


GCP Cloud Spannerのバックアップリストア事情とDR構成
投稿者:熊谷

こんにちは。
日本情報通信の熊谷です。
この記事ではGCPの特徴の一つである分散DBのSpannerのバックアップ事情についてまとめます。
Spannarには大きく分けて2種類のバックアップリストアがあり、今回はその2つをご紹介します。
またDRに向けた対応についても紹介します!
Spannerバックアップ事情
Spannerは20年4月17日までバックアップ機能がなく、Detaflow経由でApache Avro もしくはテキスト形式で出力する必要がありました。
しかし晴れてリリースされたバックアップ機能もリージョンの縛りがあります。(後述)
そもそも、Spannerは、シングルリージョンモデルでも3台構成のクラスタとなっており、またデータ自体がGCSに保管される仕組みになっているので、データ破損の可能性はほぼないと考えても問題ないかと思っています。
しかし、”データの破損がある想定で設計・構築する”のも我々エンジニアの仕事と考えています。
Dataflowによるバックアップ取得とリストアのイメージ
Dataflowによるバックアップ・リストアする方法はかなり前からあるため、ある種Spannerのバックアップ・リストアのスタンダードな手段として存在している印象です。
バックアップはAvro形式(もしくはテキスト)でGCSに出力する形になっています。(公式URL)
リストアも同様に、Avro形式(もしくはテキスト)でGCSから取り込むことができます。(公式URL)
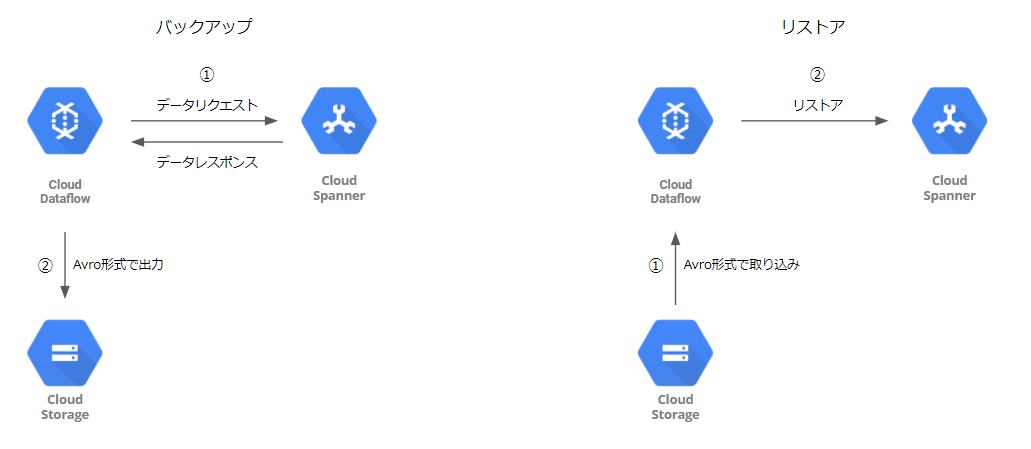
Detaflowにスケジュール機能はなく、定期的に取得するためには何かしらDetaflowのAPIをコールする機構が必要です。
DataflowによるバックアップリストアはAPIで実行できるため、異なるリージョンのSpannerインスタンスへのリストアはもちろん、IAMで適切に権限を振ることができれば異なるPJへのリストアも可能となっています。
Spannerバックアップ機能
Spannerの現時点で実施できる標準機能としてのバックアップは、テーブル単位の出力が可能です。
しかし、このバックアップはインスタンスが存在するPJ・リージョンにのみ出力可能となっています。
図のように、同じPJの中でも、東京リージョンで取得したバックアップは東京リージョンにのみリストアが可能という構成になっております。
上記でなにが問題になるかというと、DR環境を作るときのバックアップをどう持っていくかが鬼門になります。
Spannerのマルチリージョンモデル
20年6月8日に日本国内(東京と大阪)でマルチリージョン構成がリリースされています。
マルチリージョン構成は、単にDRの準備だけではなくリードレプリカが複数リージョンに配置されるため、アクセス元のロケーションから一番近いレプリカにアクセスするため、レイテンシの向上も望めます。
