OpenShift Virtualizationを使ってみた②
投稿者:西戸 晋太郎
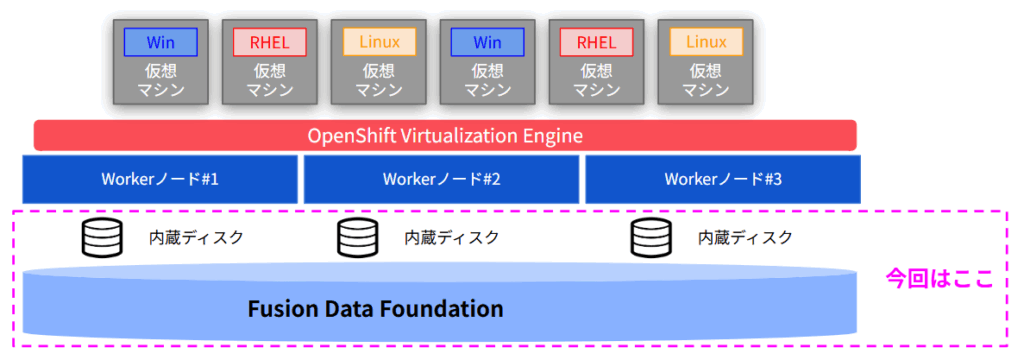
こんにちは。クラウド事業本部の西戸です。前回のブログではOpenShift Virtualizationのインストールを行いました。今回は、vSphereでいうところのデータストアに該当する仮想マシンを格納するためのストレージ領域を準備していきます。IBM FusionのFusion Data Foundationの機能を使用して、各Workerノードの内蔵ディスクを両方のノードで使用可能な共有領域として用意します。
IBM Fusionとは
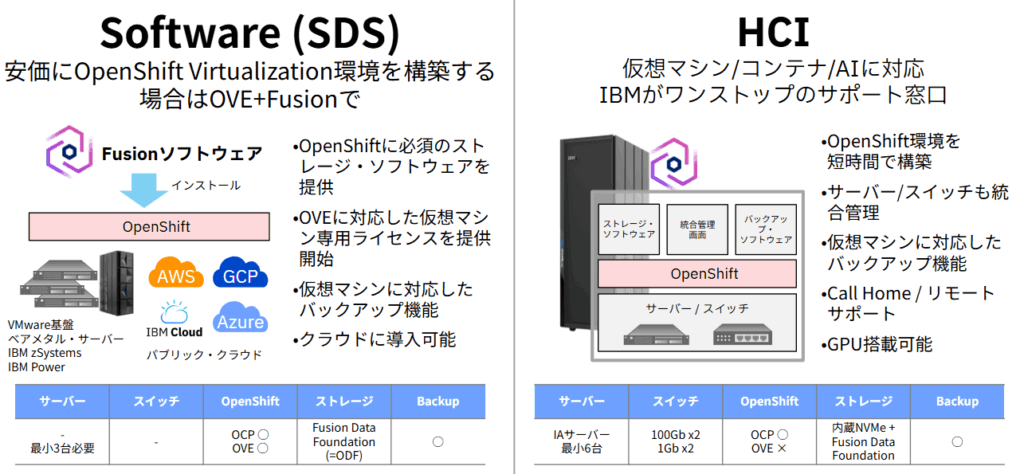
IBM FusionはSoftwareとHCIの2つの提供形態があります。前述のFusion Data Foundationなどの機能を実現するためのソフトウェア型の提供形態と、すべての機能がオールインパッケージになっているHCI型の提供形態があります。HCIはサーバやスイッチも含めてOpenShift Virtualizationがすぐに使用できる形で提供され、大規模な仮想化基盤の移行先やGPUも搭載可能なため、AI基盤として候補になります。
IBM Fusionのソフトウェア型の提供形態では、Fusion Data FoundationやBackup/Restoreなどの機能が使用することが可能です。今回の検証では、ソフトウェア型の検証を行います。
IBM Fusionの必要性
