


生成AI(RAG)の利活用、うまくいってますか?RAG精度向上のポイントを4点まとめてみた。(後編)
投稿者:watsonx.data担当
NI+CのIBM watsonx.data担当の田原です。
RAG精度向上のポイントご紹介の記事の続編です。
まず、おさらいとなります。
前回の記事では、RAGの精度を向上させるポイントを4つご紹介させていただきました。前回はその中の1つである
『チャンキング』についてご紹介させていただきました。
今回は、残りの3つのテーマについてご紹介します。
もくじ
- 精度向上ポイント② ハイブリッド検索
- 精度向上ポイント③ リランキング
- 精度向上ポイント④ メタデータフィルタリング
- まとめ
精度向上ポイント② ハイブリッド検索
RAGの精度向上を考えるにあたり、質問内容と関連性の高い情報を迅速かつ正確に取得することが重要です。
そこで活躍するのが「ハイブリッド検索」となります。
ハイブリッド検索とは、「キーワード検索」と「ベクトル検索」を組み合わせた検索手法です。
キーワード検索はユーザーの入力したキーワードに基づくシンプルな方法ですが、ベクトル検索は質問内容の意味を考慮し、意味的に類似した文章を検索します。
ハイブリッド検索は、これら二つの手法を併用し、それぞれの長所を生かして最も関連性の高い情報を回答します。
例えば、キーワード検索だけでは拾うことができないニュアンスや類似の表現もベクトル検索を併用することで補完することができます。この組み合わせにより、RAGの検索精度を大幅に向上させることが可能となります。
以下、「白い犬」の画像を生成する処理の例となります。
キーワード検索では、検索時に「白い犬」というキーワードに対し、「犬」という文字列が含まれる「柴犬.jpg」を
ベクトルDBから検索・参照し、出力を生成してしまいます。
しかし、ベクトル検索では「白い犬」と類似した内容を持つ画像「スピッツ.jpg」をベクトルDBから検索できた
ため、生成AIは白い犬の画像を出力できます。
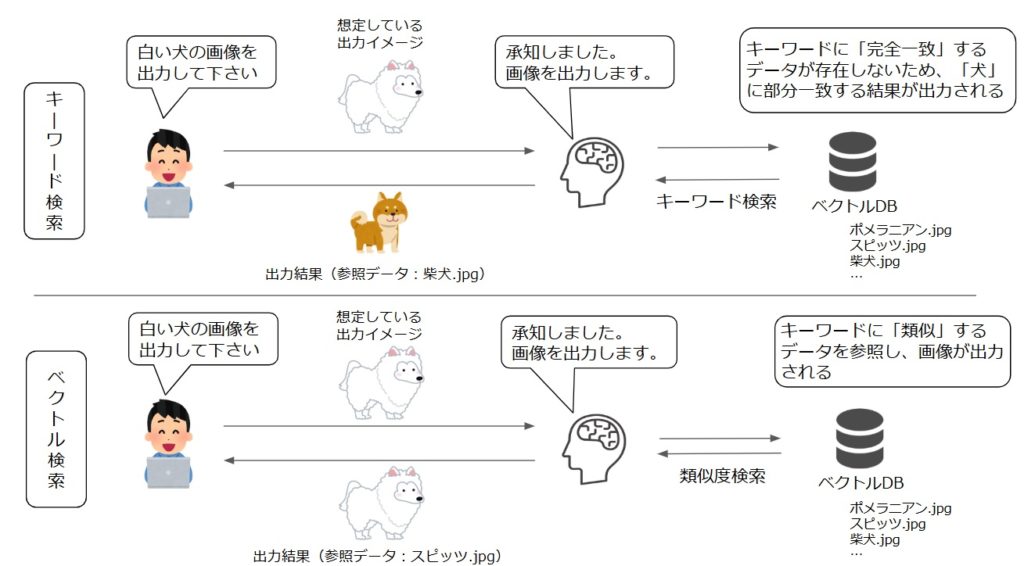
図1
ポイント③ リランキング
次にご紹介するポイントは「リランキング」です。
リランキングとは、リランキングモデルを用いて検索結果を再評価し、より類似度の高い回答結果を取得する手法となります。
生成AIは、設定パラメータに応じて初めに複数の回答候補を用意し、その中から適切なものを選択して回答します。しかし、その際に必ずしも質問に対する最良の順で回答候補を用意できているわけではありません。
このため、同じ質問に対しても回答内容の正確性に差が生じることがあります。
