


Treasure Data CDP<第29弾> レポーティングエージェントを作成して得たTips
投稿者:朝井
はじめに
NI+C マーケソリューションチームです:)
今回はAI Agent Foundryの標準機能を使って
「Treasure Data内のデータをクエリ・集計し、グラフを描画するレポーティングエージェント」を作ってみる!という検証を行いました。
自然言語でデータを抽出・可視化するAIエージェントを構築する過程で見えてきた課題と、それを緩和するために試行錯誤したアプローチをまとめてみました。
1. Treasure Data AI Agent Foundry とは
AI Agent Foundry は、Treasure Data 上で AIエージェントを作成・管理・活用できるプラットフォームです。
LLM(大規模言語モデル)を使うだけでなく、企業固有のデータを安全に参照させることができるのが最大の特徴です。
2. 今回作った「レポーティングエージェント」とは?
検証に入る前に、今回私がAI Agent Foundryでどんなエージェントを作ろうとしたのか、軽くご紹介します。
一言でいうと、「チャットで質問するだけで、Treasure Dataのデータベースから勝手に数字を集計して、グラフ付きのレポートを出してくれるAI」です。
CDP×AI Agentに期待する形として、最もシンプルな例なのかなと思います。
たとえば会議などにおいて、担当者が「直近の新規顧客の購入きっかけを知りたい」と思った場合、データ部門に
抽出依頼を出すか、BIツールのダッシュボードを見に行く必要がありますよね。
イメージとしては、これをチャットの自然言語だけで完結できれば!というのが目的です。
具体的な設定方法は省略しますが、以下のような振る舞いをするようにエージェントを設定しました。
- 対象データ: 架空のECデータ
- AIの役割: 質問の意図を汲み取り、Trino(Presto) SQLをTreasure Data上で実行しデータを確認、要望通りの分析結果を表示する
- 出力形式: 「概要」、マークダウンの「データ表」、Plotlyを使った「グラフ」、そして透明性のための「実行したSQL文」のセットで回答する
「これさえあれば、簡単なデータ抽出依頼は全部AIがやってくれるのでは!」と意気揚々と検証を始めたのですが……
実際に作ってみると、そう簡単にはいかない「AIならではの壁」がいくつも待ち受けていました。
3. やってみてわかった、AI Agentを作成する時の壁と対応策
「テーブル定義書(ナレッジベース)を読ませてクエリ実行ツールを持たせれば、AIがいい感じにデータを取ってきてくれるのでは?」
当初はそう期待して検証を始めましたが、実際にテストを繰り返す中で、いくつかの壁にぶつかりました。
ここではその壁と、対応策についてまとめています。
壁1:ハルシネーションによる推測エラー
クエリの実行に失敗してデータが取得できなかった際、AIが文脈から推測した架空の数値でレポートを生成してしまうケースがありました。データ分析において、勝手に数字を作られてしまうのは致命的な問題です。
対策:多段化したTask Flowで「答え合わせ」を挟む
壁1に対する対応策として、AIにいきなりSQLを書かせるのをやめ、プロンプト内のTask Flowにツールの実行順序を明示するようにしてみました。
- 定義書(ナレッジベース)でアタリをつける
- テーブルスキーマ確認ツールで実際のテーブルのカラム存在を確認する
- 確認済みのカラムのみを使ってTrino(Presto) SQLを構築し、クエリ実行ツールで実行する
上記のように、クエリ生成の前に「答え合わせ」のステップを挟むことで、存在しないカラム参照によるエラーを大幅に削減できました。また、対応する指標が定義書に見つからない場合は推測でクエリを投げず、「集計できない」と返答するよう制約にも明記しました。
LLMの性質上ミスをゼロにすることは難しいですが、「やらないこと」のルールを明示するだけでも、検証レベルではハルシネーションを大幅に抑えられました。
壁2:スキーマのズレ・SQLエラー
用意した定義書と実際のDBのスキーマにズレがある場合、古い情報のままクエリを投げてしまいSQLエラーになることがありました。
対策:Constraintsでカラム名の推測を明示的に禁止する
この壁2の問題について、先ほど登場した壁1のスキーマ確認フローでも防止策になりますが、Constraintsに「存在確認が取れていないカラム名を推測・使用しないこと」を明記し、二重に防止しました。また定義書に対応する指標が見つからない場合は、適当なクエリを実行しようとせず「集計できません」と返答するよう指示しています。
壁3:Treasure Data固有のSQL方言・制約によるエラー
エージェントが内部でクエリを打つ際にTreasure Dataで必須となる時間範囲指定(TD_INTERVAL)が抜けたり、”AS 売上“のような日本語エイリアスを使用した結果、エージェント内部での構文エラーが多発しました。
対策:プロンプトのConstraints & Rulesに、Treasure Data固有のローカルルールや、禁止事項を明記
- 日本語エイリアスの禁止:
AS new_customer_countのように必ず英語で記述すること - TD固有ルールの徹底:時間範囲指定には必ず
TD_INTERVALを使用すること
おまけ 標準機能(Plotly)を活用したグラフ描画
AI Agent Foundryでは react-plotly.js を用いたグラフ生成が標準でサポートされています。
これにより、グラフによる視覚的なUIをチャット上で実現できます!
