S3 SelectとAWS Athenaを使用してS3からデータを抽出してみた
投稿者:門倉
こんにちは、NI+C AWSチームの門倉です。
今回は、S3からのデータ抽出方法について整理してみました。
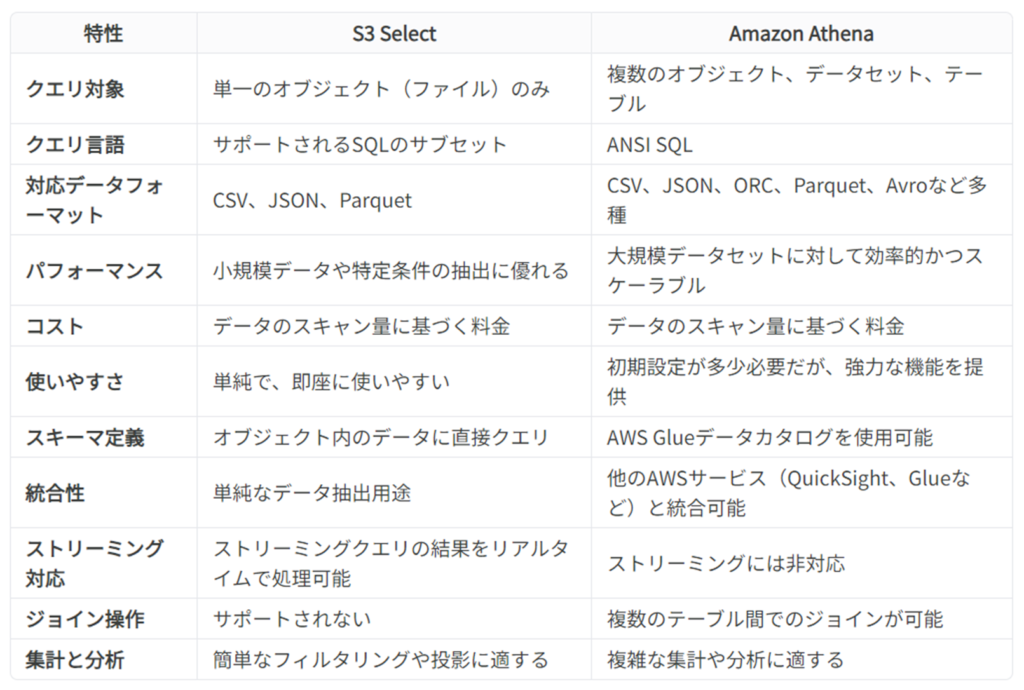
複雑なクエリを行えるのが「Athena」で、単一のオブジェクトに対して簡単なクエリを実行できるのが「S3 Select」というぐらいの認識しかなかったのですが、特徴などについてまとめてみました!
はじめに
Amazon S3 Selectとは?
特徴
- 目的: 個々のオブジェクト(一つのファイル)に対してクエリを実行し、データ全体ではなく必要な部分だけを取得する。
- 対応フォーマット: CSV、JSON、Parquet。
- パフォーマンス: 小規模データセットや特定のデータ抽出に対して非常に高速。
- コスト: データスキャン量に基づく料金。特定のデータのみを取り出すため、不要なデータのスキャン量を減らせる場合にコスト効率が良い。
適用シナリオ
- 大量のデータから特定のレコードやフィールドのみを取得したい場合。
- 簡単なフィルタリングを行う場合。
- データを事前に処理したり、部分的に取得して、アプリケーション内でさらに処理する場合。
利用例
- 特定顧客の注文履歴をCSVファイルから抽出する。
- 特定のキーに基づいてJSONファイルからレコードを取得する。
Amazon Athenaとは?
特徴
- 目的: S3に保存された構造化データ、半構造化データに対して完全なSQLクエリを実行。
