


【IDMC】ディクショナリ機能を活用してクレンジング処理を実行してみた!
投稿者:金子 侑司
はじめに
皆さん、こんにちは。NI+C DataOpsチームの金子です。
皆さんはデータ準備に利用するETLツール製品を使用してデータ利活用に取り組まれていると思いますが、データ品質面に課題があり、データ分析やデータの可視化が思うように進められていないという方も多くいらっしゃるのではないかと思っています。
例えば、「株式会社」と「(株)」の表記や電話番号等のフォーマットが異なりデータの整合性に欠ける事がデータ品質の問題として挙げられます。
そこで今回はデータ品質の改善方法の1つとして、IDMC(Intelligent Data Management Cloud(以後IDMC(旧IICS))のディクショナリ機能を利用したクレンジング処理をご紹介します。
本ブログでは「クレンジング」という用語が異なる意味合いで存在するため、以下の表現の通りとします。
IDMCの部品(アセット)名称:クレンジング(アセット)
変換/加工処理:クレンジング(処理)
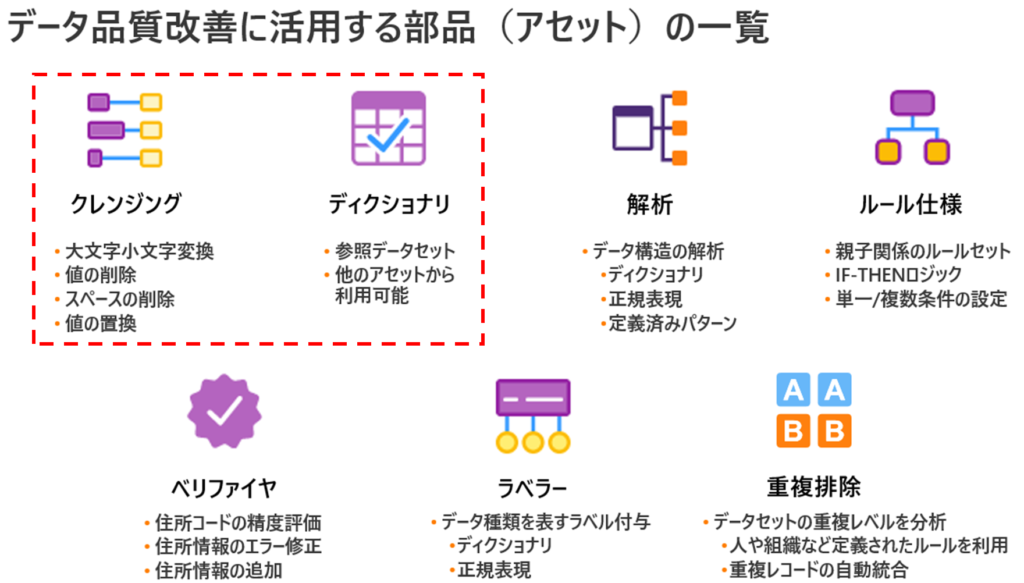
1.本ブログにて活用するデータ品質改善に関する部品(アセット)
今回は以下のデータ品質改善に関する部品(アセット)を活用して「クレンジング(処理)」処理を実施していきます。
1.1.クレンジング(アセット)とは
文字列や記号を修正し揃えることで、データを標準化する機能です。
1.2.ディクショナリとは
大規模な情報システムでデータの一貫性や整合性を保つために、意味や表現をデータソース間で共通化し一覧として管理する機能です。
2.本ブログにて実施する「クレンジング(処理)」処理の概要
今回は以下の流れでデータソースの会社名カラムに発生している表記ゆれを修正します。
(修正前) (修正後)
(株)、(株)、㈱ → 株式会社
(有)、(有)、㈲ → 有限会社
本ブログにて実施する「クレンジング(処理)」処理のイメージは以下となります。
※本検証ではサンプルデータを利用しています。

