


Looker + Jupyter Notebook で Lookerモデルを操作する
投稿者:中根

Looker Advent Calendar 2019 13日目の記事です。
こんにちは、今回はLookMLで定義したデータマートをJupyter Notebook から利用してみたいと思います。
Lookerは、データハブとして動くことから単にWebUIからだけじゃなくて他の様々なツールからも使ってみたいと思うはずです。LookerはAPIが用意されており様々なことをAPIで利用する事が出来ます。これを今回は利用したいと思います。
Looker API の用意
APIが利用できるようにAPIを有効にします。 Edit Userの画面から API3Key という箇所を探します。
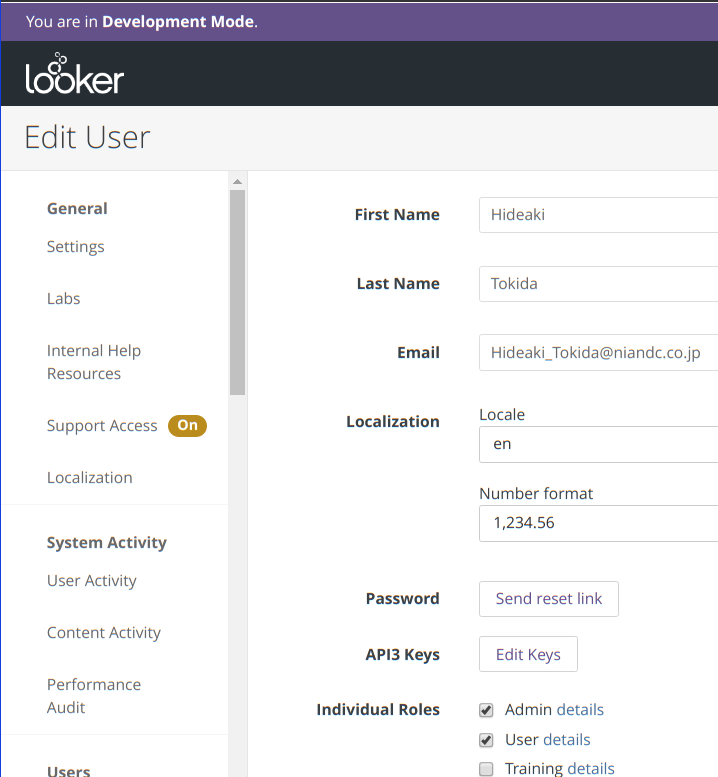
ボタンリンクになっているのでクリックするとAPIを作成する画面になります。以下の画像ではすでに作成されていますが新規に作成する場合には New API3 Key をクリックします。
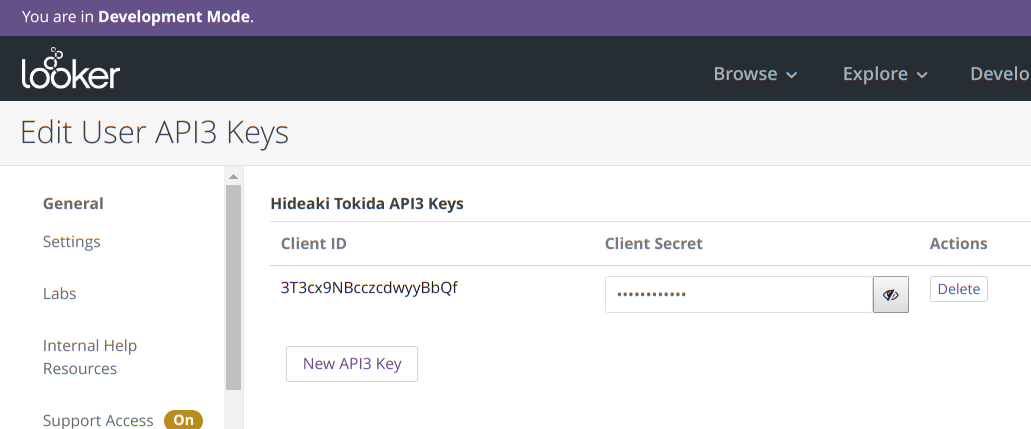
この Client ID と Client Secret を後ほど利用しますのでメモしておいてください。
Jupyter Notebook の用意
どのような環境でも問題ないのですが今回は Google Cloud Platform にある AI プラットフォームサビースの ノートブック を利用してみました。このサービスは Jupyter Notebook が導入済みのGCEインスタンスを簡単に作成してくれます。特にGPUの設定や、R/Tensorflowなどツールが導入済みの環境をワンクリックで用意できることが非常に便利です。
作成が出来ると次のような画面がでますので JUPYTERLABを開く をクリックします。

起動をするとJupyterNotebookが利用可能になります。
Looker との接続について
ググって幾つかのドキュメントを読むと python から接続するための方法を見つけることが出来ます。
- looker sdk : サクッと利用できるかと思ったのですがQueryの実行などはDocumentもないのとまだ実装されていない?のか使い方がわからなかったので RESTAPIで操作してみます。
- python api samples : こちらは多くのサンプルが用意されています。今回のプログラムもこちらを利用しても良かったような気がいましています。
今回は、一番はじめに見つけたシンプルな Notebook が合ったのでこちらをベースに行いまいた。