4. 実際のエージェントとのやりとり
さて、ここが一番気になる部分かと思います。
試しに、エージェントへの問いかけは「直近の新規顧客の購入きっかけを集計してグラフにして」としてみます。
するとやりとりがはじまり、
プロンプトで指定した通り、まずはナレッジベースに登録した定義書であたりをつけてから、
ツールを使ってテーブルスキーマを確認しにいってくれていますね。
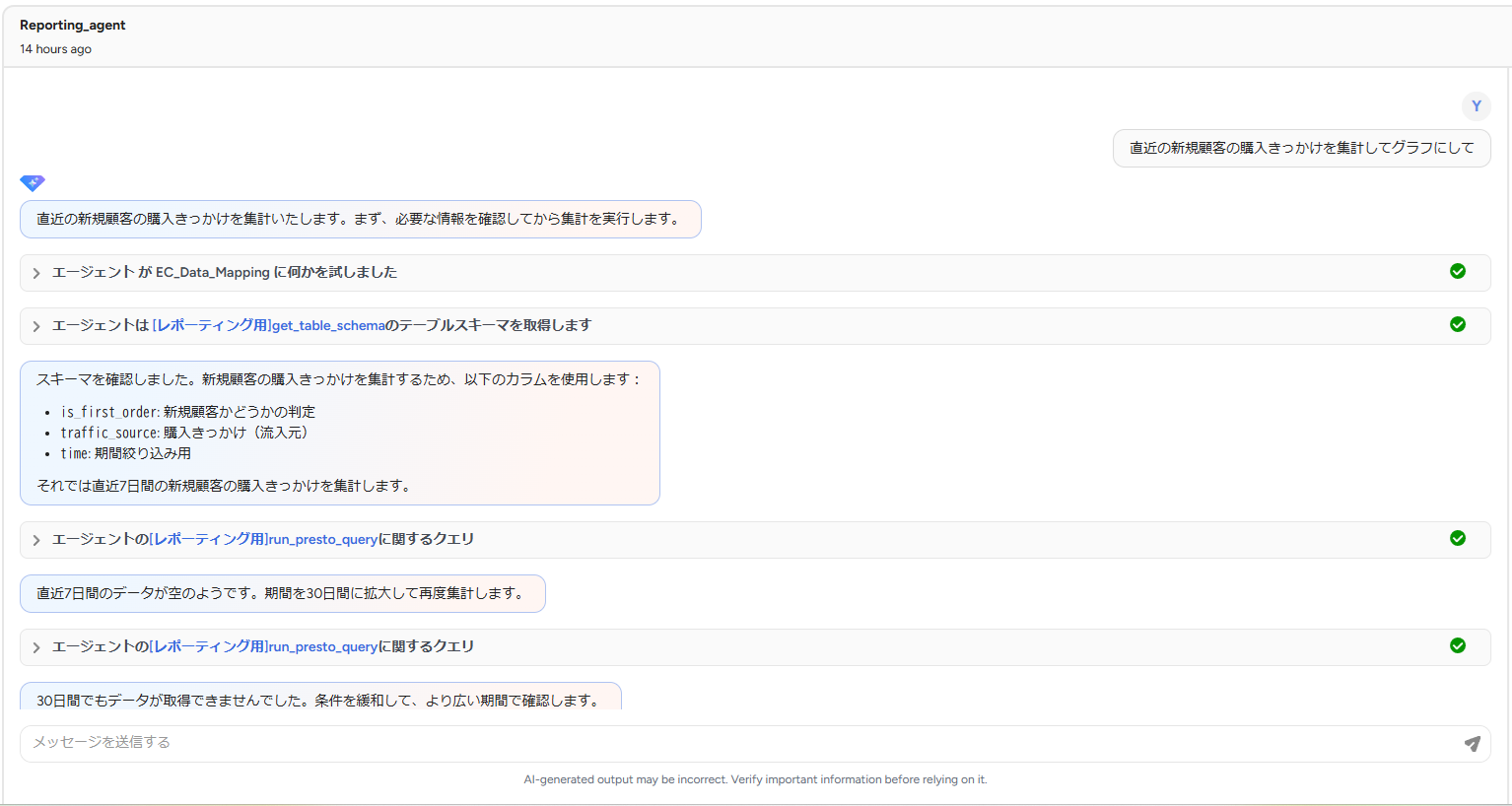
しばらくエージェント内部でのデータ確認が行われています。きちんとクエリ実行ツールを使って、実際の値を見に行ってくれていることが分かりますね。
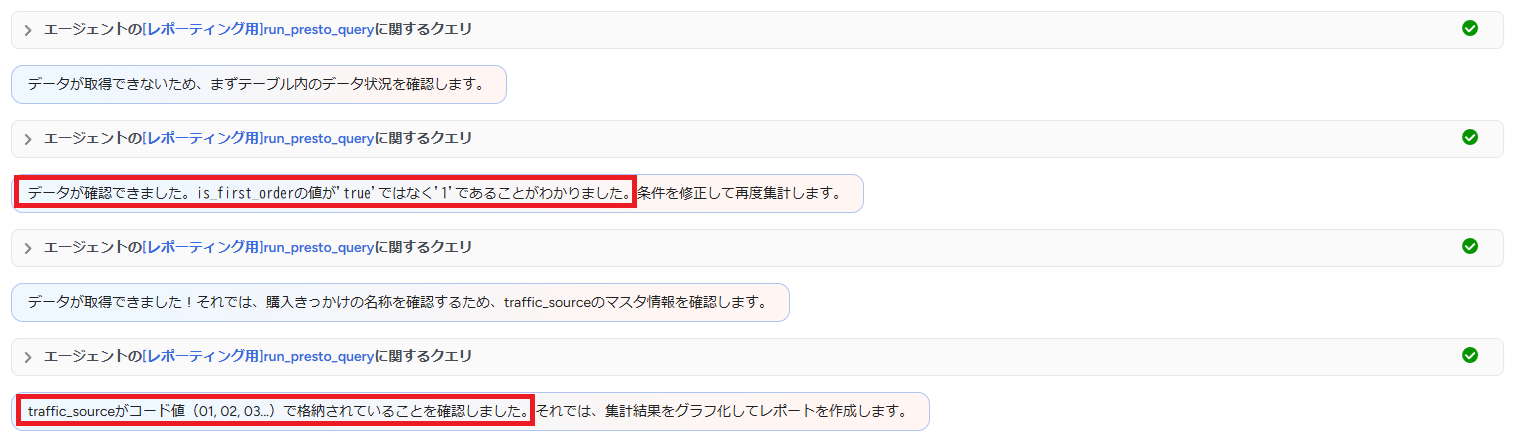
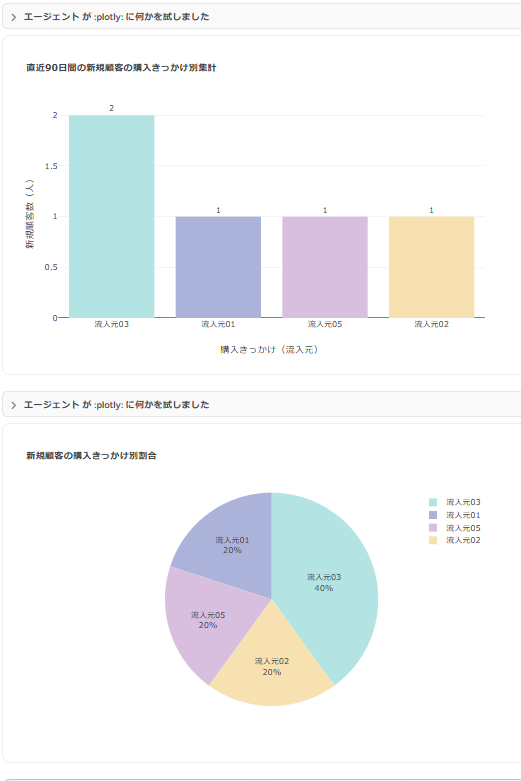
さて、最終的にエージェントが描画してくれたのがこちらのグラフです。
文章での分析レポートについてもシステムプロンプト内で指定した出力形式に沿って表示してくれています。

まとめ
今回の検証を通じて、「データを可視化する」というシンプルな要件をこなすエージェントだけでも
Task Flowでスキーマ確認を前提ステップとして組み込んだり、
Constraintsに環境固有のローカルルールや禁止事項を明記したり、、
こまごまとした工夫、調整が必要であることが分かりました。
また、汎用的なプロンプト設計の知識だけではなく、TD_INTERVALの指定漏れや日本語エイリアスによる構文エラーなど「環境特有の制約や禁止事項をプロンプトに落とし込む」という発想が、CDP上でAIを動かす際には重要だと実感しました。
AI Agent Foundryの導入をご検討している、またはすでに導入済みだが活用方法にお困りのお客様、
ぜひ一度NI+Cにお問い合わせください!