


GCPで始めるデータ分析と活用 概念編:データエンジニアリング
投稿者:熊谷

GCP(Google Cloud Platform)ではデータ分析に必要なコンポーネントが非常によく揃っています。
今回はいくつかあるGCPのコンポーネント中で、何をどう使えばいいかの説明ができればと思います。
本ブログを見て、”データの活用を考えてみよう!”または”一緒に考えたい!”と思っていただける方がいらっしゃると幸いです。
データ活用の枠組み
まず、昨今考えられているデータの活用についてまとめてみます。
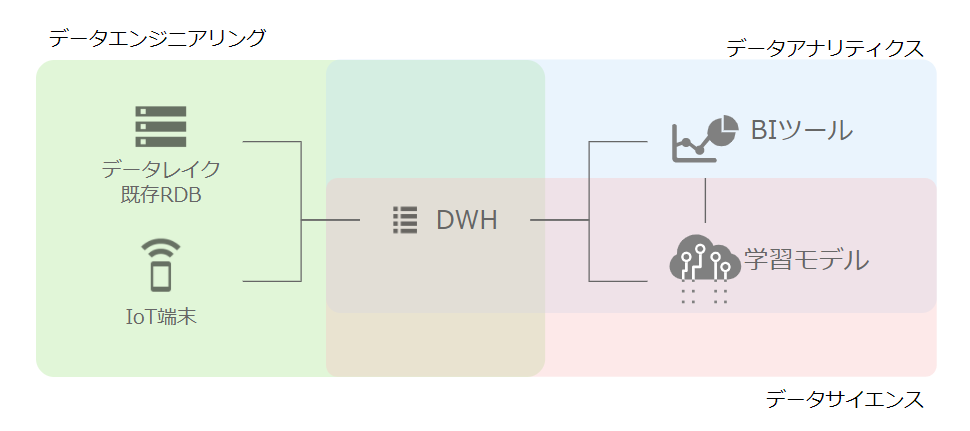
この図のように上流からデータエンジニアリングを経由し、データアナリティクス、データサイエンティストと繋がります。
それぞれを少しブレークダウンしてみます。こちらでまとめた役割ですが、会社や組織によって変わってきますので詳細は所属している環境に応じてご確認ください。
データエンジニアリング
データの活用の前さばきを行います。アナリティクスやサイエンスにつなげるために、データの収集・加工・格納を主に行います。また、サイエンスの範囲として機械学習の分野が入ることもあります。
各事業部やデバイスに散らばっているデータを収集方法を設計し、実際に活用できるデータの形に揃えるまでが主な守備範囲となります。そのため後述のETLやデータウェアハウスの構築をすることになります。
また、データ活用のアーキテクチャとして、ビックデータでは以下の3つのVが重要だと言われています。

Variety(種類)
RDBに格納されているような構造化データではなく、画像や音声、文章などがデータ分析の対象になっています。データエンジニアリングはデータの種別に関わらず、どのようなデータも活用できるアーキテクチャを考える必要がありあます。
つまりは、データの種別によって柔軟な格納先を検討し、格納したデータの活用方法をアナリティクス、サイエンスと連携しなければなりません。
Volume(容量)
扱うデータの種類が増え、取り扱う期間が長いだけ容量が増えてきます。オンプレミスのサーバでは、容量増加に物理的危機の拡張が必要なため、時間を要します。また初期構築段階で、スケールを前提としたアーキテクチャ設計が必要になります。
いざデータ格納の運用を始めたが、データ量が多く、頻繁なメンテナンスでシステムがダウンするようでは満足にデータ活用ができません。
昨今のクラウドでは、データ量に応じてクラウド事業者がダウンタイムなしにスケールを実施する”フルマネージドサービス”が増えています。そのようなフルマネージドなサービスを適切に選択するのもデータエンジニアのミッションとも言えます。
データサイズはテラバイト級ではなく、ペタバイト、ゆくゆくはエクサバイトにもなってくるかもしれません。
Velocity(頻度)
