


生成AI(RAG)の利活用、うまくいってますか?RAG精度向上のポイントを4点まとめてみた。
投稿者:watsonx.data担当
生成AIを利用 / 検証している皆様、こんにちわ。NI+CのIBM watsonx.data担当の田原です。
前回の記事で触れさせていただいたRAG (Retrieval-Augmented Generation)に踏み込んだ内容として、
生成AIを利用し始めた皆様が課題として捉えているRAG精度向上をテーマに、記事をまとめました。
RAG精度向上には大きく4つのポイントがあり、今回はその内の1つ『チャンキング』についてご紹介します。
残りの3つについては今後各テーマごとに記事を書いていきますので、そちらもご覧いただけますと幸いです。
もくじ
- そもそも「RAG(Retrieval-Augmented Generation)」とは?
- RAGの精度向上を図るために必要なこと
- 精度向上ポイントについて
- 精度向上ポイント① チャンキング
- まとめ
そもそも「RAG (Retrieval-Augmented Generation)」とは?
この記事のご覧になっている方々は既にご存知かと思われますが、おさらいとして簡潔にまとめ直します。
RAGとは、一言でまとめると「LLM(生成AI)と指定したソースからの情報検索を組み合わせたアプローチ」です。
例えば、社内のファイルサーバーといった指定したデータソース内のデータをインプットに、LLMにて情報を
生成させる仕組みとなります。
具体的な処理の流れについて、以下の図を例に説明します。
コールセンター担当者は、生成AIに対してクレームの分類を行うための質問を行います。
質問を受けた生成AIは、質問に関連する情報を社内システム(データプラットフォーム)内の、通話記録が
保存されているVector DBを参照し、回答を生成します。その後、生成した回答をコールセンター担当者に返します。
これがRAGにおける回答生成の流れとなります。
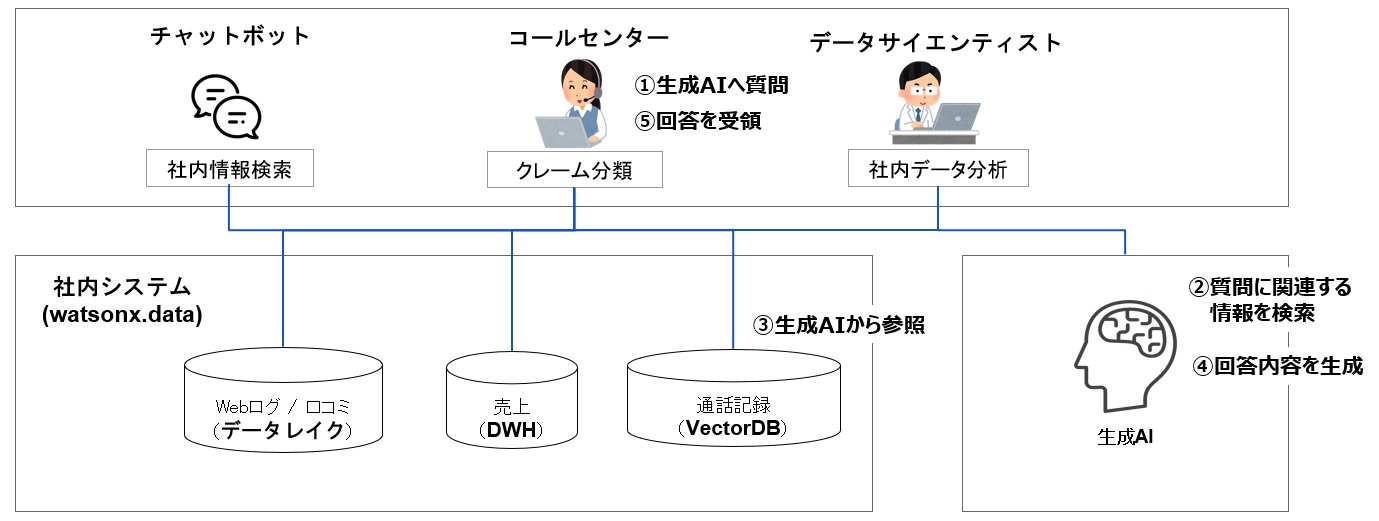
図1
一見、社内情報を利用できる非常に便利なものに見えるRAGですが、大きな欠点を抱えております。
それは、生成AI(RAG)を導入したはいいものの、精度が悪く業務効率化に繋がりにくいことが多々ある、というものです。