(データ更新のネゴシエーションには通常のシングルリージョンよりかはレイテンシがかかります。)
上記からすると、国内利用でミッションクリティカルなシステムではマルチリージョンモデル一択なのですが、利用料金が割高となっています。
東京と大阪の2つのシングルリージョンに作成した場合とマルチリージョンモデル構成を比較してみます。
まずは以下に費用の比較をします。
※720時間稼働、1インスタンス1TBを想定
| モデル | 料金 | 構成 |
| 東京大阪シングル | $2,464.8 | 東京3レプリカ大阪3レプリカ |
| 東京大阪マルチ | $3,458.0 | 東京2レプリカ大阪2レプリカ |
上記表から、マルチリージョンモデルは少々割高なことがわかります。
もちろん常時actact構成のマルチリージョンモデルの選択が好ましいのですが、費用を少しでも落とす(≒ダウンタイムを許容する)ことを検討する場合は、東京と大阪でシングルモデルを稼働させるのも手だと考えられます。
そこで、DRサイトのため、大阪のシングルリージョンモデルを災対環境と仮定し、実現する構成を考えてみます。
シングルリージョンモデルのSpannerでDRを考える
まずは構成図です。
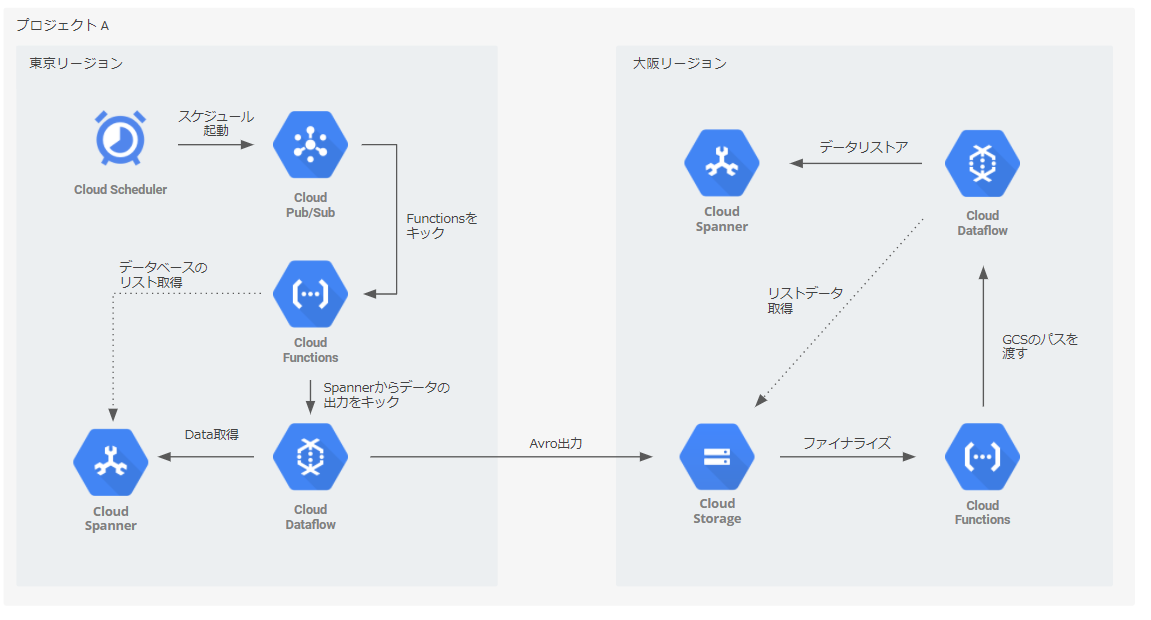
大まか流れとしてはまずCloud Schedulerでバックアップをスケジュール起動します。そしてCloud Functionsで前さばきを実施し、Cloud DataFlowによって大阪のGCSにAvroで出力をします。
この出力をCloud Functions のファイナライズトリガーで検知し、Functionsで前さばきをして、DataFlowから大阪Spannerにリストアします。
なぜバックアップ時にPub/SubとFunctions を経由するのか
GCPに慣れているひとは、Cloud Schedulerから直接Cloud DataFlowをキックしてよいのでは?と思うはずです。
なぜこの構成にしているかという観点は以下2点があります。
DataFlow APIの認証はCloud Schedulerでは通過できない
今回の構成は、Cloud DataFlowの公式テンプレートを使用しています。そのテンプレートをRestAPIでコールするのですが、Cloud SchedulerにとってRest APIの認証は少々複雑で実施できません。
https://cloud.google.com/dataflow/docs/reference/rest/v1b3/projects.templates/launch?hl=ja#authorization-scopes
そこで今回はDataFlowのRest APIを Cloud Functions経由でコールする形を取っています。
Rest APIのコールはクライアントライブラリを使用すると比較的容易です。
完璧にインターナルの構成にする
Cloud Functionsを使用する理由はRestAPIの利用をするためでしたが、Cloud Functions自体はCloud Schedulerから直接コールすることができます。