情報は生モノとはよく言いますが、データ活用のリアルタイム性も重要視されています。これまでは、ある期間のデータをバッチで集計・分析していたことが多いかと思いますが、これからはリアルタイムが求められることが増えることが予想されます。
例えば、業務車両の車載IoTデバイスからのデータをリアルタイムに分析し、最適経路や自己予測に活用されることが予想されます。 他の例だと、動画提供サイトにて、視聴者の属性を分析し、視聴者に特化した広告を表示することが考えられます。リアルタイム性が高くなればなるほど即時性が高くなり、データ分析の結果を得られやすくなります。
データアナリティクス
データを溜めておくだけでは意味がありません。データアナリストはその溜まったデータから、活動の意思決定を支援します。
スキルとしては基本的な統計知識に加え、最近ではPythonやRなどのプログラミング言語やSQLが使えるとより幅が広がります。
加えて、ビジネスインテリジェンスツール:BIツールなどを通じてデータを可視化もスキルとして求められることがあります。可視化を通じ洞察を得られやすく、また経営層へのレポーティングなどに使われます。データをCSV等で出力して眺めるだけでは見えてこない関係性を見つける用途になります。
また、データから機械学習の元ネタを考え学習モデルを作成ようなデータサイエンティストの側面が求められることがあります。
データサイエンティスト
データから現状を把握するだけではなく、過去データから起こりそうなことを予測したり、これまで人がやっていたことを代替することを考えることでデータを十分に活用できたと言えます。
データサイエンティストはデータアナリストと連携し、効果的な学習モデルや予測モデルを作成することがメインミッションとなります。そのため、AI・機械学習・ディープラーニングの知識が必須となります。
パブリッククラウドには、GUIで完結できるものもありますが、Pythonによって学習モデルを作れたほうが幅が広がります。そのほか、SQLも必要なります。
データを揃える
これまでの3つの分野の説明から、データを共通物として扱うことが大切になってくることが見受けられます。データエンジニアは使いやすいデータを溜め込み、データアナリストとサイエンティストはそのデータを共通言語として扱います。
ここからデータの保管場所:データレイクとしてデータウェアハウスと、使いやすいデータへの変換について触れます。
データウェアハウス:DWH
ここまで全くGCPのネタをかけてなくて申し訳ございません。。ここからでてきます。
データウェアハウスは端的に表現すると、データの抽出・集計に特化したRDBです。
分析するデータを抽出・集計のレスポンス時間を数秒ないしは数分程度で返せられることが理想です。
GCPのDWHとしては、BigQueryが上げられます。また利用用途によってはBigtableというサービスもあります。
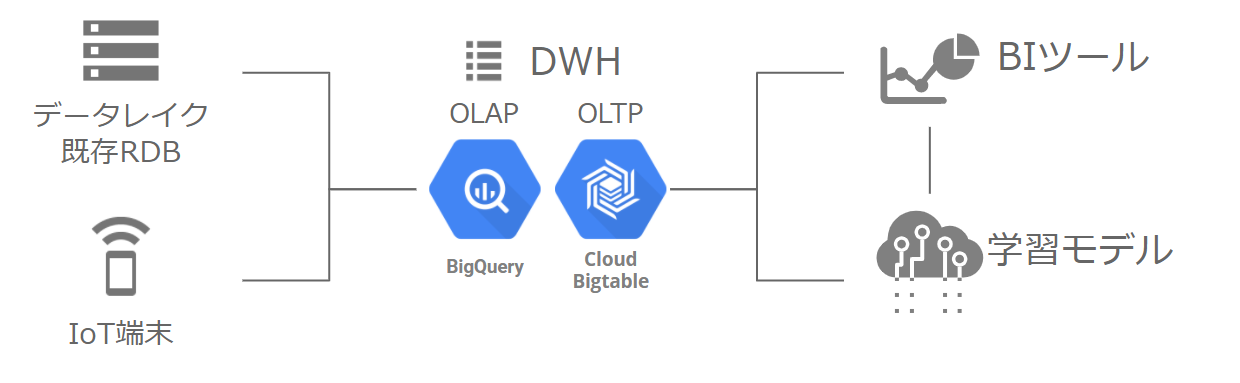
GCPのキラーコンテンツ BigQuery