おそらく、技術検証でRAGを触ったことがある方々や、業務効率化で導入された一部の方々、生成AIをお客様環境へ導入するSIerの方々は身をもってご体感されているのではないでしょうか。
では、そんなRAGの精度を向上させるためには、どうすれば良いのか?次の章から徹底解剖していきます。
RAGの精度向上を図るために必要なこと
まず、基本的なところからおさらいとなります。
RAGは精度を向上させるために、大きくは以下2つの点で改善が図れます。
1.プロンプトの見直し(プロンプトエンジニアリング)
2.データの見直し
プロンプトエンジニアリングは、RAGに限らず生成AI(Chat GPT含)に触れたことがある方はご存知かと思われます。
生成AIへの質問内容を見直すことで回答精度を向上させることが出来ます。
「1.プロンプトの見直し(プロンプトエンジニアリング)」は、例えば「あなたは優秀なコールセンターの担当者です。」
と前置きをしてから質問を行うようなロールプロンプトがあります。
次に「2.データの見直し」について、コールセンター担当者がクレーム対応時に生成AIを利用することを例にご説明します。
2024年12月16日にコールセンター担当者が生成AIを利用して、クレーム対応の回答を準備します。
まずは悪い例からご覧ください。
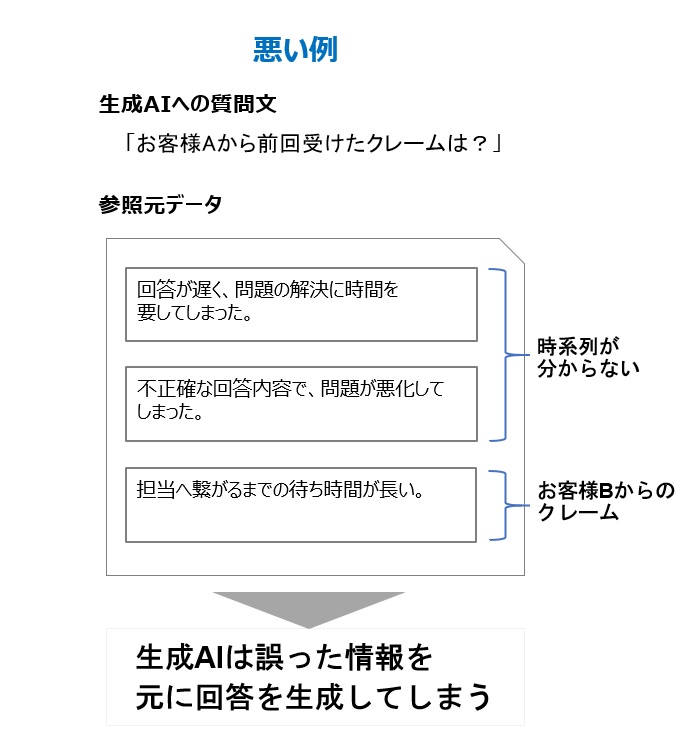
図2
質問内容は、お客様Aの過去クレーム情報を参照するものとなり、参照元のデータは3つあるものとします。
結論としては、このケースでは生成AIは正しい回答を生成することは難しいです。
仮に、参照元データの1つ目「回答が遅く、問題の解決に時間を要してしまった。」が求めている回答
(前回受けたクレーム)だった場合、上記のケースでは以下のような誤った回答を生成してしまう可能性があります。
誤った回答例1.「不正確な回答内容で、問題が悪化してしまった。」
→お客様Aのクレームという点では正しいのですが、この回答内容は前回受けたクレームではなく、
前々回のクレームであった。というケースとなります。
誤った回答例2.「担当へ繋がるまでの待ち時間が長い。」
→お客様Aのクレームではなく、お客様Bのクレームを参照した回答となってしまったケースとなります。
では、データの持ち方をどのように変えれば生成AIが正しい回答を返すことができるのか?