実施したいこと
LookMLのデータをそのまま取得しても良いのですが、今回は生データを取得したいのでLookMLで出来たQueryを生成するSQLを取得しそれをBigQueryに直接コールして後はPandasで分析するということをしてみたいと思います。
- Manual run_query を利用すると過去に実行したJobIDからSQLを取得することが出来ます。
- run_query では全件データの取得は(たぶん)出来ないと思いますがLookerの関数でも方法があればそのほうが自然だと思います。ざっと見た感じ生データを取ってこれそうになかったので今回はSQLをBigQueryに対して発行してみました。
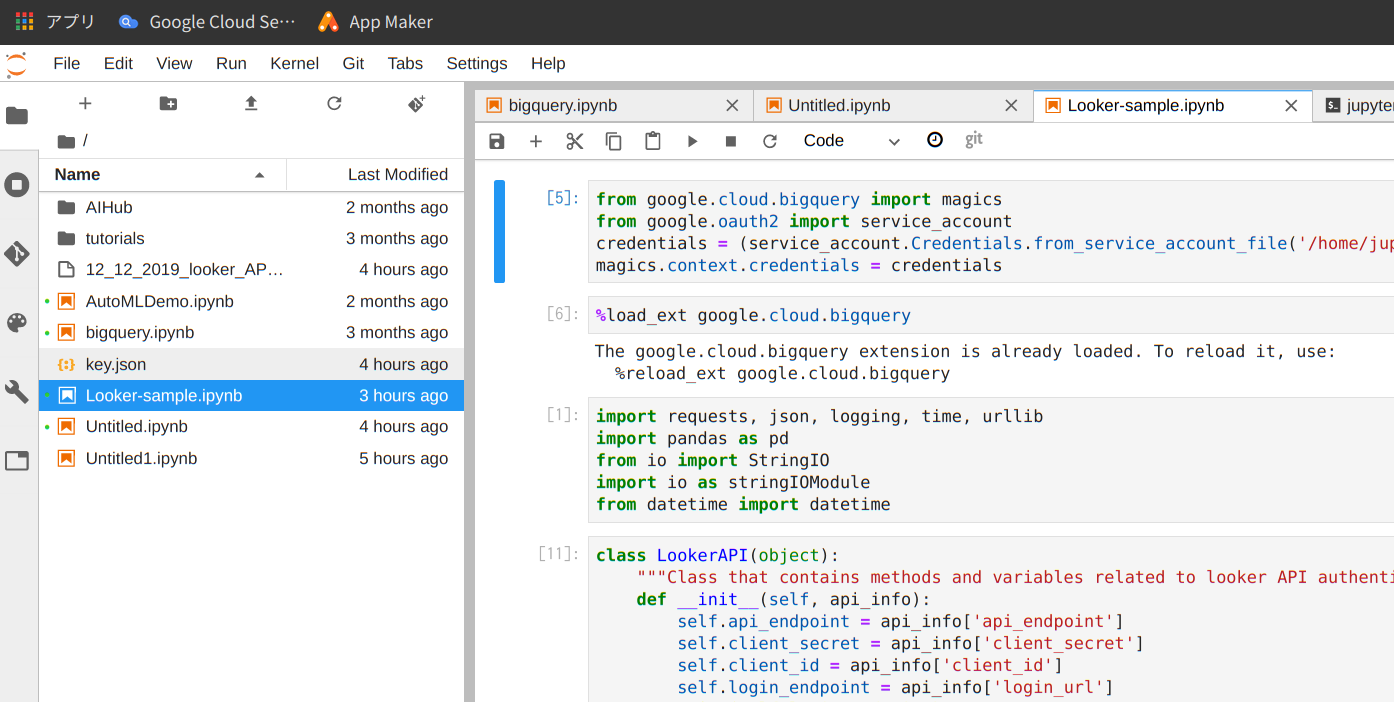
Jupyter Notebook の内容
from google.cloud.bigquery import magics
from google.oauth2 import service_account
credentials = (service_account.Credentials.from_service_account_file('/home/jupyter/key.json'))
magics.context.credentials = credentials
import requests, json, logging, time, urllib
import pandas as pd
from io import StringIO
import io as stringIOModule
from datetime import datetime
- credential ファイルは適宜アップしてください。ここでは
/home/jupyter/key.jsonとして保管されていることにしています。
%load_ext google.cloud.bigquery
- 後ほど利用するのでここでMagicコマンドを実行しておきます
class LookerAPI(object):
"""Class that contains methods and variables related to looker API authentication"""
def __init__(self, api_info):
self.api_endpoint = api_info['api_endpoint']
self.client_secret = api_info['client_secret']
