


IBM Manta Data Lineageの使い方 基本編
投稿者:稲見
こんにちは!NI+C Data Governanceチームの稲見です。
今回はIBM Manta Data Lineageの使い方の紹介をしていきたいと思います。まずは基本編としてIBM Manta Data Lineage(以下Manta)における以下の操作とリネージュの見え方を説明していきます。
- リネージュの作成
- リネージュ画面の操作
- 過去断面のリネージュとの比較
リネージュの作成
まず簡単にリネージュを作成していきます。
こちらの画面はMantaの「Manta Flow Viewer」というリネージュを作成/閲覧する機能の初期画面です。
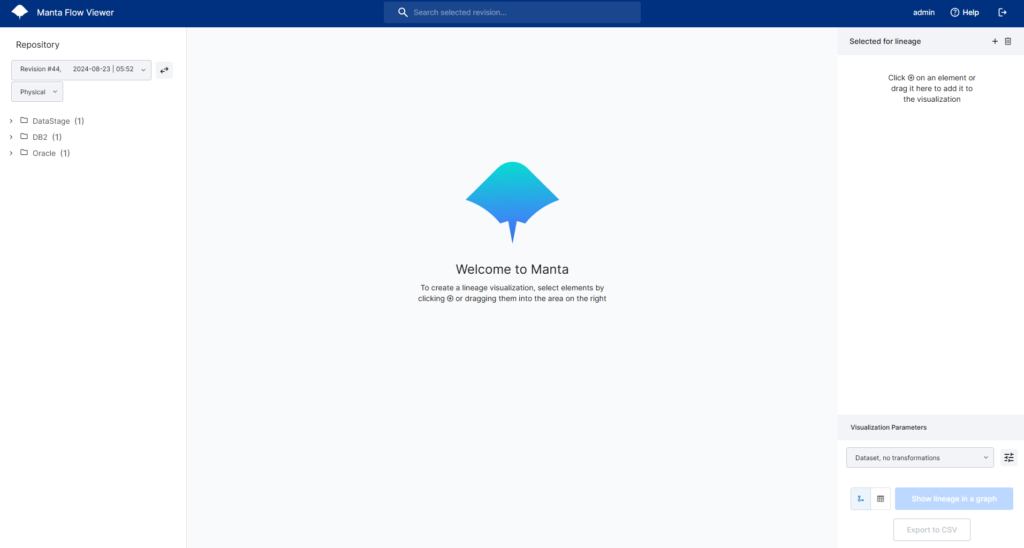
この画面でリネージュ化するバージョン(Mantaにてスキャナーを実行した時点の断面)とシステムを選択してリネージュを作成します。
今回は最新断面でDB2、Oracleの2つのデータベースとETLツールとしてDataStageのリネージュを作成します。
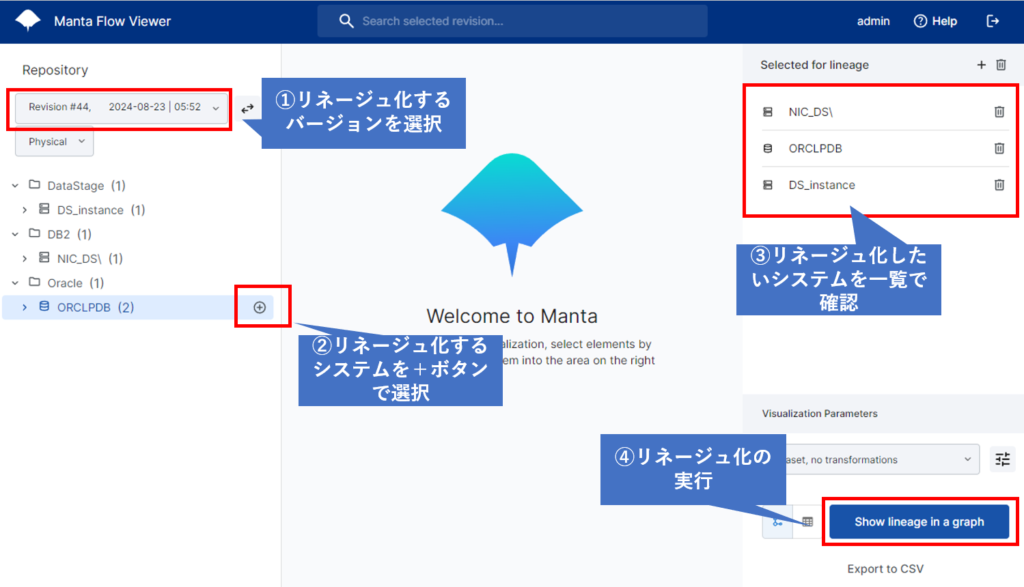
リネージュが表示されました。