具体的な方法を以下にまとめます。
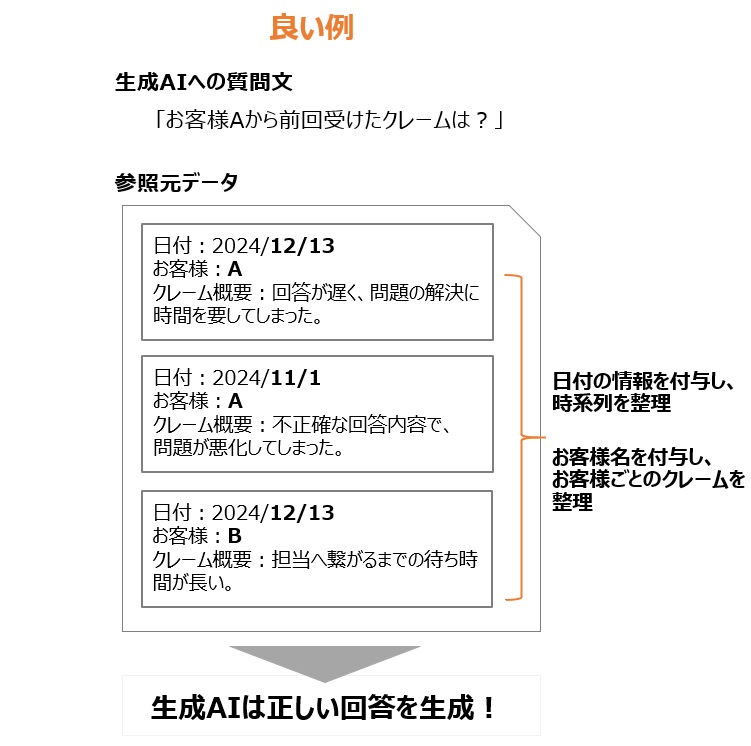
図3
参照元データの改善点を以下の記載します。
1.クレームを受領した時系列が把握できるように日付の情報を付与
2.お客様ごとのクレームを整理できるようにお客様名を付与
元のデータにメタデータとして「日付」「お客様名」を付与し、データの内容を整理することで、
生成AIは正しく情報を参照できるようになり、質問に対して正しい回答を生成できるようになります。
今回のコールセンターの例でいうと、質問を行った2024年12月16日の「前の日付」で、かつ「お客様Aの情報」を参照して
生成AIは回答ができるようになります。
上記の例は極端ではありますが、生成AIも人間と同様に与えられた情報量に不足があると、不正確な回答を生成してしまいます。
そのため、RAGへ格納するデータが回答を生成するために必要な情報を含んでいるのか?という点は常に意識する必要があります。
精度向上ポイントについて
精度向上ポイント4つの概要についてご説明します。
ポイント① チャンキング
→インプットデータを分割し、生成AIにとって読みやすい形に加工
ポイント② ハイブリッド検索
→キーワード検索に加え、ベクトル検索を行い質問内容と類似度の高い文章をハイブリッドに検索
ポイント③ リランキング
→検索結果を再評価することで、関連性の高い検索結果を選択
ポイント④ メタデータフィルタリング
→メタデータを用いてフィルタリングを行うことで、関連性の低いデータを排除
イベントへの出展時などに、お客様から「これらのポイントの中で、どれが一番改善効率がよいのか。」という質問を
よく頂いておりました。
この質問に対して、私は「お客様のRAG活用シーンや利用予定のデータによって異なるため、一概にどのポイントが
改善に大きく作用するか回答するのは難しいです。」とお答えしておりました。
RAGは扱うデータの内容や、データの量、活用シーンによって重視するべき点は変わります。
そのため精度向上の最適解を見出すことは難しいですが、このブログが最適解を見つけるための足掛かりになればと思います。
精度向上ポイント① チャンキング
さて、RAGの概要と、RAGにおける基本的な精度向上の考え方についておさらいをさせて頂き、
精度向上ポイントの概要をご説明させていただきましたので、次は本命の精度向上ポイントの応用編となります。
前談ですが、精度向上のポイントは既に数十以上が存在しており日々国内外で研究が進み、増え続けております。
しかし、それらすべてを説明することは難しく、取り入れることも難しいと思われます。
そのため、私は環境依存度が低く、汎用的に精度向上を図れるポイントを4つに絞り、
ご紹介させていただこうと考えており、今回は精度向上ポイントご紹介の第一弾となります。
前置きが長くなってしまいましたが、RAGの精度向上ポイント「チャンキング」についてご説明いたします。
既に述べさせていただいておりますがチャンキング(Chunking)とは、一言でいうと
「文章を分割し、生成AIにとって読みやすい形に加工」することです。
以下例文を元に、3つのチャンキング方法をご説明します。

図4
1.チャンクなし
早速、「文章を分割する手法について説明する」と言っているところで矛盾してしまうのですが、
チャンキングせずにデータを格納する手法です。
どのような場合で有効かというと、既にデータが規則的に分割/整理されている場合です。
チャンク処理を行わずに済むということは、生成AIの処理速度が早くなる、
つまりパフォーマンスの向上につながります。