パブリッククラウドで差別化する要素を考えるのはかんたんではないですが、GCPの最大の特徴と言っても過言でないのがBigQueryです。
OLAP(オンラインアナリティカルプロセッシング)に分類されるBigQueryですが、ペタバイト規模のデータに対するスケーラブルな分析ができる、フルマネージドのサーバーレスデータウェアハウスです。(もう盛りだくさんですね。)
BigQueryは、データの保管や処理に上限がなく、ダウンタイムがない拡張が可能で、しかもGoogleが基盤を運用してくれています。またデータ容量に制限がないだけではなく、CPUやメモリといったコンピュートも分散されており、重たく時間がかかる処理であっても複数台のサーバで処理をするため、抽出や集計結果が早く得られます。
しかし、分散処理をしているため、少量のデータに対する抽出であっても数秒かかることはBigQueryの特性とも言えます。
また、BigQueryは列指向DBMSとなっており、従来RDBの行指向とは違い抽出に長けています。 技術的にはSQL on Hadoopを使用しており、joinといった結合も可能です。
データアナリティクスやデータサイエンティストが即座にほしい情報を抽出できることはかなり嬉しいことです。弊社事例で恐縮ですが、終わらなかった処理がBigQueryを使用するとたった10秒!で検索結果を取得できる事例もあります。BigQuery活用事例
爆速 Bigtable
先程紹介したOLAPと対比されるOLTP(オンライントランザクションプロセッシング)に分類されるのがBigtableになります。BigtableはNoSQLに属し、キーバリュー型でこちらも列指向DBMSになります。また、Bigtableもデータ容量に上限はなく、スケーラブルなサービズになります。
BigQueryとの大きな違いは、抽出はどんなにデータが多くとも10ミリ秒以下で応答する速さ、トランザクションがある、データのリレーションがなく結合(join)もできない点になります。
Bigtableが得意なことは即時性が求められる金融の処理や分析、時系列情報が重要になるIoTデバイスの情報の取り扱いになります。
リレーションが無いため厳密にはDWHにはならないのですが、Bigtableのスケーラブルで高速レスポンスを活用できるかはデータエンジニアの腕のみせどころとなります。
その他のデータ格納
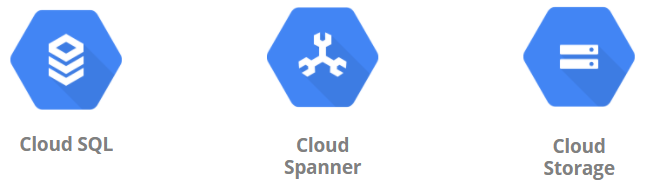
GCPにはBigQueryやBigtable以外にもデータを格納するサービスがあります。
従来のRDBであるMySQL等のマネージドサービスのCloud SQLや分散DBのCloud Spannerがあります。DWHとしてリレーションとトランザクションを両立したい場合は、こちらを選択することになります。もちろん、オンプレミスとGCPを専用線やVPNで接続することも可能です。
