


IBM Manta Data Lineageの使い方 応用編
投稿者:稲見
こんにちは。NI+C Data Governanceチームの稲見です。
今回は「IBM Manta Data Lineageの使い方 基本編」の続編 第2弾(※)として以下のIBM Manta Data Lineage
(以下Manta)の機能を活用した応用事例についてご説明します。
(※ 第1弾はこちら「IBM Manta Data Lineageの使い方 ユースケース編」
- 機能紹介:OpenManta
- ユースケース紹介:Manta対応製品 / 未対応製品間におけるジョブのリネージュ化
機能紹介:OpenManta
Mantaは多彩なスキャナーが用意されており、様々な製品と連携しデータの流れをリネージュ化することが可能ですが、スキャナーが用意されていない製品もあります。スキャナーが用意されていないシステムが社内にあった場合にMantaではどうするのか。
そんなときに使う機能が「OpenManta」です。スキャナーが用意されていない製品についても、OpenMantaを使用することでデータリネージュの補完ができ、社内全体のデータリネージュを実現するに欠かせない機能となります。
この機能は、手動でデータリネージュを作成することができる機能でMantaに対応していないデータベースやETL製品、ファイル集配信システムを使ったデータ連携などのリネージュ化する際に使用します。
OpenMantaの使い方
今回はファイル集配信システムを使用したCSVファイルをAサーバからBサーバに転送し、Snowflakeにインポートするという流れをOpenMantaで作成してみます。
OpenMantaを使用するには「Open Manta Designer」を使用します。最初はキャンパスが空白表示されており、ここでリネージュを作成してきます。
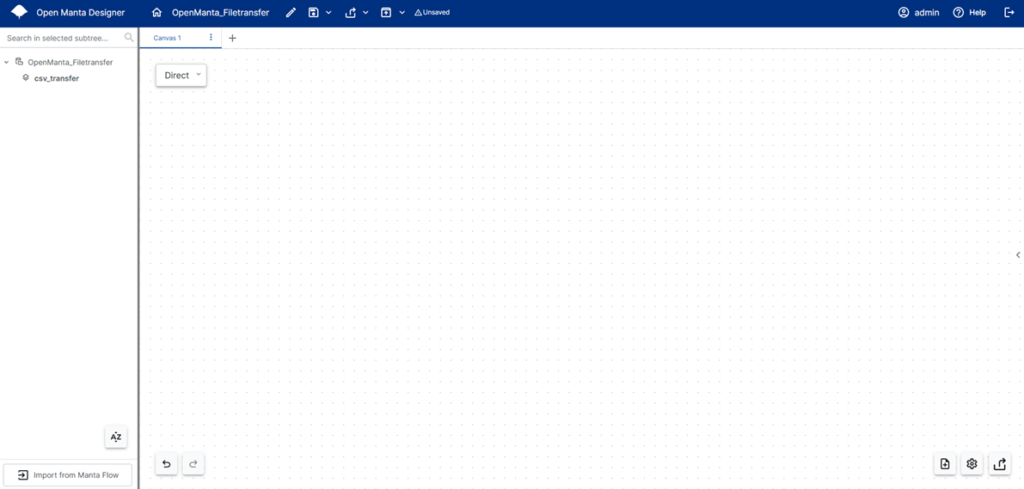
まず、リソースを設定します。+ボタンをクリックし、作成するリソースを設定します。今回はファイル集配信システムのリソースを作成するので、リソースタイプを「Filesystem」、リソース名を「ファイル集配信」とします。
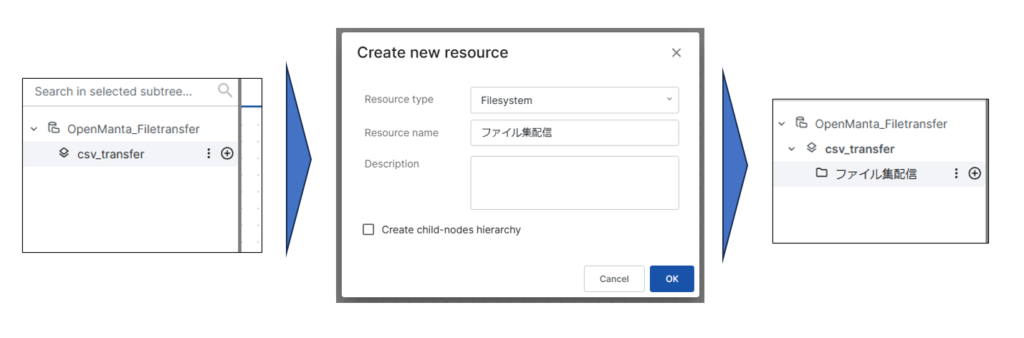
次にサーバを作成します。ファイル集配信リソースの+ボタンを押して、A_Server、B_Serverを作成します。
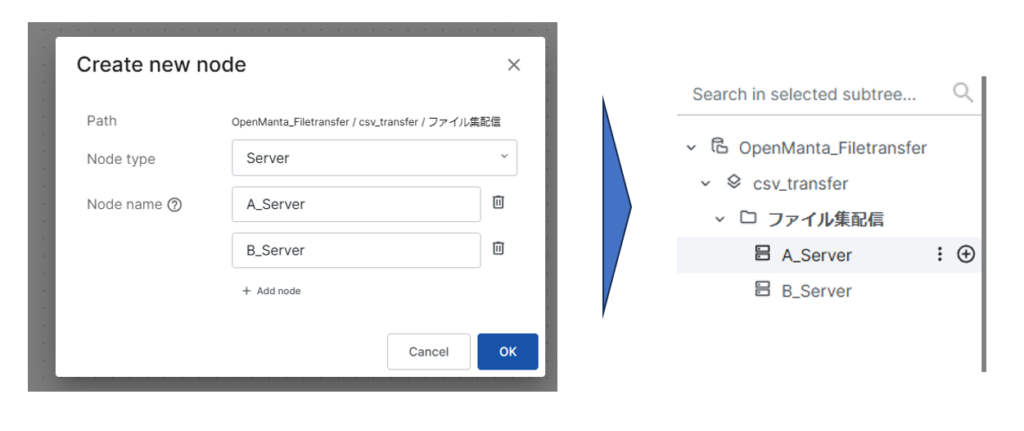
各サーバにcsvが配置されるディレクトリを設定します。ここではA_Server、B_Serverともに「/data/csv」にcsvを配置すると仮定して作成します。
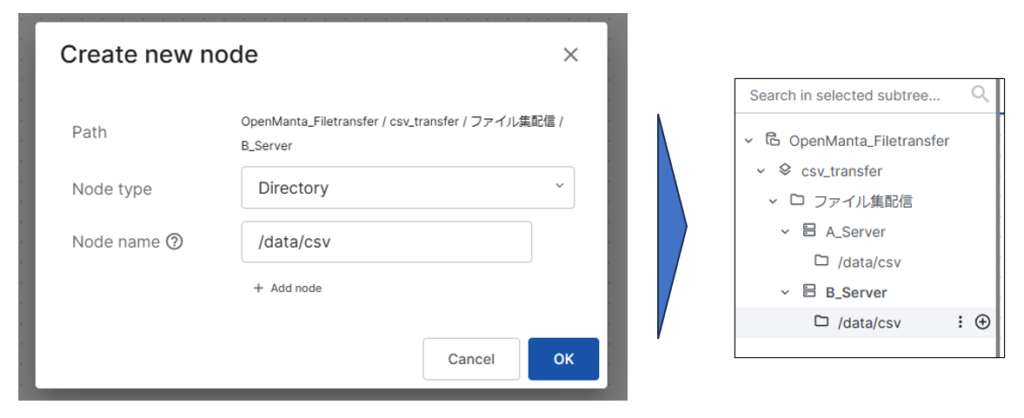