デフォルトの状態ではデータベースのどのテーブルがどのETLジョブ(ETL内の処理ノードレベル)で使用され、どのデータベースに格納しているかのデータの流れを視覚的に確認することができます。
今回のリネージュでは表示されていませんが、BIツールなども含めてリネージュ化することでソースシステムのテーブルからデータマート、BIツールのレポートまで含めてリネージュで表現が可能でどのデータがどこで使用されているかを一気通貫で確認することが可能になります。
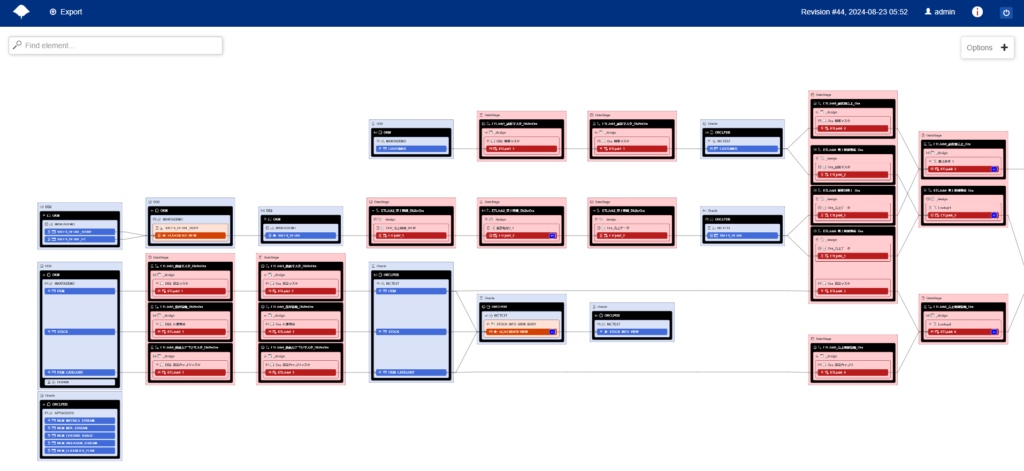
リネージュ画面の操作
リネージュ画面 では見たい粒度に各オブジェクトを展開してより詳細な情報を確認することが可能です。
まずは手動で詳細を確認したいオブジェクトを展開してどのテーブルのどのカラムが使用されているかを確認します。この例では2テーブルを縦結合(Union)したViewと元テーブルを展開した例です。
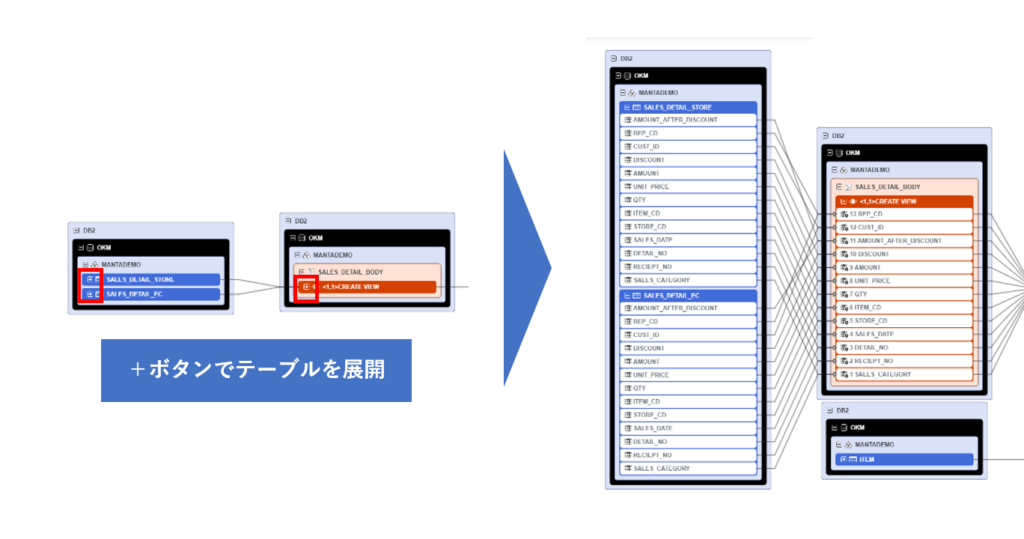
リネージュ全体を一括で表示粒度を変更することができます。
まずはOptionsのDetailからAll resourcesをHに変更してみます。(デフォルトはM)
各Detailの表示粒度は以下のようになっています。