テキストデータや画像、音声データは、AWSのS3のようなオブジェクトストレージである、Google Cloud Storage:GCSに保管します。GCSに格納されたCSVやJSONはBigQueryからクエリを発行することも可能です。
データの抽出・変換・格納:ETL
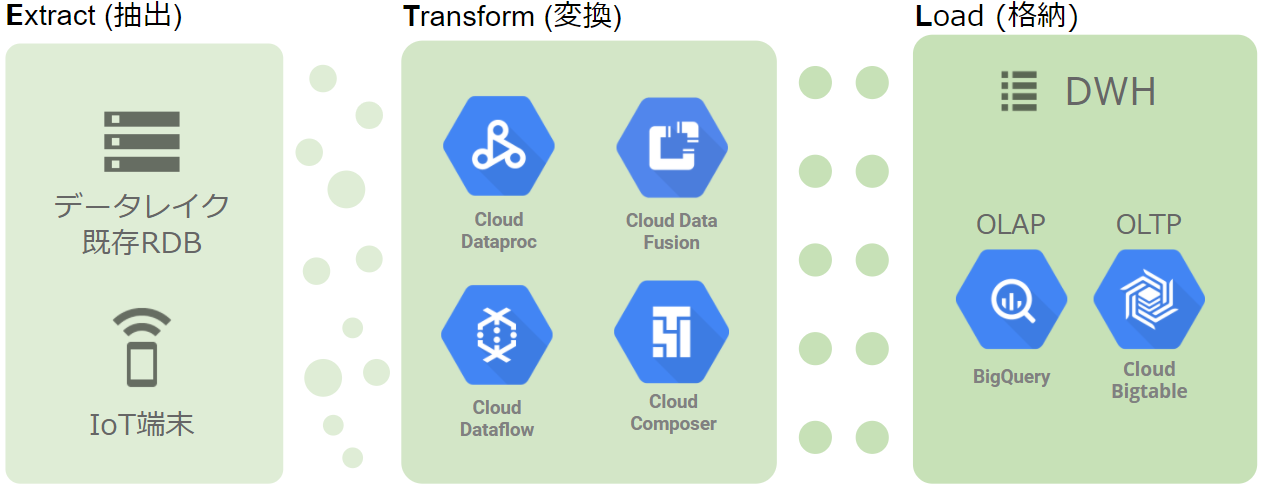
さて、データの保管場所であるDWHの説明をしましたが、じゃあデータを貯める方法はどうなの?と思う方もいるかも知れません。
そこでデータを格納する方法や、データアナリティクスやデータサイエンティストが使いやすいデータにする変換をここで触れます。
章タイトルからETLの3アルファベットが使われていますが、それぞれ同じ意味を表しています。
・E : Extract (抽出)
業務DB等アナリティクスを考えて作られていない、または各所に溜まっているサイロ化したデータを取得するイメージになります。
・T : Transform (変換)
フォーマットがバラバラなデータを整形します。かんたんな例だと、型変換や、タイムゾーンの一致などにあたります。
・L : Load (格納)
DWHにデータを格納することです。
GCPコンポーネントでマッピング
ETLは概ね1つのツールで実施されます。GCPでは以下のリストの種類があります。
それぞれの特徴も含めてまとめます。
どれを選択すればよいかは、本記事で述べるにはボリュームが多くなりますので、弊社までご相談ください。
(今後各サービスの記事をあげる予定です)
| 名称 | 概略 | 得意 |
| Data Proc | マネージド Spark / Hadoop |
既存でSparkやHadoopを使用しているならクラウドへのリフトがしやすい。 |
| Data Fusion | GUIでデータパイプラインを 構築できるツール |
データパイプラインをGUIで定義し、実際の処理はDeta Procで実行される。 |
| Data Flow | マネージドのApache Beam | BeamはBatchとStreamingを合わせた造語。IoTデバイスから継続して送られてくるストリーミングデータの処理が得意 |
| Cloud Composer | マネージドのApatche Airflow | dagと呼ばれる有向非巡回グラフによってデータフローを定義し、依存関係を持った処理が可能 |
まとめ
いかがでしたでしょうか。
本ページではGCPで始めるデータ分析と活用の概念において、データエンジニアリングの守備範囲についてまとめました。
データエンジニアリングは、データを”貯める、加工する、使えるように提供する”ことを設計構築する役割になります。
続いてはその”使えるデータ”を活用するデータアナリティクス/サイエンティスト編になります。
・GCPで始めるデータ分析と活用 概念編:データアナリティクス/サイエンティスト
今後各GCPコンポーネントの使い方等をまとめていければと思いますが、より詳しい情報は以下のボタンからお問い合わせください。