IBM FusionのFusion Data Foundation機能を使用して、各サーバが持つ内蔵ディスクで仮想マシンを格納する領域を作成していきます。vSphereでいうところのvSANデータストアを作成するというイメージです。
OpenShift Virtualizationで仮想マシンやコンテナを稼働させるためには、ReadWriteMany (RWX)のストレージが必要になります。一般的なブロックストレージではこれらは実現できず、NASなどを別途用意する必要が出てきますが、IBM Fusionはサーバ内蔵ディスクを使用して、RWXのストレージを構成することが可能となります。
IBM Fusionのインストール
それでは早速、IBM Fusionをインストールしていきましょう。Virtualization同様にOperatorを使用して導入していきますが、事前作業が必要です。
Operatorカタログの追加
Fusion OperatorのイメージはIBMのレジストリであるcp.icr.ioよりPullしてくるため、事前にOpenShift上にイメージプルシークレットを登録しておく必要があります。IBM container software libraryよりエンタイトルメントキーを取得する。
コピーしてきた値にcp:をつけて、base64エンコードを行い、エンコードした値をjsonファイルとして保存しておきます。openshift-configネームスペースのイメージプルシークレットを更新します。
# echo -n "cp:[IBMサイトから取得したKey]" | base64 -w0
# vi regisry_key
{