self.client_id = api_info['client_id']
self.login_endpoint = api_info['login_url']
print(self.login_endpoint)
def login(self):
"login to looker API"
try:
auth_data = {'client_id':self.client_id, 'client_secret':self.client_secret}
r = requests.post( self.login_endpoint,data=auth_data) # error handle here
json_auth = json.loads(r.text)['access_token']
return json_auth
except requests.exceptions.RequestException as e:
logger.error(e)
def run_query_sql(self, query_id, json_auth, return_format='sql'):
"run query"
try:
query_run_url = self.api_endpoint + '/queries/{0}/run/{1}'.format(query_id,return_format)
#r = requests.get(query_run_url, headers={'Authorization': "token " + json_auth})
r = requests.get(query_run_url + '?' + 'access_token=' + json_auth)
return r.text
except requests.exceptions.RequestException as e:
logger.error(e)
- 参照先のWebサイトの情報と同じですが、
run_query_sql()を追加しています。Returnのフォーマットをsqlとしているだけです。
creds = {
'api_endpoint' : 'https://[my_url].jp.looker.com:19999/api/3.0',
'login_url': 'https://[my_url].jp.looker.com:19999/login',
'client_id' : '3T3cx9NBcczcdwyyBbQf',
'client_secret': 'xxxxxxxxxxxxxxxxxxx'
}
demo = LookerAPI(creds)