- 対応フォーマット: CSV、JSON、ORC、Parquet、Avroなど多くのデータ形式に対応。
- パフォーマンス: 大規模なデータセットや複雑なクエリに対しても効率的。特にデータ量が大きい場合に分散処理されるため高速。
- コスト: クエリ実行時のデータスキャン量に基づく料金だが、クエリ結果の保存や他のサービスとの連携には追加費用が発生する場合もある。
適用シナリオ
- 複数のデータセットを統合してクエリを実行する場合。
- 複雑なSQLクエリや結合操作を行う場合。
- データ分析やレポーティングのために大規模なデータセットを扱う場合。
利用例
- 異なるテーブル間での結合クエリを実行し、販売データと顧客データを組み合わせて分析する。
- データウェアハウスの一部としてS3に保存されたデータに対して定期的な分析クエリを実行する。
選択のポイント
基本的に業務で使用する場合、障害時のデータ調査であったり、開発前のデータ調査で使用することが多いです。
例えば、開くのも大変なぐらいの大容量の単一ファイルから、ある条件に合致したデータを取得したい場合は、S3 Selectを使用します。
単一のファイルでなく、トランザクションデータとマスタデータを結合した結果を取得したいなどの場合は、Athenaを使用します。
S3 Selectは、単一ファイルのみが対象となるところがポイントです。なので、複数ファイルを対象となった時点でAthenaを使用します。
利便性や利用用途などは、Athenaの方が高い(広い)です。
S3 Selectは事前の設定なく利用可能ですが、Athenaは、クローラーの実行など少々手間がかかります。