①データの確認
:GCS(Google Cloud Storage)に格納されたクレンジング(処理)前のcsvファイルに対してプロファイリングを実行する
②ディクショナリの定義
:ディクショナリ(辞書)を作成し共通化したい一覧を定義する
③作成したディクショナリを利用する変換方法の定義
:②で作成したディクショナリ(辞書)の変換方法をクレンジング(アセット)に定義する
④マッピングの定義と処理の実行
:マッピングを定義し実行する
⑤データの確認
:GCS(Google Cloud Storage)に格納されたクレンジング(処理)後のcsvファイルに対してプロファイリングを実行する
3. ディクショナリ(辞書)機能を利用して「クレンジング(処理)」処理を実施
実際にディクショナリ(辞書)機能を利用して「クレンジング(処理)」処理を実施していきます。
3.1 GCS(Google Cloud Storage)に格納されたクレンジング(処理)前のcsvファイルに対してプロファイリングを実行
プロファイリング機能とはデータ品質の確認やデータのプレビューを確認することができます。
プロファイリングはマイサービスの「データプロファイリング」から作成できます。

サンプルデータを取り込みプロファイリングを実行したデータプレビュー画面になります。
データプレビュー画面から会社名カラムに(株)、(株)、㈱、(有)、(有)、㈲の表記が存在していることが確認できます。
こちらの表記ゆれをディクショナリ(辞書)機能を活用して修正していきます。

3.2 ディクショナリ(辞書)を作成し共通化したい一覧を定義
ディクショナリ(辞書)はマイサービスの「データ品質」から作成できます。

ディクショナリ(辞書)を作成するにあたって、まず定義タブの「名前」、「説明」を入力します。
※今回は「タグ」を使用しませんが、タグを利用することにより様々なアセット(テーブル、フィールド等)を管理し、アセットを簡単に検索・識別することができます。
※グレーアウトしている項目は自動で入力される項目です。

次に設定タブにてクレンジング(処理)後の単語と表記ゆれが発生している単語を手動で項目に入力します。
1行目のカラム1~4には表記がゆれている株式会社の単語を全パターン入力します。
2行目のカラム1~4には表記がゆれている有限会社の単語を全パターン入力します。
※CSVファイルをインポートすることも可能です。
最後に作成したディクショナリ(辞書)を保存します。

3.3 上記3.2.で作成したディクショナリ(辞書)の変換方法をクレンジング(アセット)に定義
クレンジング(アセット)はマイサービスの「データ品質」から作成できます。
クレンジング(アセット)を作成するにあたって、まず定義タブの「名前」、「説明」を入力します。
※今回は「ディメンション」を設定しませんが、ディメンションを利用することによりデータ品質チェックの6つの評価軸(正確性(Accuracy)、有効性(Validity)、完了度(Completeness)、一貫性(Consistency)、一意性(Uniqueness)、適時性(Timeliness))から指定する事ができます。
Cloud Data Governance & catalog(CDGC)という機能を利用してカタログ化する際に視覚化して把握し易くする事ができます。
※グレーアウトしている項目は自動で入力される項目です。

次に設定タブにて「クレンジング(処理)」処理内容を定義します。
ステップシーケンスのステップに「値の置換」、オプションに作成した「dic_会社リスト」を選択します。
ステップのプロパティのモードに「入力値をディクショナリ値で置換」、ディクショナリに先ほど作成した「dic_会社リスト」、有効なカラムに「カラム1」を設定します。
これらの設定によって、カラム1の「株式会社」、「有限会社」にカラム2の「(株)」、「(有)」カラム3の「(株)」「(有)」カラム4の「㈱」、「㈲」が置換されます。

その他プロパティの「大文字小文字」、「区切り文字」、「スコープ」はデフォルト値とします。
※「クレンジング(処理)」処理の動作をテストし処理結果を確認することができます。
クレンジング(入力 (アセット))に置換したいデータを手動入力もしくはcsvファイルをインポートし、テストを押下するとクレンジング(出力 (アセット))にテスト結果が表示されます。
下図では想定通りに(株)リアンと(有)アドニスが「株式会社リアン」と「有限会社アドニス」に置換されているため、テスト完了です。

マージタブでは2つ以上の入力データを1つにマージすることができますが、今回クレンジング(処理)結果はマージせず出力するためデフォルトのままとします。
最後に作成したクレンジング(アセット)を保存します。