では、csvファイルの作成を行います。ここではあるA_Serverの/data/csvディレクトリに店舗の在庫情報が格納された「stock.csv」を格納するものとしてCSVファイルを定義します。
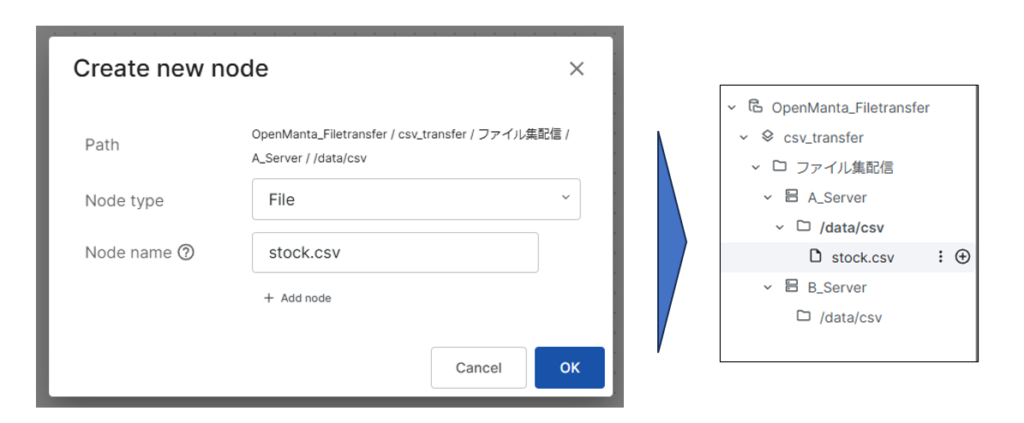
csvファイル内のカラム情報を定義します。今回はSTOCK_DATE(在庫確認日)、QTY(数量)、ITEM_CD(商品コード)、STORE_CD(店舗コード)を定義ます。
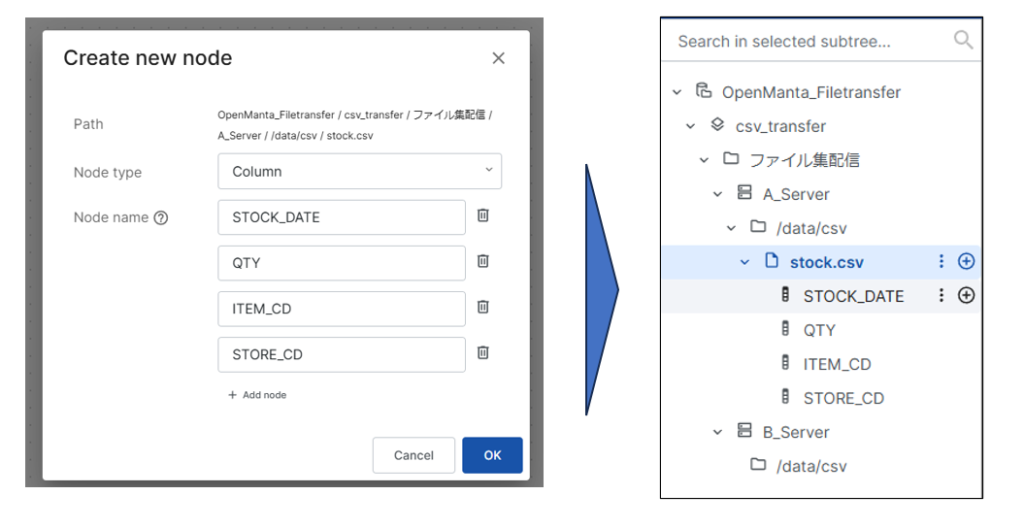
ここまででA_Serverに配置されるCSVファイルとそのカラム情報の作成ができました。
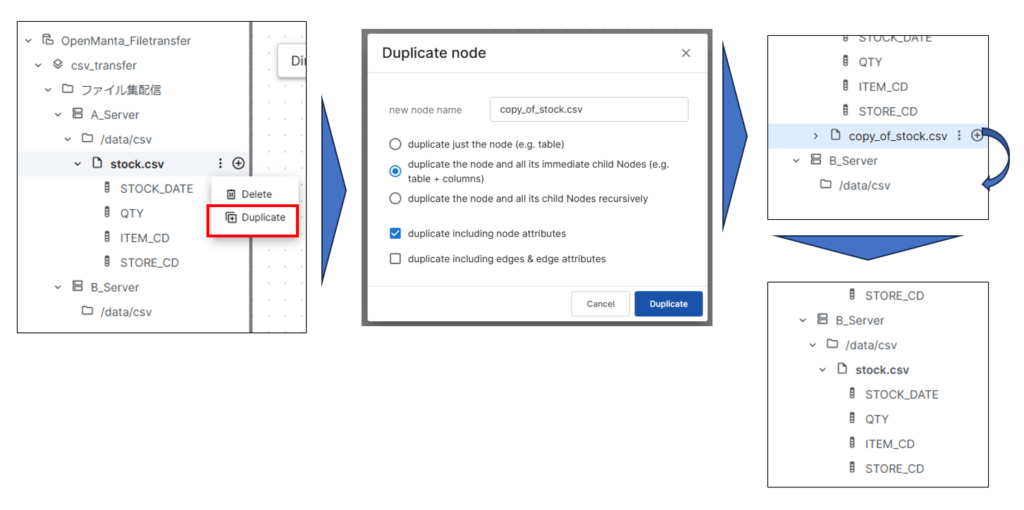
次にB_Serverの設定を行うのですが、ここまでと同じ手順で作成してB_Server分も作成することができますが、今回はA_ServerのCSVをそのままB_Serverに転送する流れを作成するので、A_Serverの設定をコピーしてB_Serverに同じ定義を設定してみます。
先ほど作成したstock.csvから「Duplicate」をクリックしてコピーを作成します。作成されたcopy_of_stock.csvをドラッグ&ドロップでB_Serverの「/data/csv」ディレクトリに移動させ、名前をstock.csvに直します。これでA_Server、B_Serverの定義が完了です。