R(最低詳細): システム/ツールなどのみ表示します。
L(低詳細1): データベース、フォルダー、ディレクトリなどのみを表示します。
L(低詳細2): データベーススキーマやETLジョブなども表示します。
M(中程度の詳細): テーブル、プロシージャ、変換、スクリプトなども表示されます。
H(高詳細) : 列、ポート、属性を含むすべての要素を表示します。
X(カスタム詳細) : ユーザーが自分で定義した粒度で表示さいます。
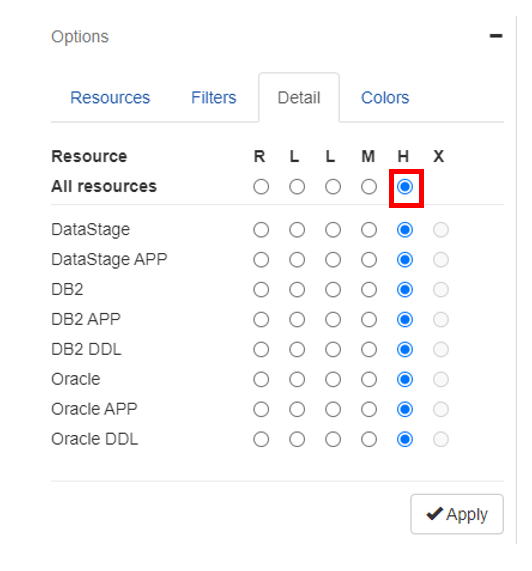
All resourcesをHにすることでリネージュ上のすべてのオブジェクトがカラムレベルから表示されより詳細なリネージュを表示することができます。
またLに設定するとデータベースのスキーマレベル、ETLのジョブ単位で簡易的にデータの流れを確認可能なリネージュを表示することが可能です。
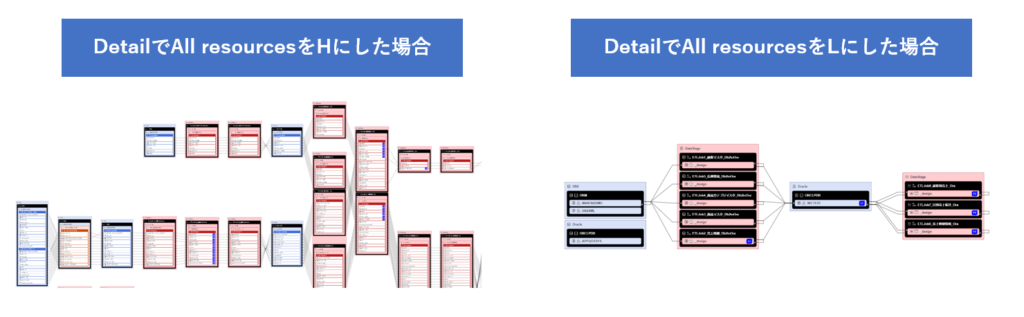
リネージュ全体のDetailだけでなく、各システム単位でもDetailを変更することが可能なため、見たい粒度を柔軟に変更しながらデータの流れを確認できます。
過去断面のリネージュとの比較