これらのサービスは、それぞれ異なる強みを持っていますので、利用する場面に応じて最適なサービスを選択することが重要です。
ここからは実際に、Amazon AthenaとS3 Selectを使ってみましたので、設定方法などをご紹介します。
Amazon Athenaを使用したクエリの実行
Amazon Athenaを使用してデータをクエリする前に、AWS Glueを使用してデータカタログを作成する必要があります。
以下の手順に従って、POSデータと店舗マスタのCSVファイルをクローラで処理し、Athenaでクエリを実行できるようにします。
1.AWS Glue クローラの設定
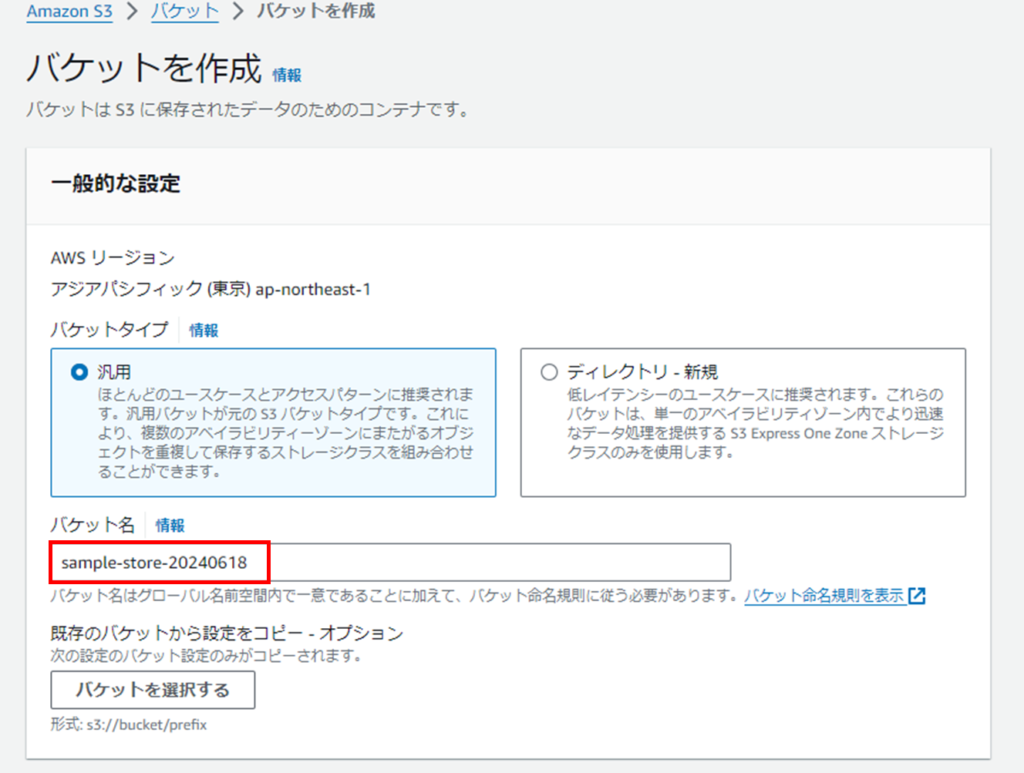
ステップ1: S3バケットの作成とデータのアップロード
S3コンソール にログインします。
「バケットを作成」をクリックしてS3バケットを作成します。任意のバケット名(例:sample-store-20240618)を指定して「バケットを作成」をクリックします。

作成したバケットを選択し、「アップロード」をクリックして以下の2つのCSVファイルをアップロードします。
- ファイルはUTF-8で保存
- 「pos」フォルダを作成し、pos_data.csvをアップロード
- 「store」フォルダを作成し、store_master.csvをアップロード
ファイル1: pos_data.csv
transaction_id,store_id,product_id,category_id,quantity,price,customer_id,transaction_date