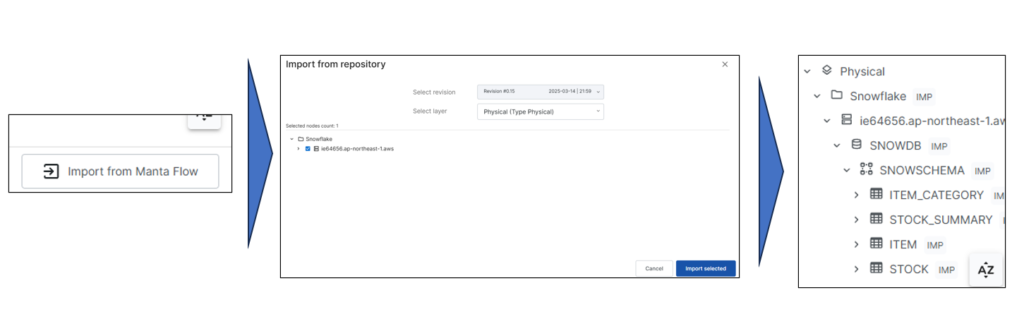
ここからは手動で作成したリソースと別途Mantaのアダプターで定義を取得したSnowflakeのテーブルに対してデータの流れを定義していきます。
「Import from Manta flow」をクリックして取り込みたいバージョン、タイプ、リソースを選択することでOpen Manta Designerにアダプターから取り込んだリネージュ定義をインポートすることができます。
これでリネージュを作成する準備ができたので実際にデータの流れを定義していきます。まず、作成したA_Server、B_Serverのstock.csvと取り込んだSnowflakeのSTOCKテーブルをキャンパスにドラッグ&ドロップします。
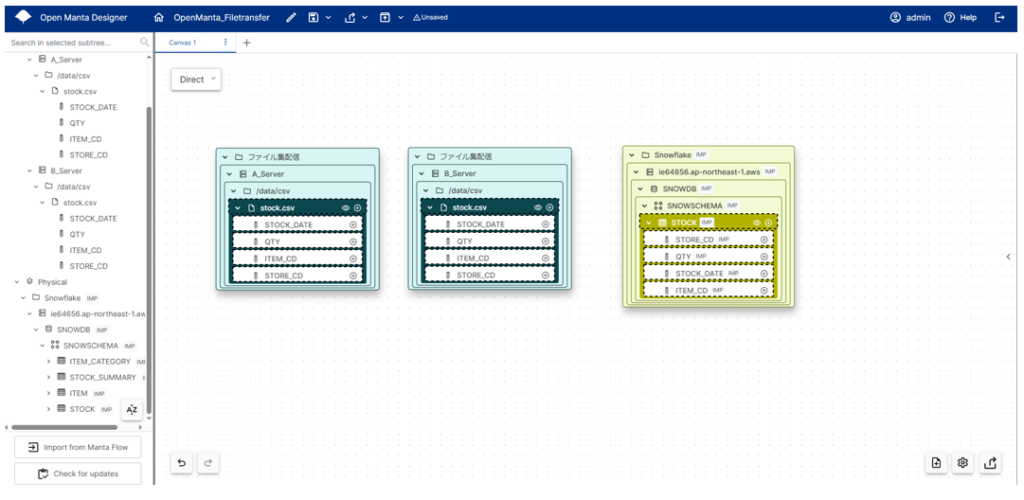
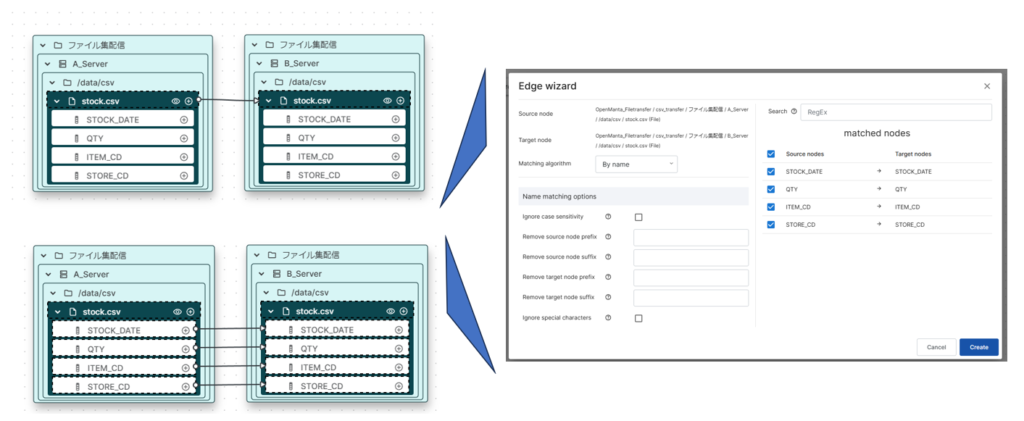
キャンパスの各リソースが表示されたので実際のデータの流れを結んでいきます。今回はA_ServerからB_Serverに単純にデータが転送されるのでA_Serverのstock.csvをB_Serverのstock.csvに線をドラッグ&ドロップで結びます。ファイルやテーブル単位で線を結んだ場合には設定画面が表示され、カラムのマッピングを設定することができます。今回は両csvファイルとも同名のカラムのためカラム名で自動マッピングすることできます。