# Login to Instance - Return token to be used in subsequent calls.
json_auth = demo.login()
print('Token: ' + json_auth)
- api_endpoint, login_url, client_id, client_secret に対して適切な項目を記入してください。
query = demo.run_query_sql([query_id], json_auth)
print(query)
- [query_id] には、以下の画面の
Query #xxxxxx - xxで記載さ入れる番号を記入します。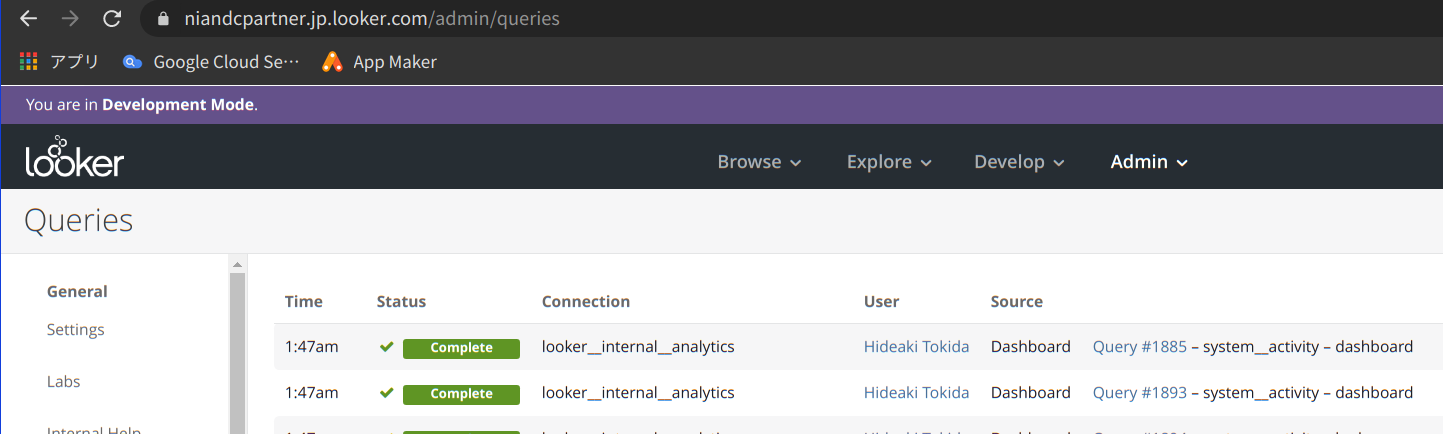
- 実際には create_query で作ったほうが良いかもしれませんが今回は実行結果から見ることにします。
- 上記を実行すると、SQLが取得できます。
これで取得すると以下のようなSQLが取得できます。
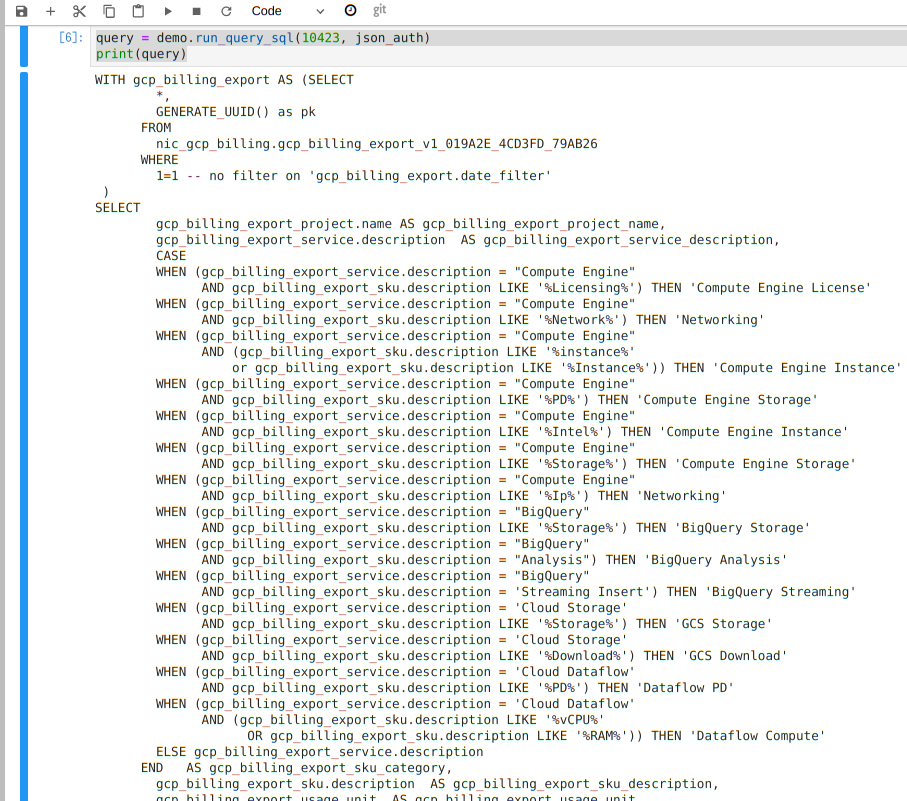
- この内容はこのままBigQueryで実行して確認することが出来ます!(素晴らしいですね。LookerはSQLジェネレータとしても良い感じのSQLを出してくているよう見えるので便利です)
%%bigquery
BigQueryで分析を開始するのに便利なのはBigQuery用のマジックコマンドを利用することです。
%%bigquery df
WITH gcp_billing_export AS (SELECT
*,
GENERATE_UUID() as pk
FROM
