


IBM DataStageの提供形態と次世代型DataStageのご紹介
投稿者:大垣 克行
みなさん、こんにちは!
NI+C DataOpsチームの大垣です。
過去2回にわたりDataStage-aaS Anywhereに関するブログを掲載させて頂きました。
第1回:DataStage-aaS Anywhereを導入してみた
第2回:DataStage-aaS Anywhereでジョブ作成/実行してみた
DataStageは継続的に製品開発が進められており、お客様の利用シーンに合わせるべく様々な提供形態がございます。
また、DataStageは従来型から次世代型へシフトしており、上記のDataStage-aaS Anywhereも次世代型となります。
そこで本ブログでは、DataStageのご紹介や提供形態をご紹介させて知頂き、「そもそも従来型と次世代型の違いは何が違うの?」、「なぜ次世代型にシフトしているの?」と気になる方もいらっしゃると思いますので、以下3点について記載していきたいと思います。
1.DataStagaとは
2.DataStageの提供形態
3.従来型から次世代型DataStageへシフト
是非、最後までお付き合い頂けたら幸いです。
1.DataStageとは
まず、改めてDataStageをご紹介したいと思います。
DataStageはデータ統合時に最も手間のかかる以下の3つのプロセスを簡素化する20年以上の歴史をもつETL (Extract Transform Load) ツールです。
また、DataStageは開発生産性の向上、開発期間・コスト削減を実現し、ビジネスへの迅速な対応を可能にします。
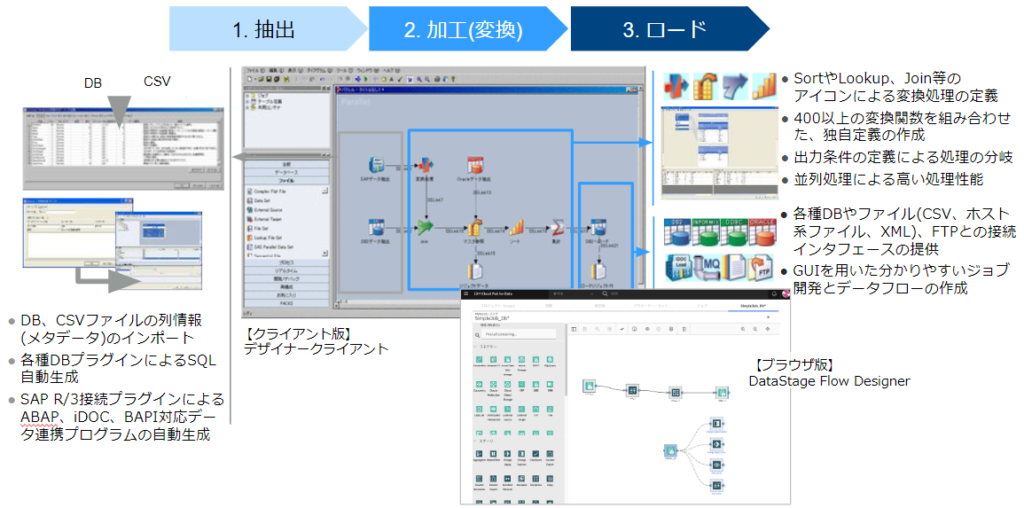
2.DataStageの提供形態
