


BigQuery MLでお手軽に購買データをRFM分析して、可視化してみた その①
投稿者:山本 仁一

初めに
クラウドイノベーション部の今井です。
今回は BigQuery ML を用いて購買データから RFM 分析を実施し、その可視化を DataPortal にて実施してみたいと思います。
本テックブログはこちらの記事を参考に作成しています。
その①(本記事)では BigQuery ML を用いて購買データから RFM 分析を実施するところまで行います。
その②では DataPortal での可視化を行います。
背景
今回のブログの背景としては、新人エンジニアの私が難しそうな顧客分析を Google Cloud 上でお手軽に行うことは可能かを検証することが大前提としてあります。
私は今まで顧客分析や機械学習を行ったことはありませんし、今までの案件の中でも SQL や Javascript での Web アプリの改修、 Python でのスクリプト作成などしか経験していません。
その私が、はたして顧客分析をお手軽に機械学習を組み合わせて行うことはできるのかを試していきたいと思います。
BigQuery ML とは
BigQuery ML (以下、BQML)とは Google Cloud のサービスの一つである BigQuery 上で Machine Learning を実施するサービスです。
公式ドキュメントには、以下のように記載されています。
BigQuery ML は、SQL 実務担当者が既存の SQL ツールやスキルを使ってモデルを構築することを可能にし、機械学習をより多くの人が利用できるようにします。
BigQuery ML ではデータを移動する必要がないため、開発スピードを向上させることができます。
RFM 分析とは
RFM 分析とは顧客の購買行動によってグループ分けを行い、そのグループごとの性質に合わせたマーケティング施策を実行していくために行う分析手法の一つです。
今回はグループ分けの部分を BQML で行います。
今回のブログの主題は RFM 分析ではありませんので、分析の詳細を知りたい方は Google 検索などを行うようにしてください。
私よりも詳しく説明しているページが存在しています。(このようなページがあります)
今回は購買データから、 recency , frequency , monetary の 3 要素を作成し、その 3 要素を使ったクラスタリングを BQML で行う流れで進めます。
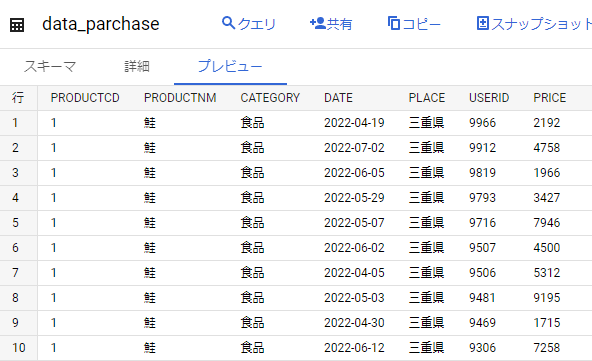
用意した購買データについて
BigQuery に以下のようなテストデータを用意しました。
SQLの実行について
このテストデータに対して以下の SQL を実行します。
with combinedtable as (
select
maintable.USERID,
maintable.DATE,
recentdate.recent_date,
sum(maintable.PRICE) as amount,
count(maintable.USERID) as totalevents
-- ご自分のプロジェクト名とデータセット名に変更してください
from プロジェクト名.データセット名.data_parchase as maintable
join
(
SELECT
USERID,
max(DATE) as recent_date
-- ご自分のプロジェクト名とデータセット名に変更してください
from プロジェクト名.データセット名.data_parchase
