県にマッピングすることができました。
標準化されたデータを入力するだけで高度な名寄せや表記ゆれが実現可能になり、データクレンジングの工数を劇的に削減できます。
⑤Schema Fit Tool (スキーマ変換ツール)

バラバラなデータを、ターゲットとなるデータの形式に合わせて整形してくれるツールです。
【検証シナリオ】
「姓名が分かれていて、日付形式も違うデータ (ソースデータ)」を、「姓名が1列にまとまっていて、日付形式も標準化されたマスタ (ターゲットデータ)」の形式に自動変換できるか検証
【入力データ】
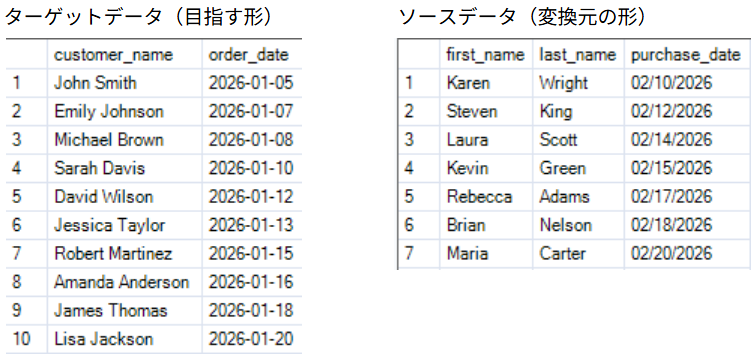
【スキーマ変換ツールの設定】
ターゲットデータをT入力アンカー、ソースデータをS入力アンカーに接続します。
Number of transformations to make (実行する変換ステップ数)を「2」に設定しました。
また、余計な列を出さないようOnly include target schema columns (ターゲットスキーマ列のみ含む)にチェックを入れています。
※詳細な設定手順は、公式ヘルプドキュメント(スキーマ変換ツール)になります。
【出力結果】
ソースデータの変換に使用する手順内容と変換されたデータの結果が出力されます。
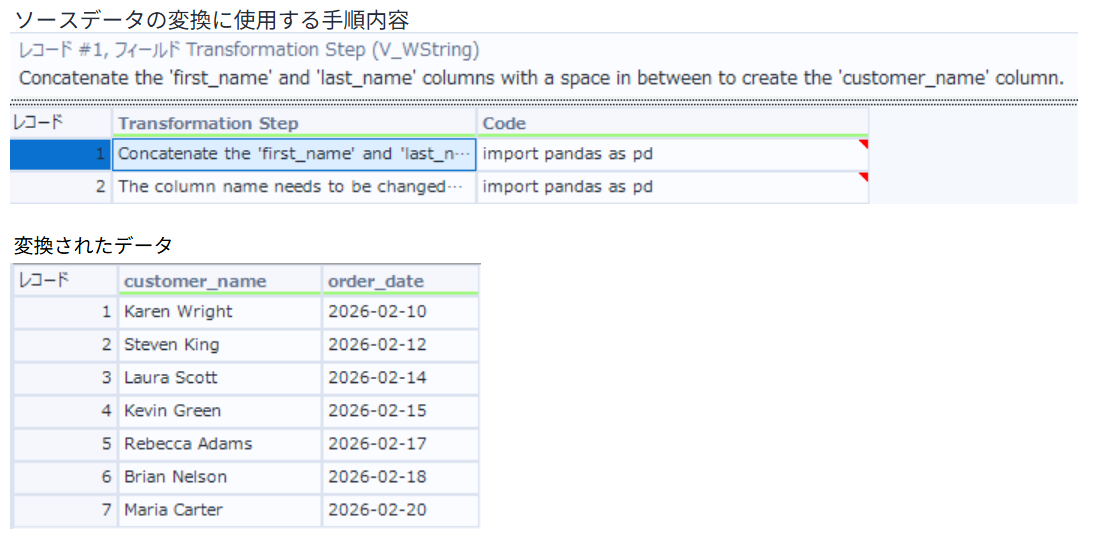
出力結果は正確に整形されていました。「first_name」と「last_name」がスペース区切りで結合され、「customer_name」になりました。また、「purchase_date 」が「order_date」にリネームされた上で、MM/DD/YYYYからYYYY-MM-DD形式に日付変換されました。
<変換ステップ数の設定について>
検証時、最初「実行する変換ステップ変換数」を「1」で試したところ、何も出力されませんでした。これを「2」に増やしたところ成功しました。原因は、出力結果の「Transformations Step(変換手順)」を見ると分かります。AIは内部で以下の2つの処理を行っていました。
1. 名前の結合処理 (Concatenate the “first_name” and “last_name” columns with a space in between to create the ‘customer_name’ column.)
2. 列名と日付の変更処理 (The column name needs to be changed from “purchase_date” to “order_date”. The values in the column need to be transformed from MM/DD/YYYY to YYYY-MM-DD format.)
このように、生成AIが「2段階の加工が必要だ」と判断した場合、設定値が「1」だと処理が完遂できなくなります。
複雑な変換を行う際は、この「Number of transformations to make」を多めに設定しておくのが良いと思います。
※ただし、根拠なく実行する変換ステップ変換数を増やしても正確性向上に繋がらずかえって処理が重くなることもあります。
⑥Synthetic Input Tool (合成入力ツール)