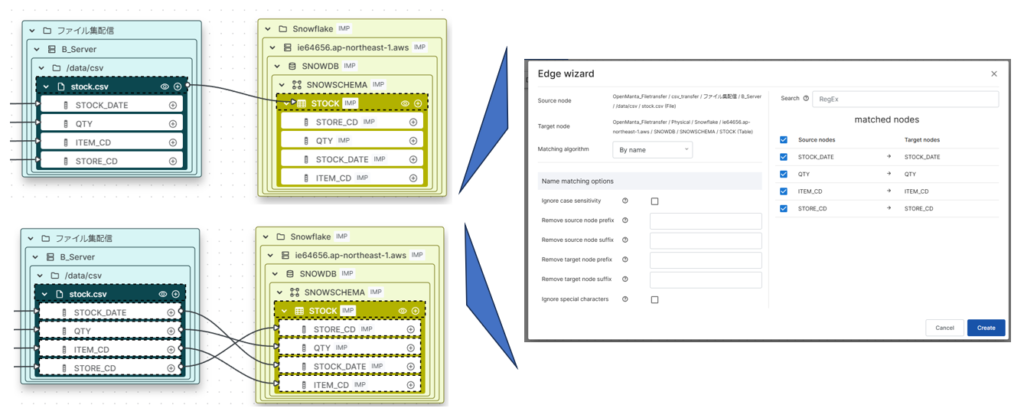
次にB_Serverのstock.csvからSnowflakeのSTOCKテーブルに線を結びます。先ほどのA_Server-B_Serverの時と同様にマッピング設定が画面が表示されるのでカラム名でマッピングします。今回のstock.csvとSTOCKテーブルではカラムの順序が異なりますが順序を考慮して自動マッピングできています。
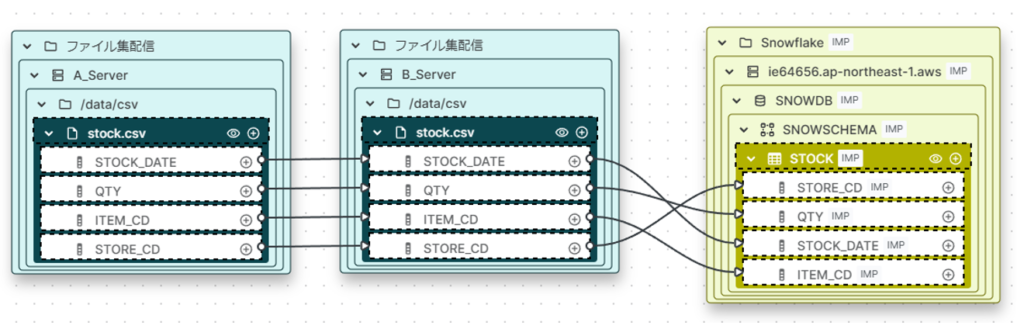
これで一連のCSVファイルをAサーバからBサーバに転送し、Snowflakeにインポートするという流れをOpenMantaで作成することができました。今回はGUIを使用してリネージュを定義しましたが、定義ファイルをインポートしてリネージュを作成することも可能です。
まとめ
今回はOpenMantaを使用して手動でリネージュを作成してみました。この機能を使用することでスキャナーが用意されていないシステムのリネージュを作成でき、スキャナーが用意されているシステムと合わせて全社のシステムのデータリネージュで管理することが出来るようになります。
Mantaについては基本編とユースケース編、そして本編を読んでいただくことでより深くIBM Manta Data Lineageを理解いただけましたら幸いです。