group by 1
) as recentdate
on maintable.USERID = recentdate.USERID
group by 1,2,3
),rfm as (
select
USERID as user_id,
DATE_DIFF(current_date(),recent_date,day) as recency,
count(USERID) as frequency,
sum(amount) as monetary
from combinedtable
group by 1,2
order by recency
)
select * from rfm
上記の SQL を実行し、集計されたデータを「data_parchase_rfm」というテーブルとして保存します。
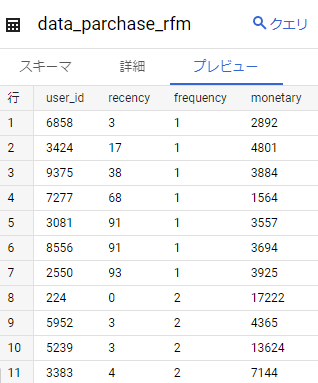
こちらのテーブルに対して、 BQML の機械学習モデルの一つである K 平均法クラスタリングを実施します。
以下の実質 7 行の SQL を実行することで、機械学習を行います。
-- ご自分のプロジェクト名とデータセット名に変更してください
CREATE OR REPLACE MODEL プロジェクト名.データセット名.RFM_Model
OPTIONS(
model_type='kmeans',
num_clusters=5,
standardize_features = true
) AS
-- ご自分のプロジェクト名とデータセット名に変更してください
select * except (user_id) from プロジェクト名.データセット名.data_parchase_rfm
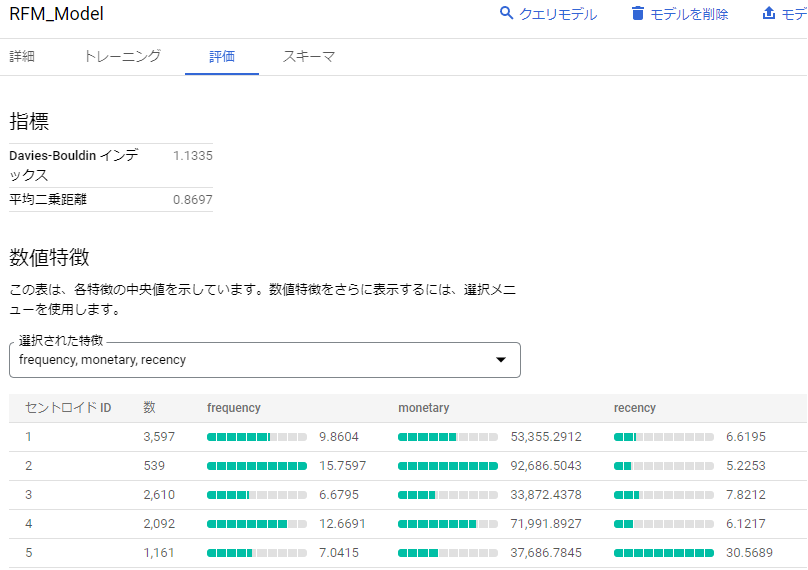
上記の SQL を実行し、作成されたモデルは「RFM_Model」という名前で保存されます。
結果として、ユーザーを 3 つの要素から以下のような 5 つのクラスタに分割するモデルが作成されました。
上記モデルと data_parchase_rfm を組み合わせるため、ユーザーに対してどのクラスタに属しているかの情報を付与する 以下の SQL を実行します。
with rfm as (
select *
from `vi-ct-imai-training.bi_test.data_parchase_rfm`
order by recency desc
)
select
case
when CENTROID_ID = 1 then 'Segment 1'
when CENTROID_ID = 2 then 'Segment 2'
when CENTROID_ID = 3 then 'Segment 3'
when CENTROID_ID = 4 then 'Segment 4'
when CENTROID_ID = 5 then 'Segment 5'
end as segments,
* except (nearest_centroids_distance)
FROM ML.PREDICT(MODEL `vi-ct-imai-training.bi_test.RFM_Model`,(select * from rfm))
上記の SQL を実行し、集計されたデータを「data_parchase_kmeans」というテーブルとして保存します。
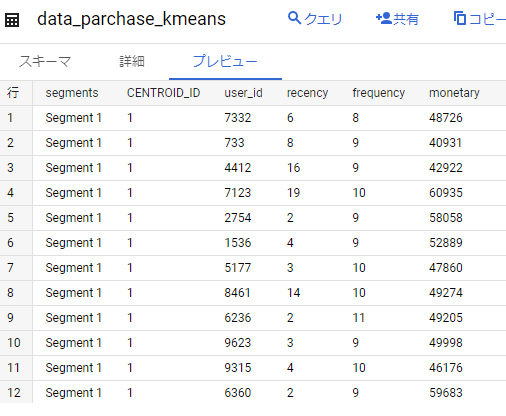
その①の終わりに
上記テーブルを利用して、その②では DataPortal で可視化を実施します。
よろしくお願いいたします。