Mantaではバージョン同士のリネージュを比較することもできます。バージョン間でデータの流れに違いがあるか、どこに違いがあるを視覚的に確認することができます。
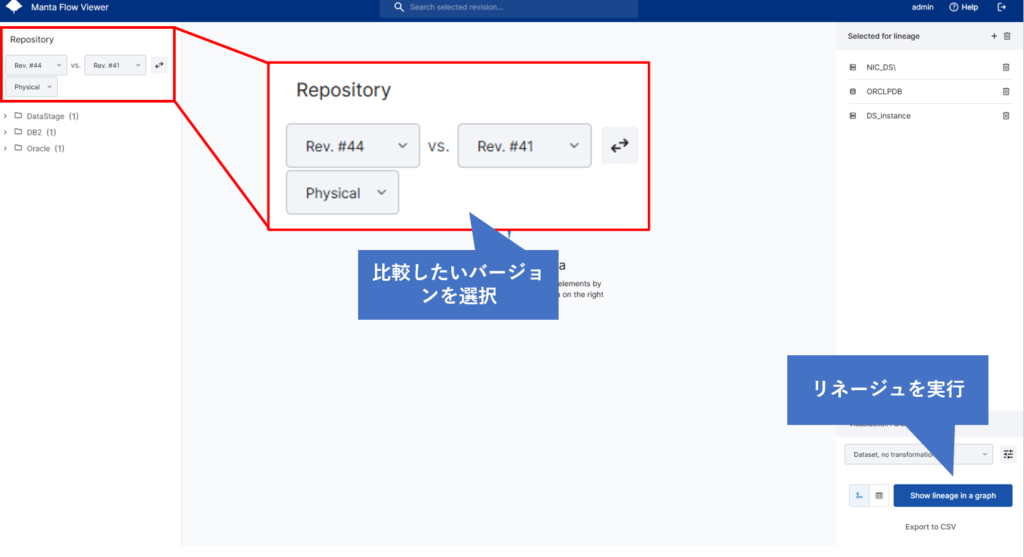
「Manta Flow Viewer」の初期画面で比較したいバージョンを選択し、リネージュを作成します。今回はRev.#44(最新のバージョン)とRev.#41(過去のバージョン)を比較してみます。
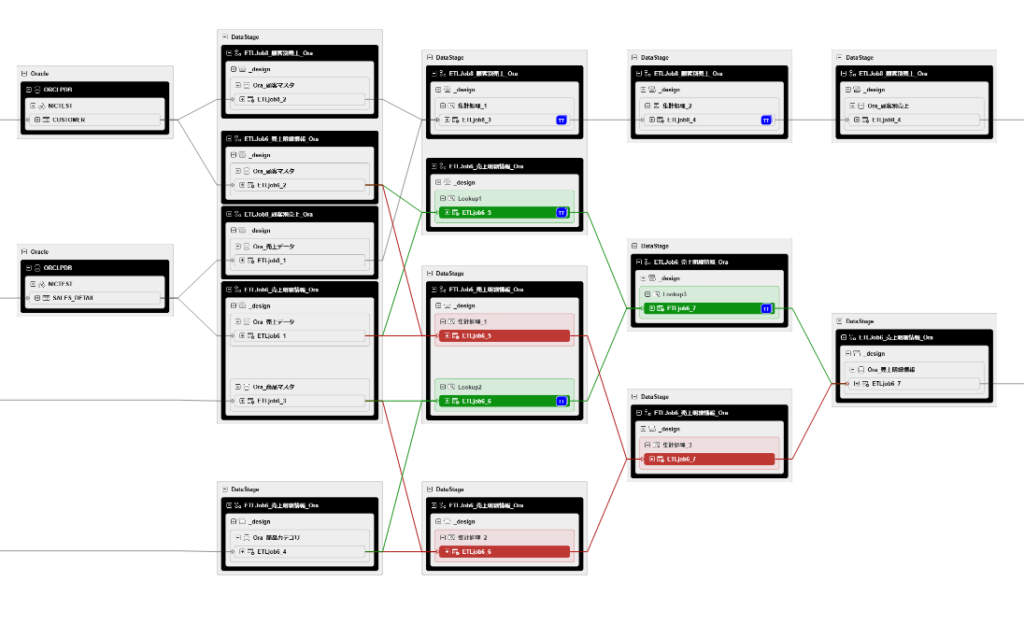
リネージュが表示されました。リネージュ上で変更がある場所は色がついているため変更点を容易に確認することができます。今回の場合は赤色と緑色で違いが表現されており、赤の線/オブジェクトは比較元のバージョン(Rev.#44)、緑色の線/オブジェクトは比較先(Rev.#41)バージョン時のデータの流れとなり、一目でどこに変更があったのか確認できます。
おわりに
今回はIBM Manta Data Lineageの基本編ということでリネージュを作成し、リネージュ画面での簡単な操作の流れをご説明させていただきました。
次回からはIBM Manta Data Lineageがどのように使えるかをユースケースを交えてご説明したいと思います。お楽しみにお待ちください。