nic_gcp_billing.gcp_billing_export_v1_019A2E_4CD3FD_79AB26
WHERE
1=1 -- no filter on 'gcp_billing_export.date_filter'
)
SELECT
(省略)
上記の場合には df という名前の変数に、Pandasデータフレームとして結果が格納されます。(BigQueryを直接見ているときには取得するデータサイズに気をつけましょう。とはいえBigQueryも無制限にデータは取得できないので注意)
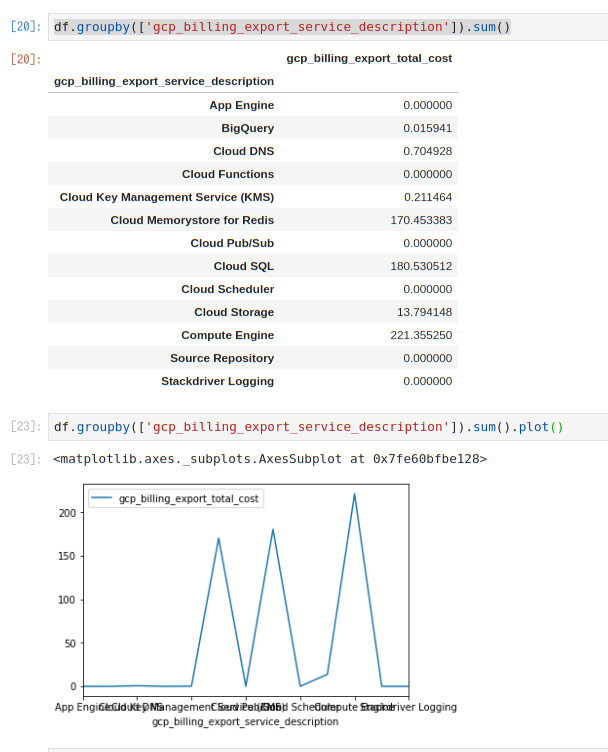
df.groupby(['gcp_billing_export_service_description']).sum()
これは、GCPの利用料金を管理してるデータマートになるのであとは慣れたJupyterで適宜利用できます。
まとめ
Lookerを利用することで、BigQueryを直接使うのではなく定義され 意味づけされた モデルを利用することが出来ます。今回はあえてSQLを取得した結果BigQueryを直接参照していますが Looker API だけで行えば完全に統制の取れた中で分析が出来ることになります。
このようにAPIを利用することでLookerが益々便利に使買うことが出来るのでこの当たりは今後も勉強していきたいと思います。
弊社では1月30日(木)に「Lookerで実現する次世代BI」と題しセミナーを行います。
BigQuery・Redshift・Treasure DataなどのCloud DBをご利用もしくは、
導入をご検討中の皆様のご参加を心よりお待ち申し上げております。