1,1001,5678,101,2,9.99,2001,2023-10-01 10:23:45
2,1002,1234,102,1,19.99,2002,2023-10-01 11:45:30
3,1001,5678,101,3,9.99,2003,2023-10-01 12:01:15
4,1003,9123,103,2,29.99,2004,2023-10-02 09:35:28
5,1002,5678,101,1,9.99,2005,2023-10-02 14:47:52
6,1001,3456,104,1,14.99,2002,2023-10-02 18:15:12
7,1003,7890,105,4,5.99,2003,2023-10-03 11:30:47
8,1001,1234,102,2,19.99,2006,2023-10-03 13:23:09
9,1002,3456,104,1,14.99,2007,2023-10-03 16:50:33
10,1003,9123,103,3,29.99,2008,2023-10-04 10:10:10ファイル2: store_master.csv
store_id,store_name,location,phone,open_date
1001,Central Store,New York,123-456-7890,2010-05-15
1002,Downtown Store,San Francisco,098-765-4321,2012-11-20
1003,Lakeview Store,Los Angeles,555-123-4567,2015-03-30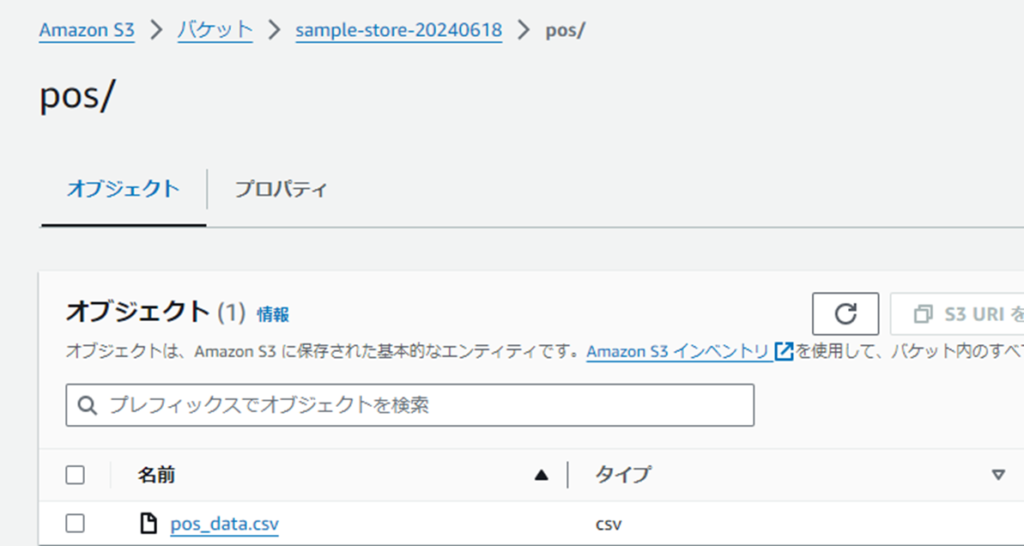
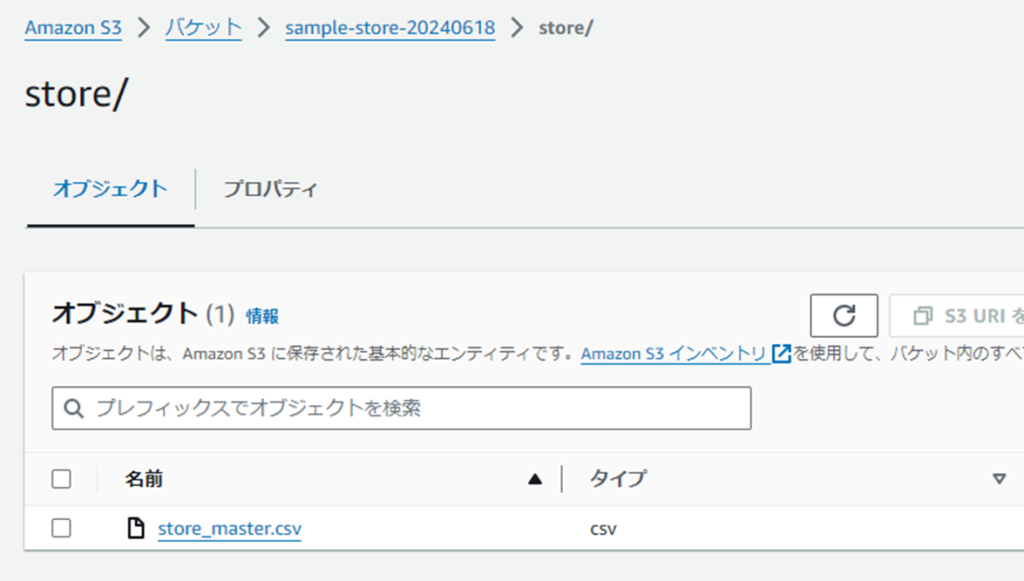
ステップ2: Glueクローラの作成
左側のナビゲーションメニューで「Crawlers」を選択し、「Create crawler」をクリックします。

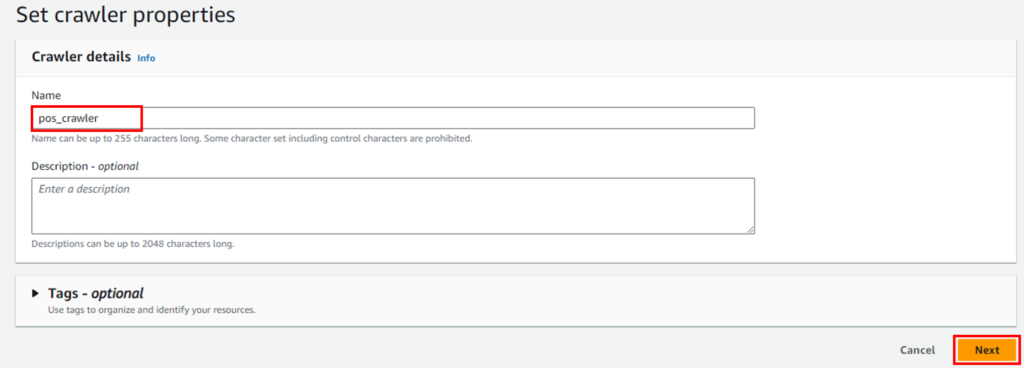
クローラ名(例: pos_crawler)を入力し、「Next」をクリックします。
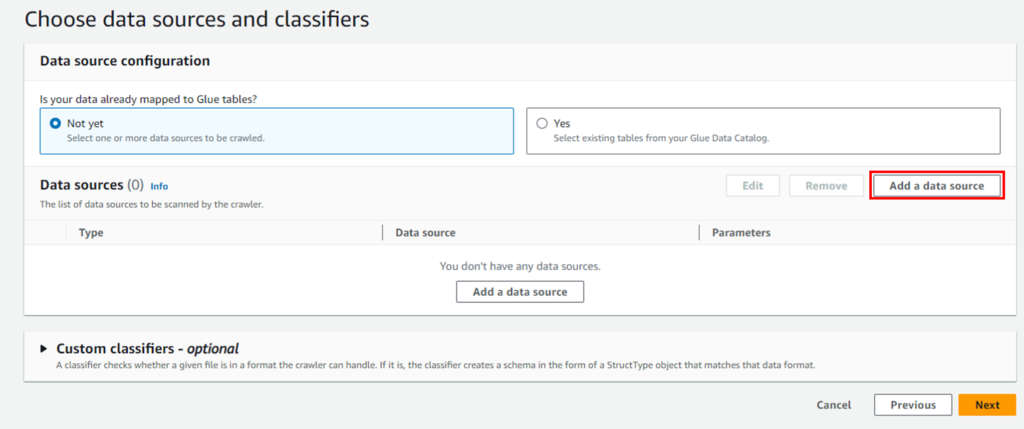
「Add a data source」をクリックします。
「Data source」にS3、「S3 path」にposデータをアップロードしたパスを設定します。「Crawl all sub-folders」を選択します。
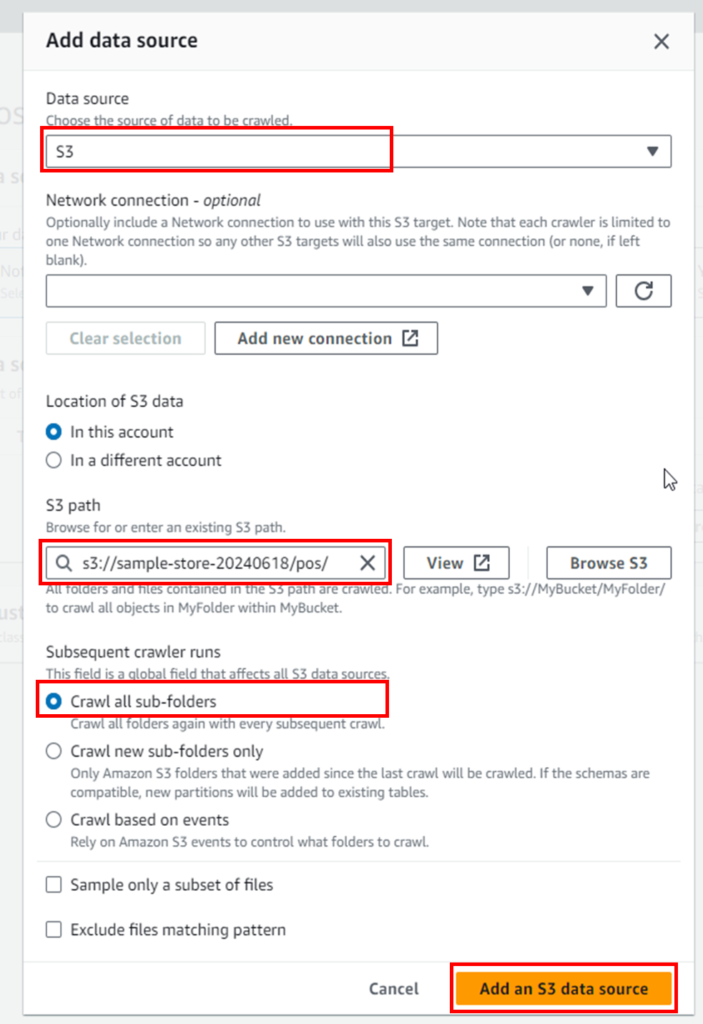
「Next」をクリックします。
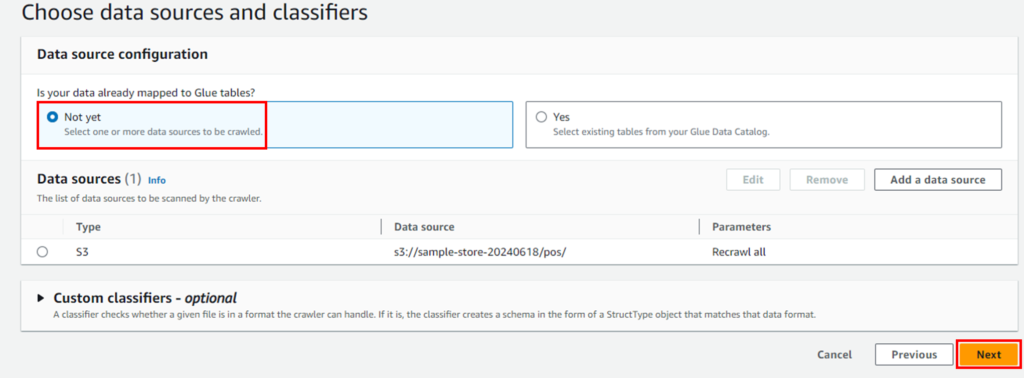
IAM roleは新規作成します。既存のロールがあればそれを使用でも問題ありません。
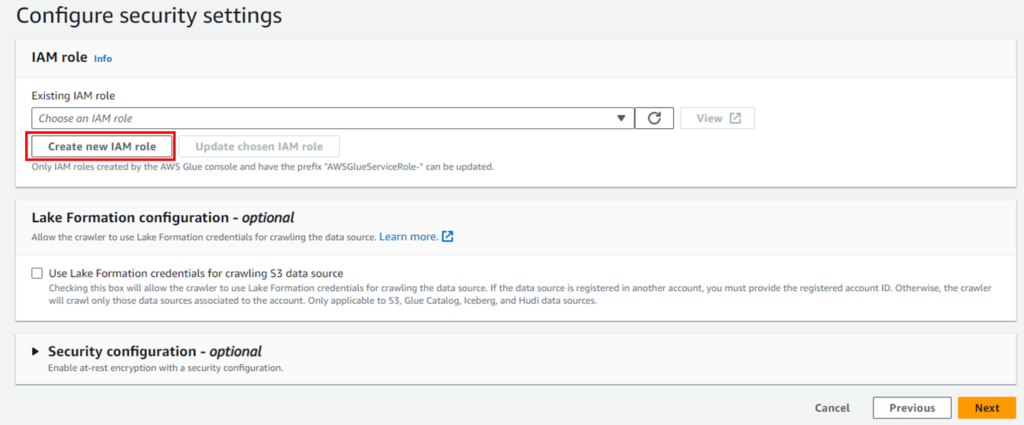
任意の名前を設定してください(例: AWSGlueServiceRole-Crawlers)。
因みに以下のような権限が付与されていました。
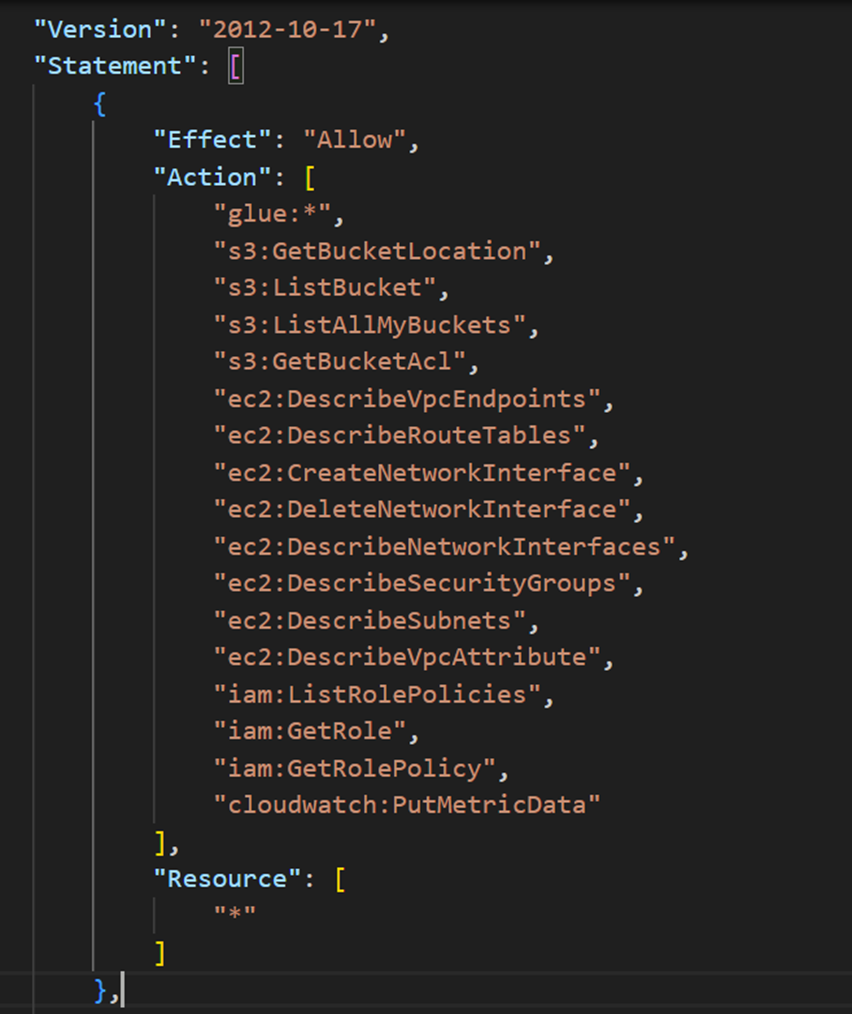