この状況を改善するためにリランキングを行います。リランキングは、検索結果に含まれる各ページやドキュメントの関連性を再評価し、質問内容に対する回答として最も適切なものを回答候補の上位に配置します。
リランキングを行うことで、単にキーワードが含まれているだけの回答よりも、質問内容に対してもっとも充実した情報を含む回答をユーザーに提供することができるため、生成される回答の正確性が向上します。
以下の図を例に挙げると、リランキング処理の実装前では「犬の健康に必要な資料を挙げてください。」という質問に対して「犬の品種図鑑」を回答してしまう可能性が高くなります。
そこで、リランキング処理を実装することによって生成AIは「犬の食事 ヘルシーレシピ」を優先的に回答するようになります。
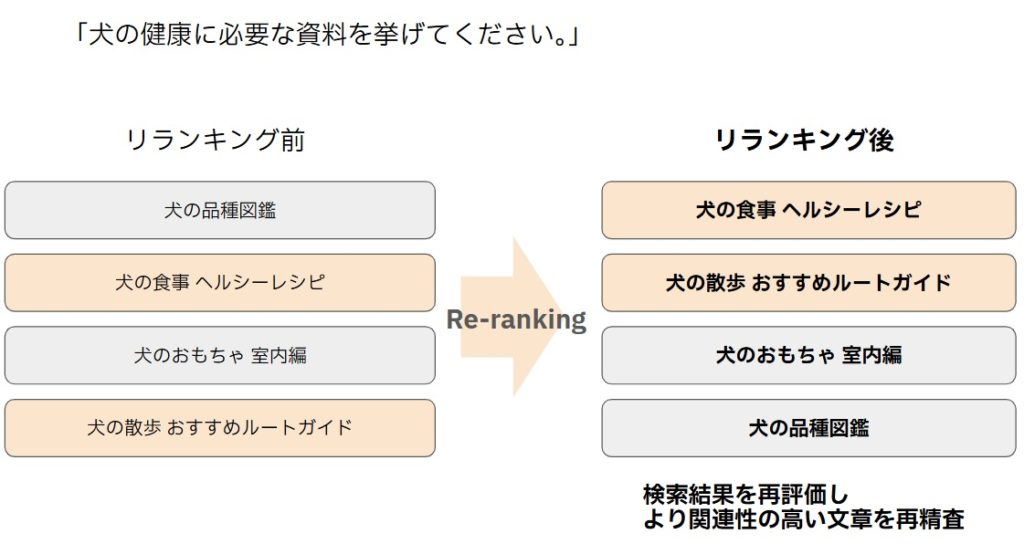
図2
ポイント④ メタデータフィルタリング
最後に「メタデータフィルタリング」についてご紹介します。メタデータフィルタリングとは、データの属性情報を利用して、関連性の低いデータを除外する手法です。
ドキュメントには日付や作成者、カテゴリなどのメタデータが含まれていることが多いです。これらのメタデータを利用して、検索対象データを絞り込むことができます。
例えば、最新の情報が重要な場合は最近の日付のデータに限定したり、特定のカテゴリに属する情報だけを対象とすることで、生成AIが扱うデータの質を向上させることができます。
メタデータフィルタリングを通じて、対象データの精度をさらに高め、生成される回答がユーザーの期待に沿ったものとなるようにすることができます。
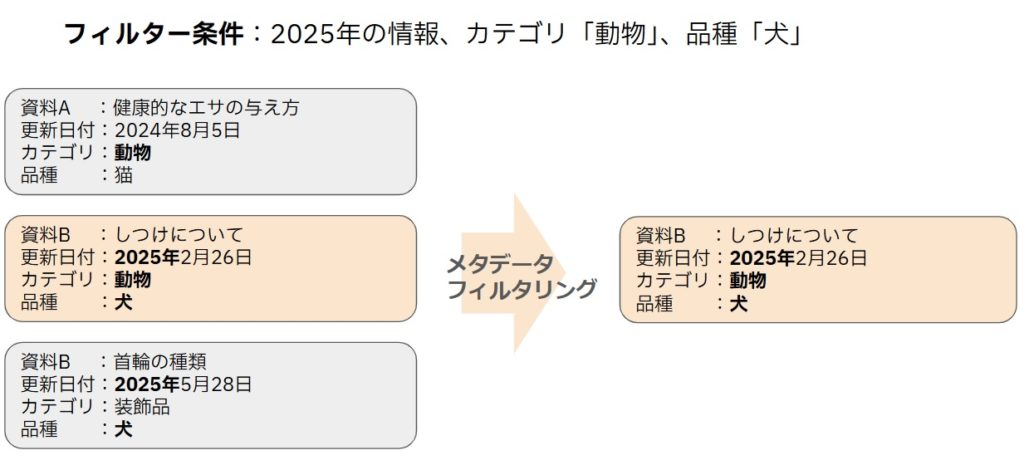
図3
まとめ
いかがでしたでしょうか。以上がRAGの精度向上における残りの3つの手法「ハイブリッド検索」、「リランキング」、「メタデータフィルタリング」でした。
以前の記事で紹介させていただいた「チャンキング」も含め、計4点の手法を組み合わせて利用することで、生成AIの回答精度を大幅に向上させることが期待できます。
本ブログを作成するにあたって作成した検証環境では、チューニング前の回答精度が60%程でしたが、上記4点の
チューニングを加えることで85%程に向上できました。
(ただし、資料の内容や資料の数、使用するLLM等、様々な要因で結果は大きく変化するため、あくまでご参考値としてお読みください。)
RAGを利用する際には、どのようなデータをベクトルDBに格納し、どのように検索するかを検討し、その用途に応じて最適な手法を選ぶことが重要です。
文末ではございますが、このブログがRAGを利活用する、またはこれから活用する予定の皆様がチューニングの最適解を見つけるための一助となれば幸いです。