"auth": "base64にエンコードしたkey"
}
# oc get secret/pull-secret -n openshift-config -ojson | jq -r '.data[".dockerconfigjson"]' | base64 -d | jq '.[]."cp.icr.io" += input' - regisry_key > temp_config.json
# oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=temp_config.json
secret/pull-secret data updatedIBM Fusion Operatorインストール
Operator HubよりFusionを検索して、IBM Storage Fusionを選択します。
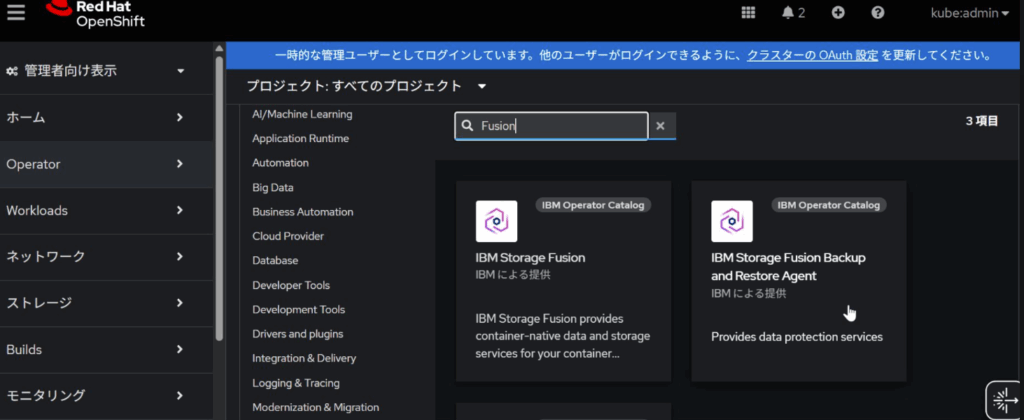
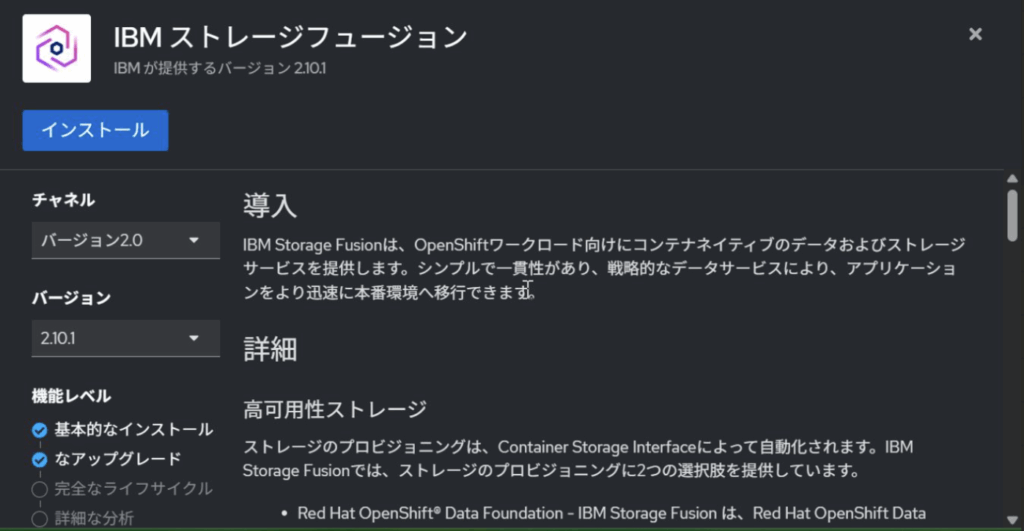
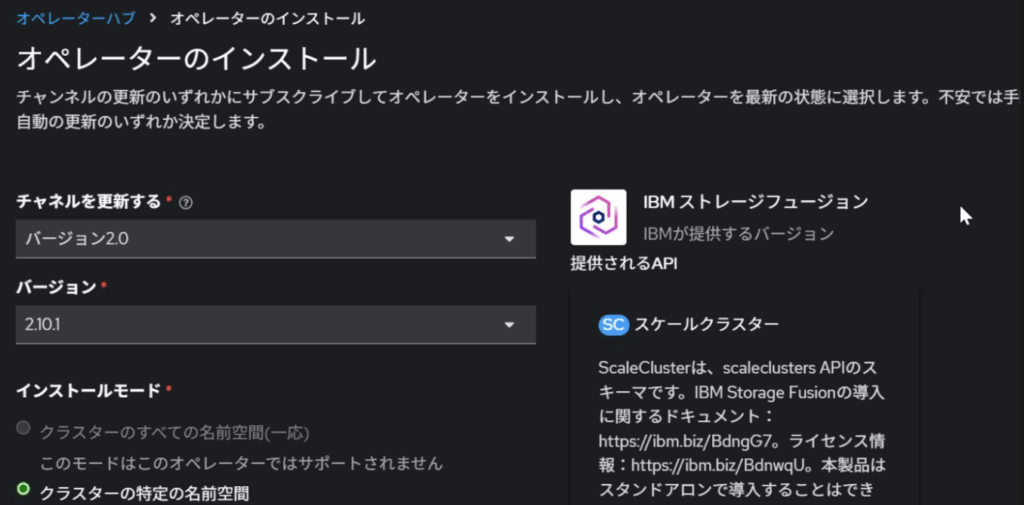
Fusion Operatorを導入するとFusion専用のコンソールに接続出来るようになります。OpenShiftコンソールの右上のアプリメニューから接続することができます。
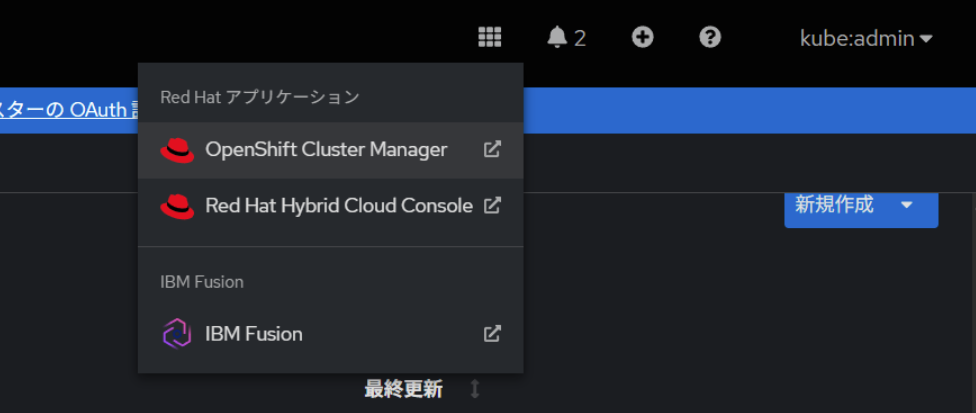
IBM Fusionの画面にアクセスすることが出来ました。こちらでFusion Data Foundationなどを構成していくことになります。