「Next」をクリックします。
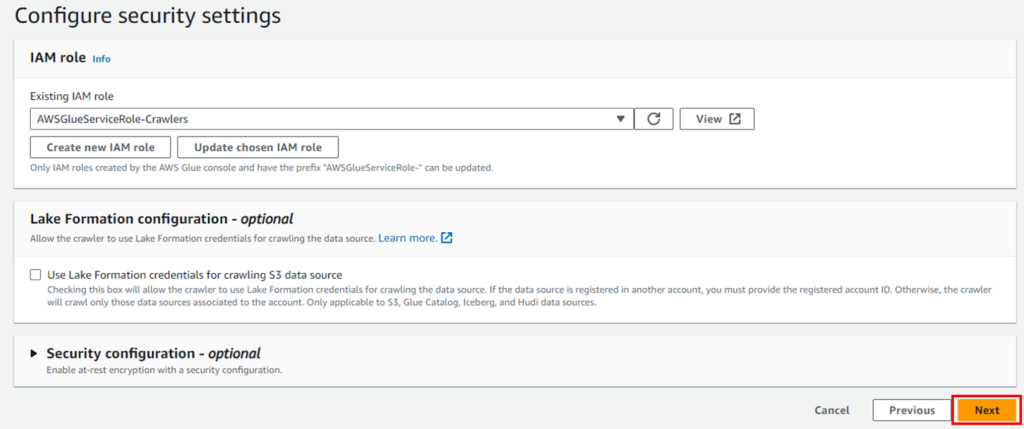
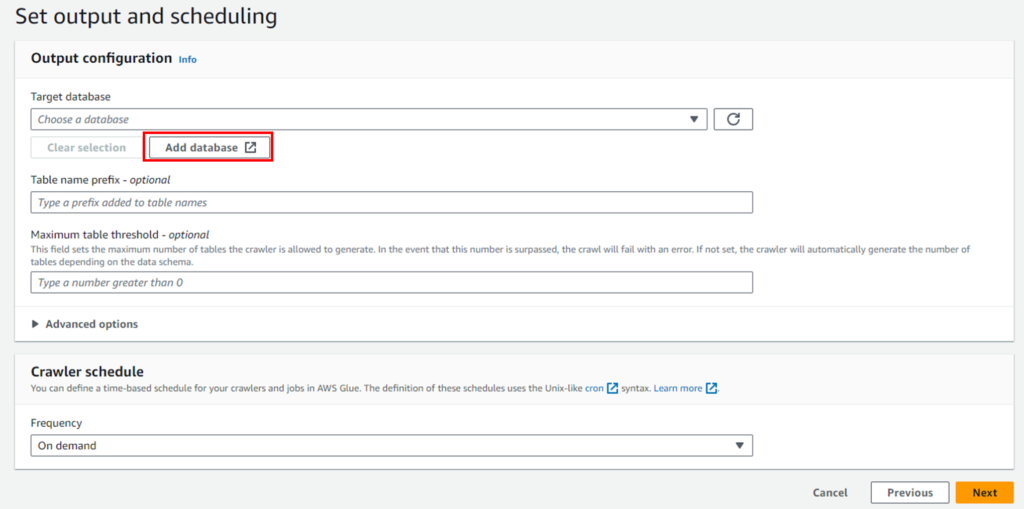
新規作成の場合は、databaseから作成します。
任意の名前のdatabase名を設定してください。
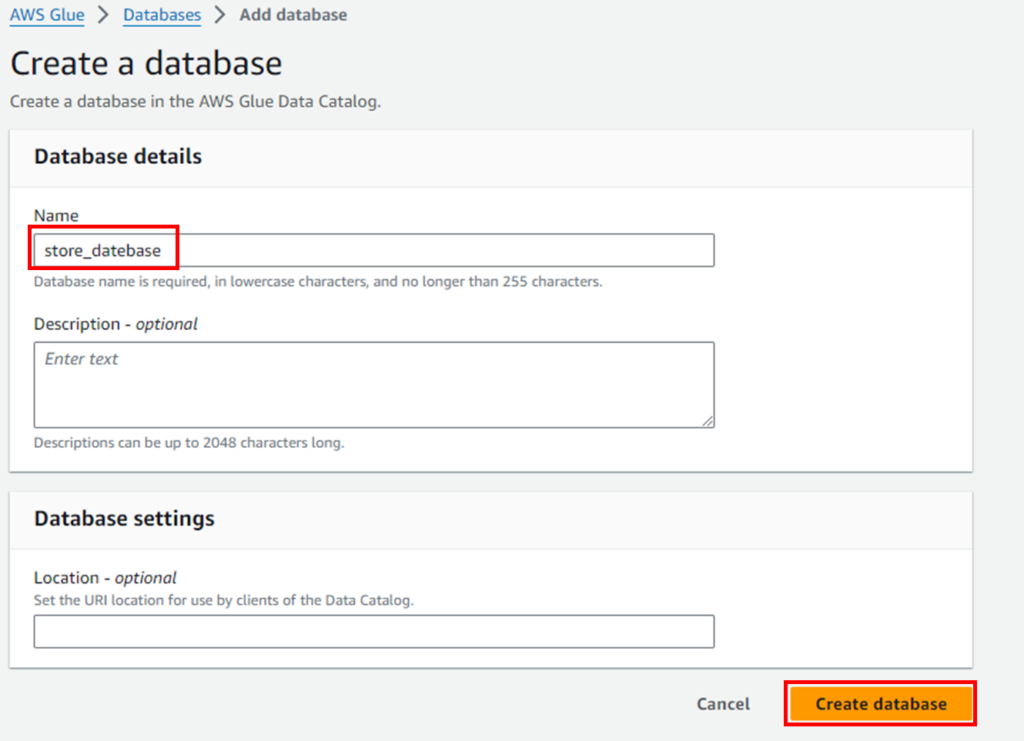
「Next」をクリックします。
「Create crawer」をクリックすると、crawerの作成が完了です。
ステップ3: Glueクローラの実行
作成したクローラを選択し、「Run crawler」をクリックします。
クローラの実行が完了すると、Glueデータカタログにテーブルが作成されます(例: pos)。
同様の手順にて、storeデータについてもcrawerを作成します。作成が完了すると、以下のようになります。
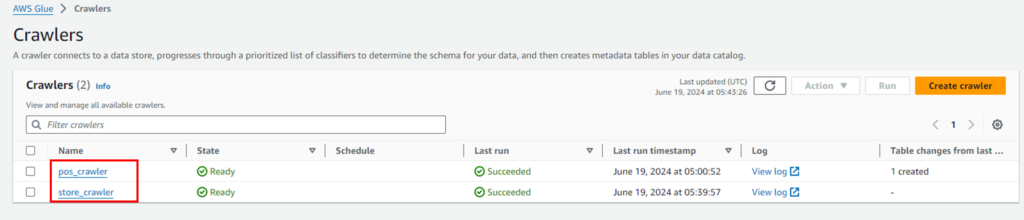
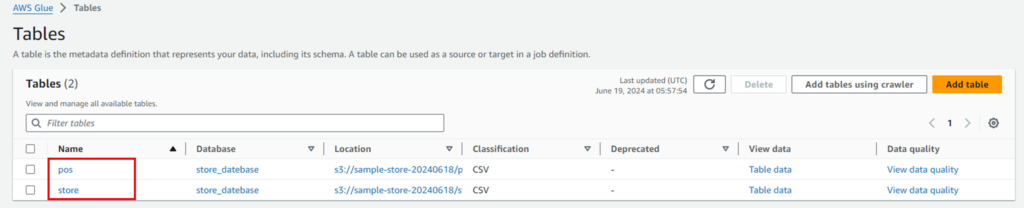
以下のようにCSVファイルから自動的にカラム名、型を読み取りテーブルを作成しています。
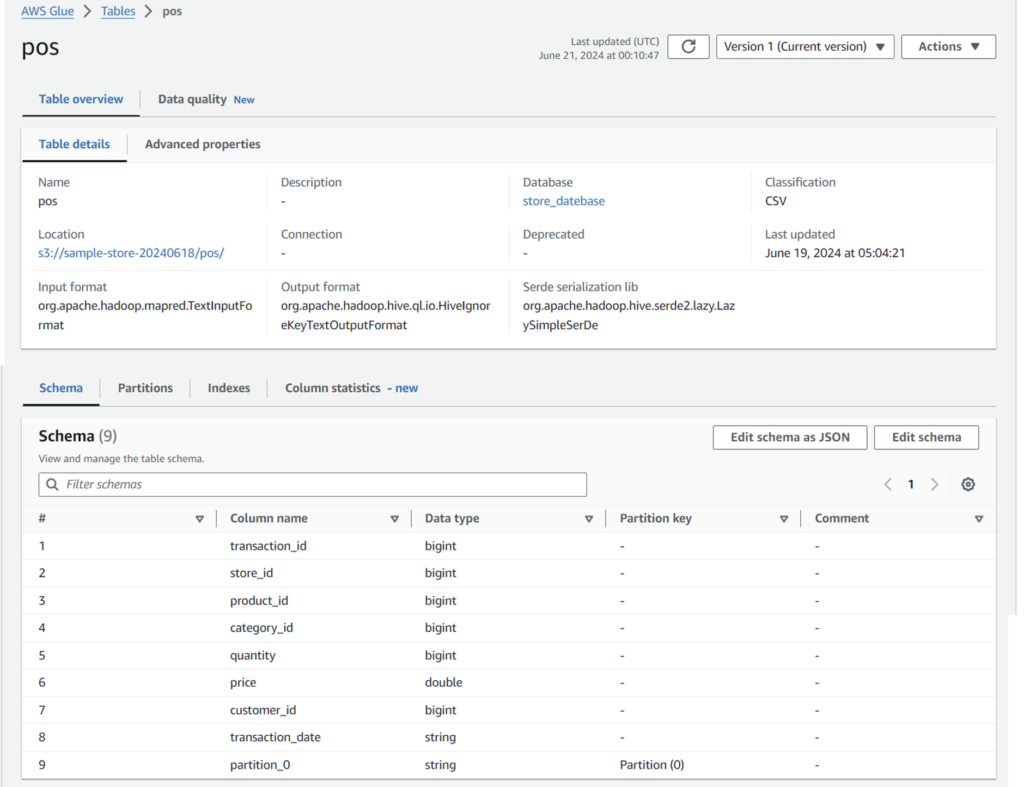
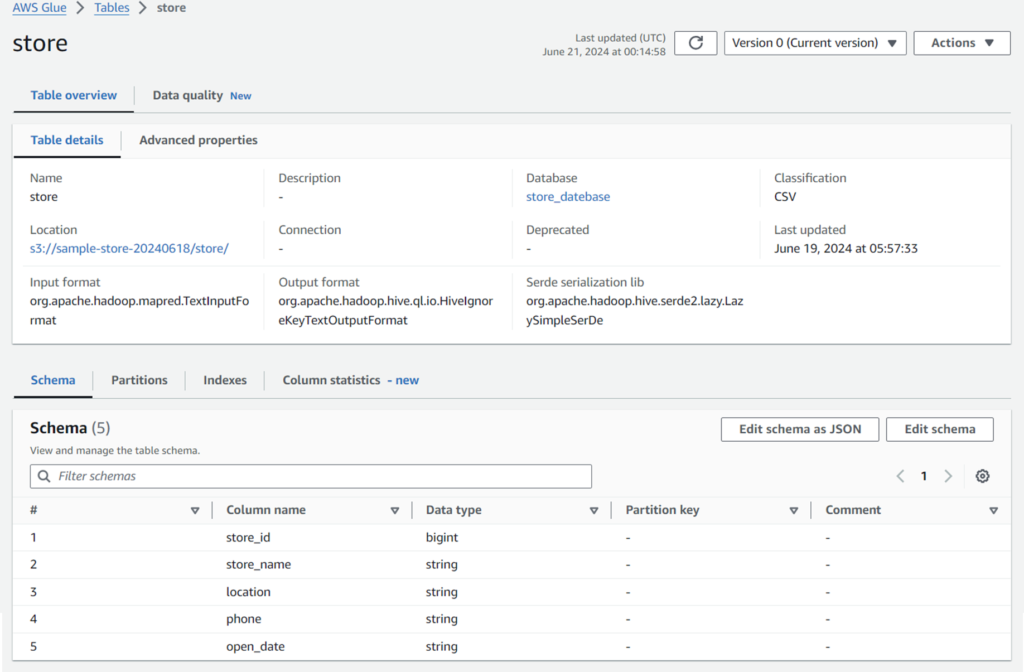
Amazon Athenaでクエリの実行
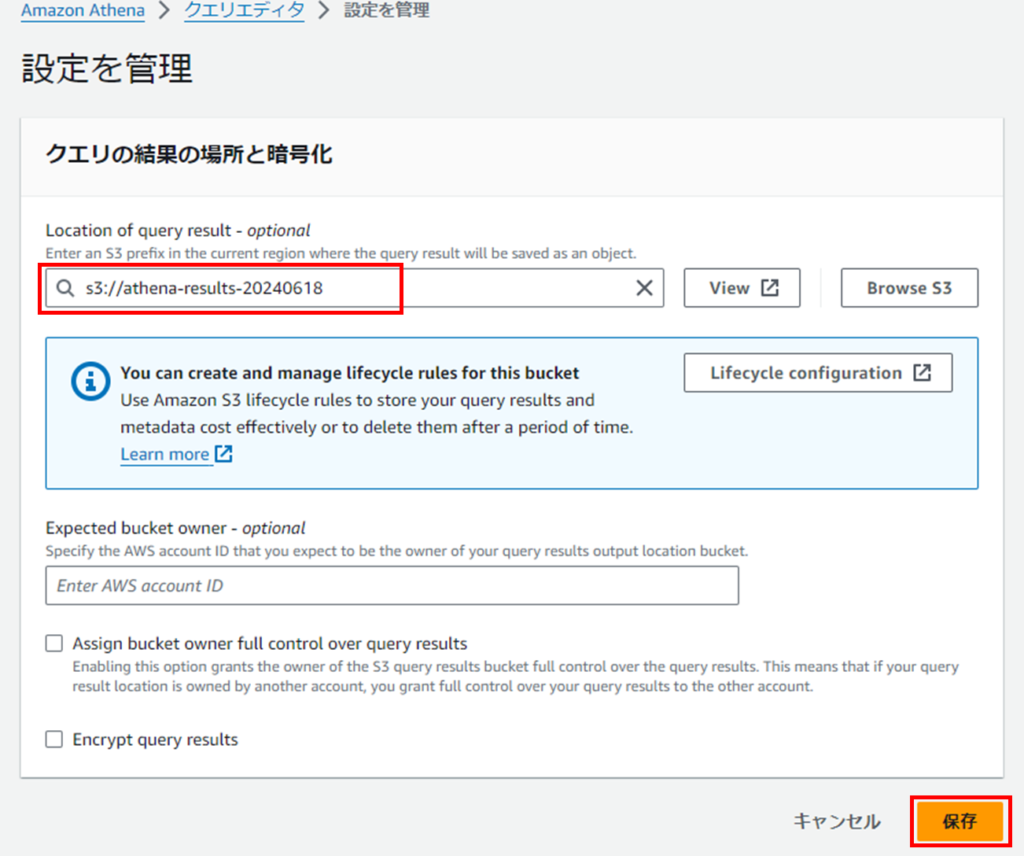
ステップ1: Athenaの設定
Athenaコンソール に移動します。