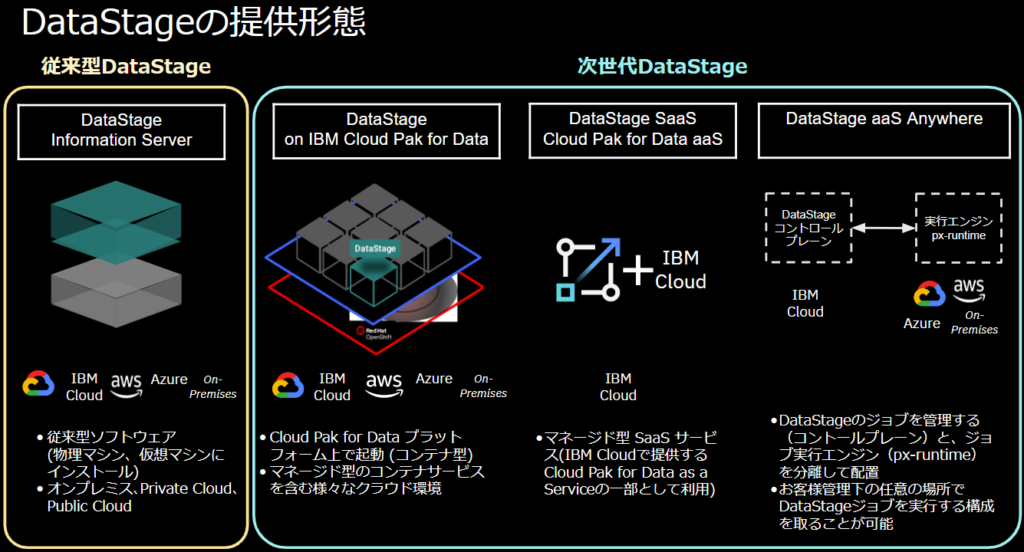
冒頭で少し触れましたが、DataStageは「従来型」と「次世代型」に分かれます。
DataStageは柔軟性と拡張性向上、マイクロサービス化とAI機能の統合を目的に、従来型から次世代版へシフトしております。
従来型
従来型のDataStageは、開発者がデータフローマップを作成し、データの流れと変換プロセスを指定します。
プロジェクトやジョブ管理に専用のクライアントソフトウェアが必要になります。
次世代型
次世代DataStageでは、フローベースの開発環境が提供されています。
プロジェクトやジョブ管理に専用のクライアントソフトウェアは不要であり、Webベースで操作することが可能です。
また、従来型との大きな違いとして、IBM Cloud Pak for Data上でDataStageが稼働します。
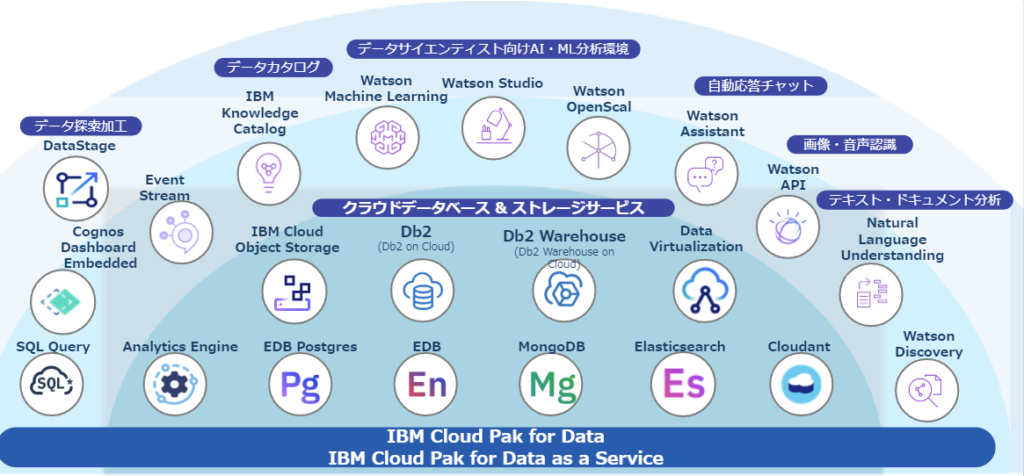
IBM Cloud Pak for Dataでは、DataStageに限らずデータ/AI活用に役立つ機能が提供されています。
参考までにIBM Cloud Pak for Dataが提供する機能は下記画像を参照下さい。
また、次世代DataStageは3つの提供形態があります。
| InfoSphere DataStage | DataStage on Cloud Pak for Data | DataStage on Cloud Pak for Data as a Service | DataStage as a Service Anywhere |
|---|---|---|---|
| 従来型 | 次世代型 | ||
| ソフトウェア版 | SaaS版 | ハイブリッド版 | |
|
|
|
|