しかし、Cloud FunctionsをCloud Schedulerからコールさせるためには、Cloud Functionsをグローバル(インターネット)に公開する必要があります。
グローバルに公開した場合、不特定多数がSpannerのバックアップをコールできるようになります。
もちろんCloud SchedulerでOauth認証設定ができるので、Cloud Functions側でOauthの実装すればセキュリティレベルは向上できますが、コーディングが重くなってしまいます。
そこでPub/Subを経由することで、完璧にインターナルで実行できる構成としています。
本記事では本質ではないので詳細は割愛しますが、以下の点を考慮することでインターナルでのコールを実現できます。
・サービスの境界(Access Context Manager) ※使用には組織が必要です。
・サービスアカウント
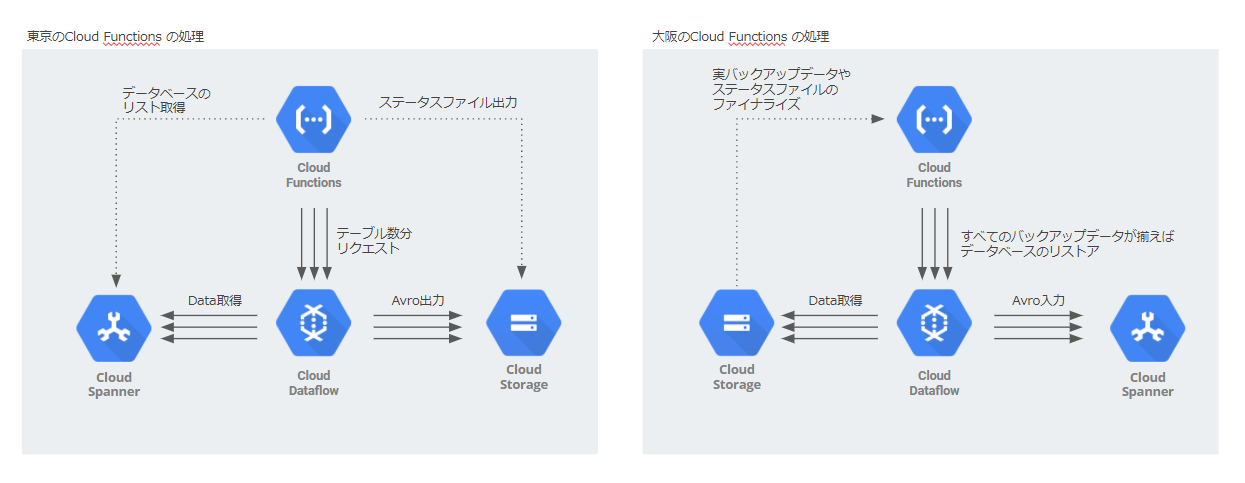
Cloud Functionsの役割
サマリの説明で、”前さばき”という言葉を使いました。Cloud Functionsは東京と大阪の2拠点に存在していますが、それぞれの処理の内容を以下にまとめます。
東京のCloud Functions
Cloud DataFlowのテンプレートでは、1度のリクエストで取得できるSpannerのデータは、データベース単位になります。
そのため、複数のデータベースが存在する場合はデータベース数分のリクエストが必要です。
Cloud DataFlowのコードを書き換えられれば問題ないのですが、今回はCloud Functions側でSpanner のAPIからデータベースのリストを取得します。
大阪のCloud Functions
こちらの処理のメインは、”バックアップファイルが全て揃ったタイミングでリストアを実行”になります。
“東京のCloud DataFlowから出力されるデータの順番”と”GCSのファイナライズ”に順序的な担保はできません。
そこで、東京のCloud Functionsで処理のステータスファイルをGCSに出力するようにします。
大阪のCloud FunctionsでそのStatusファイルをもとに、すべてのデータが揃ったかの確認をし、すべて揃った場合にCloud Detaflowをコールする形にしています。
まとめ
以上がSpannerのバックアップ・リストア事情とDR構成となります。
Spannerは可用性が高く信頼できる構成ですが、ミッションクリティカルなシステムの場合ではバックアップ・リストア構成DRは必須です。
価格との相談になりますが、マルチリージョンモデルとシングルリージョンモデルの選択を考え、またDRを考えた構成を検討できればと思います。
本記事ですべてを語ることはできていませんが、Spannerの活用・運用について相談があるかたは弊社までご連絡ください。