そのため、不要であればチャンキングを行わないことも1つの選択となります。
2.固定サイズ
決められた文字数で改行を行う手法となります。図では1行あたりの文字数を10文字としています。
固定サイズでのチャンキングは、決められた文字数ごとにチャンキングを行うため、
「3. Semantic Chunking」と比べてチャンキングの処理速度が向上します。
そのため、ベクトル化したいデータの量が多い場合などチャンキング処理を早めたい場合に有効です。
しかし、図4に記載している例のように文章の意味が崩れやすいため回答精度は落ちてしまいます。
3.Semantic Chunking(セマンティックチャンキング)
文章を意味的な単位で分割し、各文章の類似度を比較した上で、各文章を1つのグループとして捉え
チャンキングする手法となります。
セマンティックチャンキングは、固定サイズでのチャンキングよりも文章の一貫性を保ちます。
ユーザーはチャンクサイズ等を考えることなく、内容の一貫性を保ちながら文章の意味を保持した形で
文章の分割が可能になります。
そのため、ユーザーはチャンキングについての検討時間をかけずに、生成AIの回答精度を向上させることが
できます。
そのため、データをベクトル化する時に文章の特徴量を掴みやすく、生成AIの回答精度だけではなく
ベクトル化の精度も向上させることが出来ます。
しかし、文章の特徴量によってチャンキングを行うため、固定サイズ分割と比べてチャンク処理に
時間が掛かってしまいます。
まとめ
いかがでしたでしょうか。以上がRAGの精度向上におけるポイントの1つ「チャンキング」でした。
チャンキングは精度向上においても非常に重要な点となります。
私がチャンキングについて調査/検証を行う中で気付いた点としましては、
「そもそも人間が読んで分からない・分かりづらい内容は、生成AIにとっても同じこと」ということでした。
RAGで精度が出ない。とお困りのみなさまは、改めて生成AIにどのようなデータを渡しているのか
ご確認してみてください。非常に読みづらいデータが生成AIに渡っている可能性があります。
もしくは、何らかの原因で生成AIに渡るデータが読みづらい形になってしまっています。
簡単なことではないですが、データの持ち方、生成AIへのデータの渡し方を改めて見直すことで
生成AIの回答精度は格段に向上することが見込めます。
最後に、海外での研究結果についてもまとめましたので、ご参照ください。
・不適切なチャンキングを行ったRAGシステムでは、生成AIが最大60%の関連情報を見逃す可能性があります
(スタンフォードNLPラボ、2023年)
・最適なチャンキングを行うことで、誤った情報の生成を42%削減できます(OpenAIリサーチ、2023年)
・テキストをチャンキングすることで、生成AIによる回答精度が30〜40%向上することが示されています。
例えば、法的文書を処理する際、任意の長さでなく論理的なセクションごとにチャンキングすることで、
応答精度が65%から89%に改善されました。(Google / Microsoft)
GoogleやMicrosoftのような企業の研究によると、テキストをチャンクに分割すると、AIモデルの精度が30〜40%向上することが示されています。例えば、法的文書を処理する際、任意の長さでなく論理的なセクションごとにチャンク化することで、制御された研究において応答精度が65%から89%に改善されました。
参照:Everything You Need to Know About Chunking for RAG