初めてAthenaを使用する場合は、クエリ結果を保存するためのS3バケットを指定する必要があります。
「保存」をクリックして設定を保存します。
ステップ2: クエリエディタでのデータクエリ
Glueクローラによって作成されたデータベースとテーブルに対してクエリを実行します。
左側のナビゲーションペインで、先ほどGlueクローラによって作成されたデータベース(例: store_database)を選択します。
クエリエディタに以下のサンプルクエリを入力します。
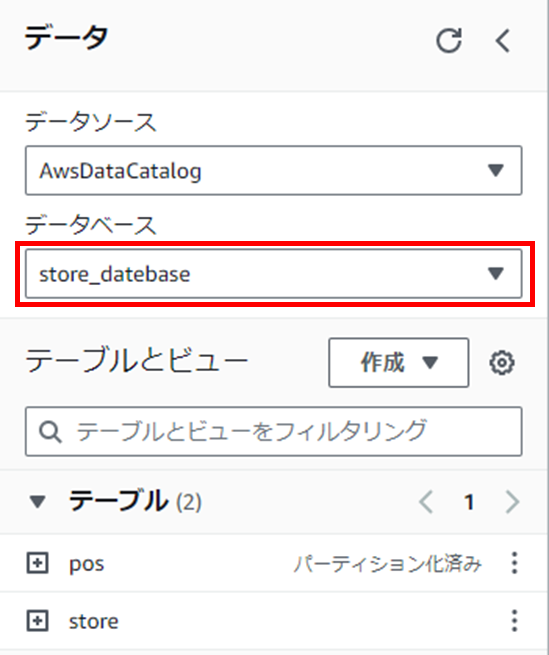
SELECT
store.store_id,
store.store_name,
store.location,
SUM(pos.quantity * pos.price) AS total_sales
FROM
pos
JOIN
store
ON
pos.store_id = store.store_id
GROUP BY
store.store_id,
store.store_name,
store.location
ORDER BY
total_sales DESC;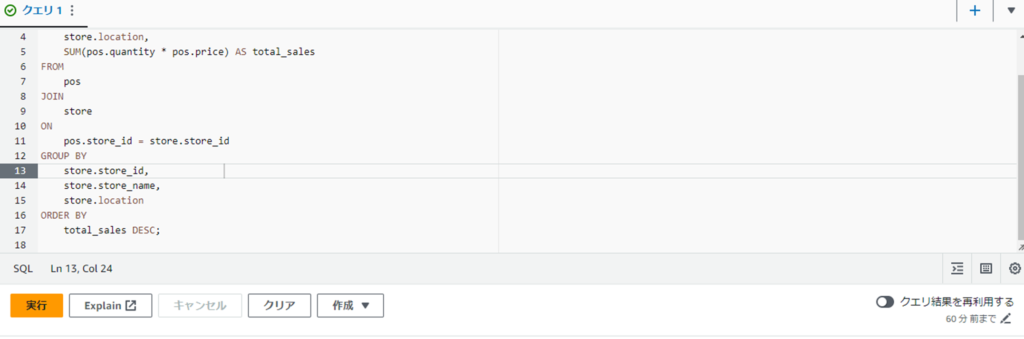
結果が出力されます。
S3 Selectを使ってみる
1.POSデータに対するクエリ
S3コンソールに移動し、pos_data.csv ファイルを含むバケットを開きます。
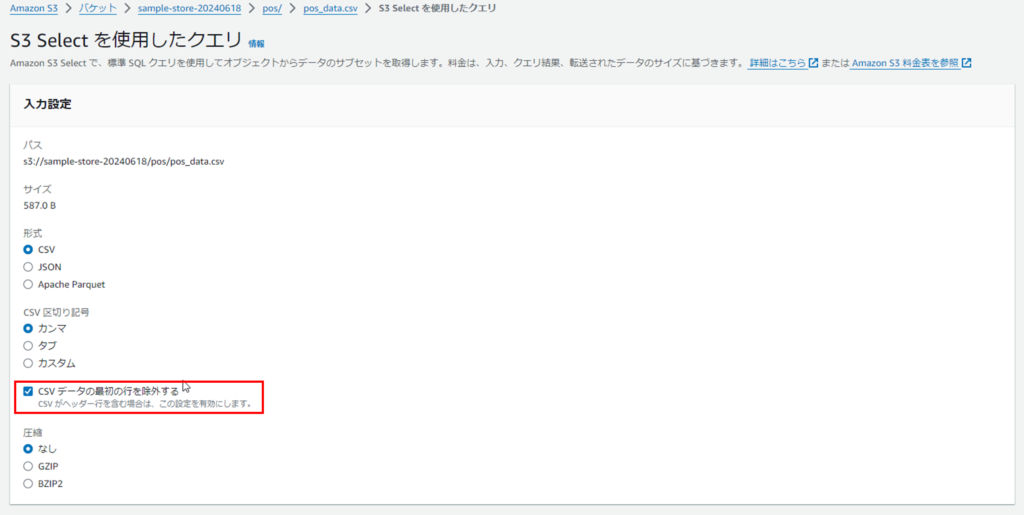