本番データを使えない場合などに、ダミーデータ等の合成データを生成してくれるツールです。
【検証シナリオ】
コーヒースタンドの1日の売上データを生成できるか検証
【合成入力ツールの設定】
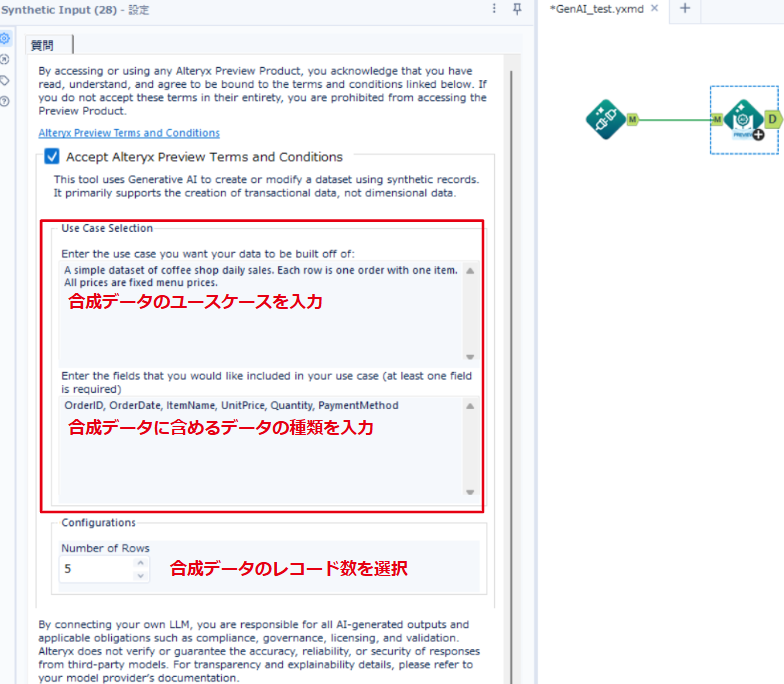
Use Case Slection (ユースケースの選択) に上記のプロンプトを入力します。
Number of Rows (生成したいレコード数) を「5」に設定しました。
※詳細な設定手順は、公式ヘルプドキュメント(合成入力ツール)になります。
【出力結果(変更前)】

最初の検証時、LLMモデル (Google Gemma 3 12b)と簡単なプロンプトで試してみました。すると、コーヒースタンドの売上データを想定していたにもかかわらず、なぜかアパレルショップのようなデータやデータの種類が増えるなど非現実的な出力になりました。
そこで、実用的なデータを生成するために2つの変更を加えました。
1つ目は、異なるLLMモデルの変更です。「LLM上書き設定ツール」は設定からすぐにLLMモデルの変更ができます。今回は上位モデルのGoogle Gemma 3 27bに切り替えました。(選択できるLLMモデルが複数ある場合)
2つ目は、プロンプトの具体化です。生成AIが文脈を正しく理解できるよう、英語で「固定のメニュー価格であること」などを明確に指定しました。
【出力結果(変更後)】

変更を加えた出力結果を見ると、ユースケース通りのデータになり「Americano は $2.75」「Latte は $3.75」といったように商品 (ItemName)と単価 (UnitPrice)の整合性が取れているなど、現実的な出力になりました。
最良の合成データを作成するには、タスクの難易度に応じたモデルを選択後、具体的なプロンプトを入力し、Alteryxの標準ツールで加工して仕上げるという使い方がベストプラクティスとなります。
さいごに
最後に、一連の検証を通じて感じたまとめになります。
①「意味」をGenAIが理解し、「処理」はAlteryx標準ツールが担う
「GenAIで非構造化データを構造化し、その後の集計・加工はAlteryxの既存ツールで行う」 という役割分担の重要性です。数値計算や厳密なルール処理は、生成AIよりもAlteryxの標準ツールの方が正確で速いです。「全部AIに任す」のではなく、AIが得意な「暖味な言葉の理解」だけを任せ、あとはAlteryの得意な「データ加工」にバトンタッチする。結果として相乗効果につながり、Alteryx上でGenAIを使う最大のメリットだと感じました。
② ユースケースごとに見極める「GenAIと標準ツール」の使い分け
生成AIは確率的に答えを出す特性上、ハルシネーションが起きたり、毎回完璧な結果が出力されるとは限りません。そのため、生成AIの出力結果を鵜呑みにするのではなく、業務の特性や求める精度に合わせてAlteryxの中で最適なバランスを見つけることが不可欠だと思います。生成AIの強みが活きる処理がメインならGenAIツールとの組み合わせ、確実性が求められる処理がメインなら標準ツールのみのワークフローという風に、各ユースケースごとにGenAIとAlteryx標準ツールを柔軟に使い分けていくアプローチが重要だと感じました。
③タスクに応じたLLMモデルの柔軟な切り替え
求める結果を得るにはプロンプトの工夫だけでなく「適切なLLMモデルの選択」も重要です。Alteryxでは様々なLLMに接続することができます。LLMとの接続設定を行えば、異なるLLMプロバイダーや異なるLLMモデルへ簡単に切り替えて試すことができます。この「用途に合った生成AIを柔軟に選んで連携できる」環境も、大きな魅力の一つだと感じました。
最後までお読みいただき、ありがとうございました。
Alteryxは、データ加工・分析や自動化を簡単に行えるセルフサービス分析プラットフォームになります。
詳細については、ぜひAlteryx(アルテリックス)の概要をご紹介のブログをご参照ください。
「まずは説明だけでも聞いてみたい!」といった方も、ぜひ下記問い合わせフォームよりお問い合わせください。
—–
danect⁺でAlteryx等を用いたデータ集計・分析自動化サービスを展開中です!→danect⁺データ集計・分析自動化サービス
—–