次は作成したディクショナリ(辞書)を活用して「クレンジング(処理)」処理を実施していきます。
3.4 マッピングを定義し実行
今回「クレンジング(処理)」処理を実施するにあたって、IDMCのマッピング機能を利用します。
マッピングとはデータの抽出、変換、送出(ETL)処理を行うことができる機能であり、データ統合プロセスの中心的な要素となります。
マッピングはマイサービスにある「データ統合」から作成できます。

今回は上記「2.本ブログにて実施する「クレンジング(処理)」処理の概要」の処理イメージ図に記載しているマッピングの「ソース」、「クレンジング(アセット)」、「ターゲット」の3つの部品を使用して「クレンジング(処理)」処理を実行します。
「ソース」ではGCS(Google Cloud Storage)に格納されたクレンジング(処理)前のcsvファイルをソースとして抽出する処理を実施します。
「ターゲット」ではターゲットのGCS(Google Cloud Storage)にクレンジング(処理)後のcsvファイルを送出する処理を実施します。
「クレンジング(アセット)」ではデータ品質のクレンジング(アセット)アセットに基づいて、データの形式などを標準化することができます。
今回は3.3にて事前に作成したディクショナリ(辞書)「dic_会社リスト」を定義したクレンジング(アセット)「cln_会社リスト」に基づいて、以下のように値を修正します。
(修正前) (修正後)
(株)、(株)、㈱ → 株式会社
(有)、(有)、㈲ → 有限会社

クレンジング(アセット)タブにて作成した「cln_会社リスト」を選択します。



今回その他の「受信フィールド」、「フィールドマッピング」、「出力フィールド」及び「詳細」のタブはデフォルトのまま設定します。
受信フィールド:ソースから受信するフィールド
フィールドマッピング:異なるデータソース間のデータカラムをマッピングする
出力フィールド:ターゲットへ送出する「クレンジング(処理)」処理後のフィールド
詳細:ログに出力されるエラーメッセージ並びにステータスのレベル設定
マッピングの設定を保存し実行します。
マイジョブからマッピングが成功していることを確認できます。

3.5 GCS(Google Cloud Storage)に格納されたクレンジング(処理)後のcsvファイルに対してプロファイリングを実行
「クレンジング(処理)」処理が実施されたcsvファイルのデータをプレビュー画面から確認すると会社名カラムに存在していた「(株)」、「(株)」、「㈱」が「株式会社」に、「(有)」「(有)」「㈲」、が「有限会社」に置換されていることが確認できました。

また、クレンジング(アセット(cln_会社リスト))の「有効なカラム」を「カラム4」に設定を変更し「クレンジング(処理)」処理を実行した結果、「(株)」、「(株)」、「株式会社」が「㈱」に、「(有)」、「(有)」、「有限会社」が「㈲」に置換されていることが確認できました。
そのためディクショナリ(辞書)に値の置換パターンを複数用意し、クレンジング(アセット)の「有効なカラム」を用途に合わせて変更することで「クレンジング(処理)」処理の使い分けができます。


4.まとめ
私が実際にディクショナリ機能を活用し「クレンジング(処理)」処理を実行してみた所感として、GUI操作のみでデータプレビューの確認から「クレンジング(処理)」処理まで行えるので、ユーザー部門の方でも触りやすく直感的にデータ品質を改善していけると感じました。
「クレンジング(処理)」処理はデータの整合性によるデータ品質課題を解消するにはとても有効な手段です。
データの整合性確認を目視でチェックしデータ修正を手直ししている場合、人的ミスによるデータ品質の低下に繋がりますが、
今回のように「クレンジング(処理)」処理を実行することでデータ品質は向上し、原因究明や修正に関する時間とコスト削減に繋がります。
また、データ品質が向上することによりデータ分析の精度が高まり、迅速かつ正確なビジネス判断を可能にします。
つまり、『データ品質改善』はデータ利活用をより活性化させるための必須要素であり、そのためには『クレンジング処理』は欠かせない機能だと、私は考えております。
弊社ではIDMCを活用した「クレンジング(処理)」処理やその他さまざまなETL/ELT処理のご支援が可能です。
PoCや本番環境構築など、お気軽にご相談下さい。