pos_data.csv ファイルを選択し、上部の[アクション]から「S3 Selectを使用したクエリ」タブをクリックします。
クエリの入力欄に以下のSQL文を入力します。
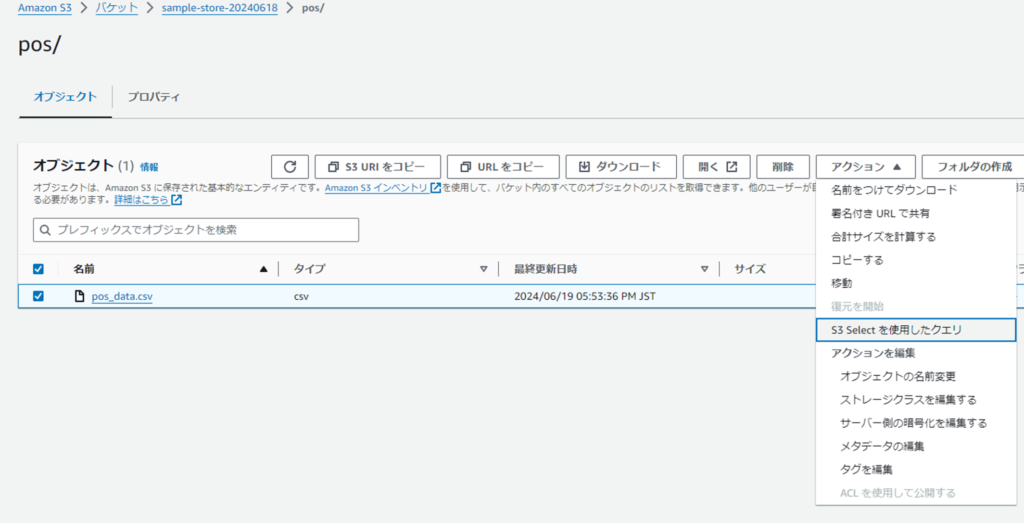
[CSV データの最初の行を除外する]にチェックを入れることでヘッダー行をカラム名と認識させることができます。
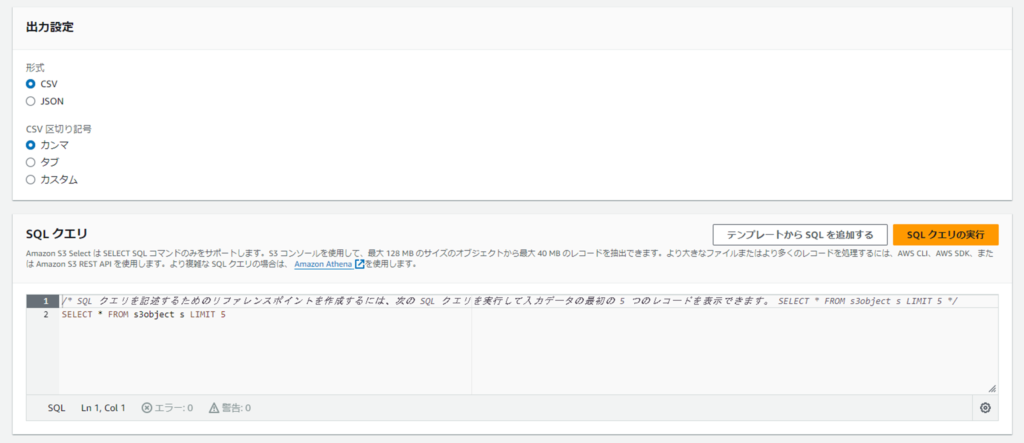
クエリの入力欄に以下のSQL文を入力します。
SELECT * FROM S3Object;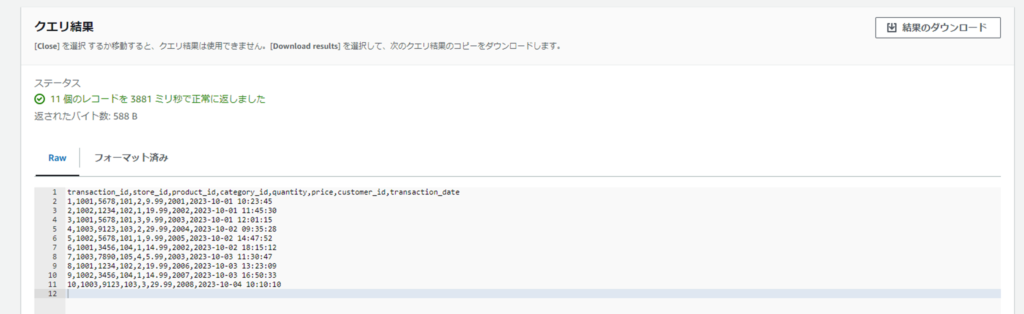
クエリ2: 特定の店舗IDにおける売上データを取得
SELECT * FROM S3Object WHERE store_id = '1001';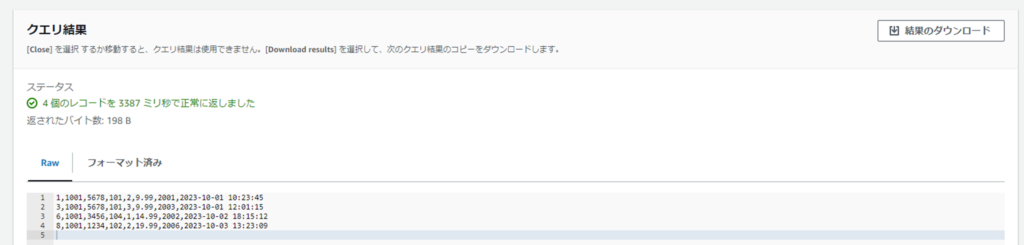
なお、以下のように通常のSQLと比べてかなり制約が多いので、ご注意ください
- 数値に対して条件 (等号、不等号)を指定する場合も、’28.5’のようにクオーテーションで囲む必要あり
- ORDER BYは使用できない
- GROUP BYのような集計はできない
最後に
いかがでしたでしょうか?
Amazon Athenaは設定は少々手間ですが、データベースのテーブルと同様に扱うことができることが分かったのではないでしょうか?
また、S3 Seletは、Amazon Athena とは違い単一のファイルのみしか対象にできませんが、その分手軽に利用することができます。
最後に特性について表にまとめてみました!