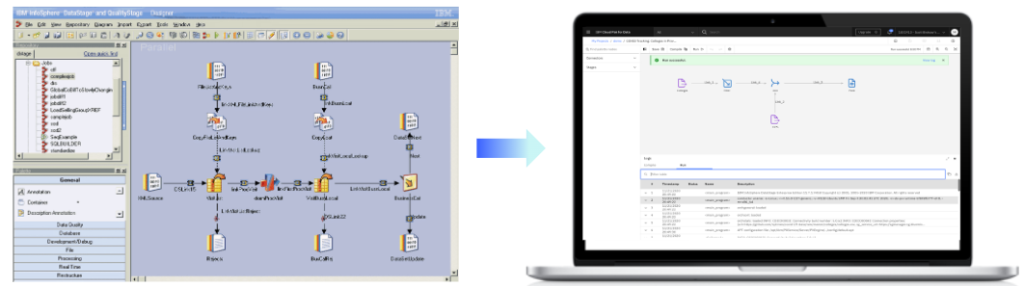
3.従来型から次世代型へのシフト
次世代DataStageの特徴
①新しいWeb開発ツールで
開発者の生産性向上
- 操作性を刷新したGUIツールで、スピーディにデータフローを作成
- 生産性の向上に寄与する機能強化と端末へのクライアントインストールの撤廃
- データフローにすぐ使えるコネクターとステージ
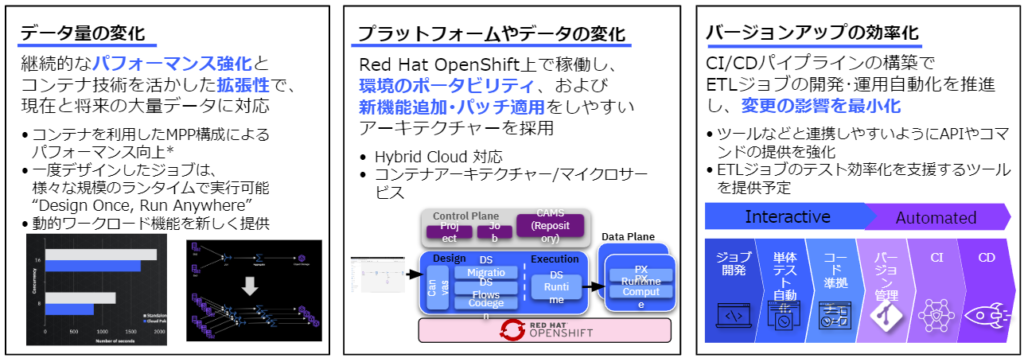
②変化するニーズに迅速に対応
- 予測が難しいデータ量の増加に対応できる拡張性
- 新しいデータソース対応や周辺システムの変化、稼働環境の変更に対応しやすいアーキテクチャーの採用や自動化の推進
③ビジネス価値を見据えた
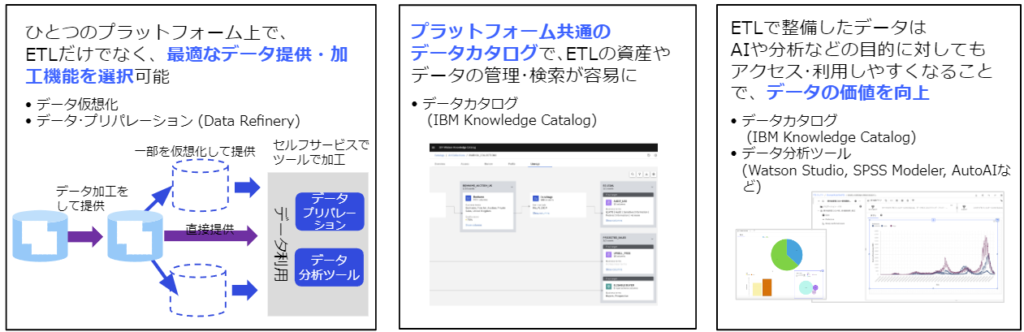
データ整備の拡張
- データ利用者のニーズに対応しやすいプラットフォーム
- DataStageをデータ活用のプラットフォームに統合し、データ整備を徹底的に効率化
最後に
今回はDataStageの提供形態と、次世代型DataStageの特徴をご紹介させて頂きましたが、どのような時にどのDataStageが適しているのかを纏めてみました。
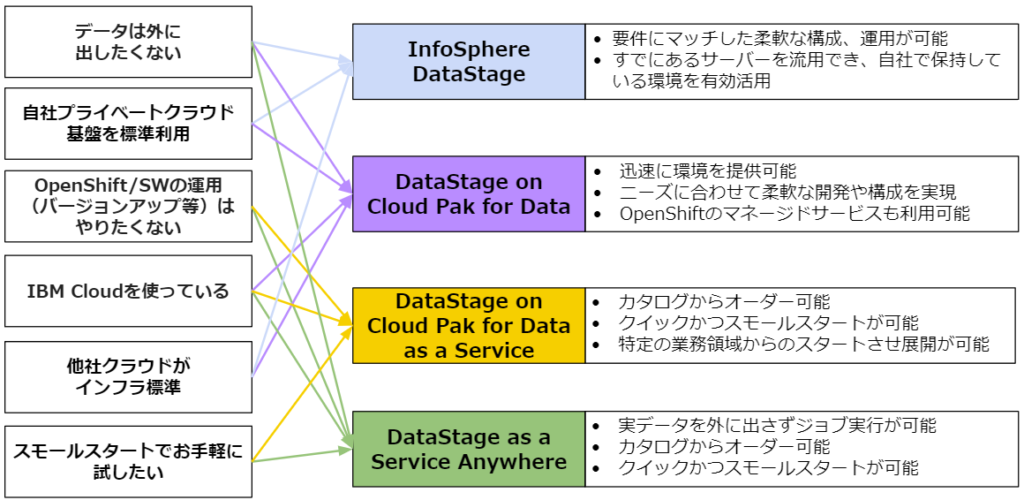
ETL処理が必要なシーンはお客様毎に異なり多岐にわたります。
それに世の中には様々なETLツールが存在し、それぞれに特徴があるとは思いますが、
DataStageはデータセキュリティ、プラットフォーム、スモールスタートなど、お客様のご要件に合わせた最適な環境を選択し、データ加工処理を実現するETLツールであると感じました。
是非、ETLツールをご検討頂く際は本Blogを参考に頂けたら幸いです。
最後までご覧頂き、ありがとうございました。