


Treasure Data CDP<第26弾>AssumeRoleを使ってTreasure Data CDPとAmazon S3を連携してみた(後編)
投稿者:岡田

NI+C マーケソリューションチームです:)
本Tech Blogでは、NI+Cで取り扱っているTreasure Data CDPを紹介していきます。
本ブログは前編・後編の2部構成になっています。
本日は後編として、Treasure Data CDPからAmazon S3にAssumeRoleを使ったインプット、アウトプットについて解説します。
「Treasure Data CDP<第25弾>AssumeRoleを使ってTreasure Data CDPとAmazon S3を連携してみた!(前編)」こちらも併せてお読みいただくと、さらに理解が深まると思いますので、ぜひご覧ください。
アジェンダ
- はじめに(前編のおさらい)
- AssumeRoleを使ったAmazon S3からTreasure Data CDPへのデータインプット(取り込み)
- AssumeRoleを使ったTreasure Data CDPからAmazon S3へのデータアウトプット(出力)
- まとめ
1.はじめに(前編のおさらい)
前編の記事では、Treasure Data CDPとAmazon S3を連携するための最もセキュアな認証方法である「AssumeRole」の仕組みと、その初期設定について解説しました。
具体的には、Treasure Data CDP側で「Amazon S3 v2」コネクターを選択し、「assume_role」方式のAuthenticationを作成しました。さらにAWS側では、Treasure DataのアカウントIDとExternal IDを用いて、IAMロール(例:assume_role_blog)を作成しています。
※補足:権限設定について
Amazon S3からのインプットに必要な s3:GetObject と s3:ListBucket、Amazon S3へのアウトプットに必要な s3:PutObject と s3:AbortMultipartUpload を含めた許可ポリシー(S3_Policy)は、このIAMロールに既に付与済みです。
前編で既に「assume_role_blog」というAuthenticationを作成していますので、今回の後編ではそちらを使用して、実際にデータのインプットやアウトプットを行っていきましょう!
2.AssumeRoleを使ったAmazon S3からTreasure Data CDPへのデータインプット(取り込み)
Amazon S3とTreasure Dataの間でデータのインプット/アウトプットを行うのは、社内の各システムから出力された業務データやWebのアクセスログなどを、データレイクであるAmazon S3を経由してTreasure Dataに統合・蓄積するといったシーンでよく利用されます。
それでは、実際にインプットの設定を進めていきましょう!
【Amazon S3側の設定】
①前編にて「IAMロール」を付与したAWSアカウントでログインし、Amazon S3上にバケットを作成

今回は「assumerole-blog」という名前のバケットを作成しています。
(※バケットとはデータを保管するための入れ物【コンテナ】のようなものです)
② 上の①で作成したバケットの中に今回取り込みたいファイルをアップロード

今回は「customer_list202603.tsv」という顧客情報が記載されたファイルをアップロードしています。
▼ customer_list202603.tsvの中身 ▼
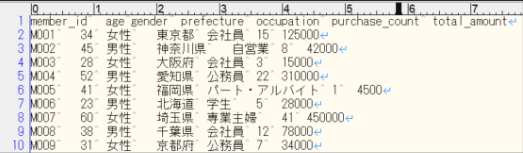
以上でAmazon S3へのファイル配置は完了です。
それでは、この配置したファイルをAssumeRoleを使ってTreasure Data CDPに取り込んでみましょう!
【Treasure Data CDP側の設定】
①まずは前編で作成したAuthentication(assume_role_blog)の「New Source」を選択
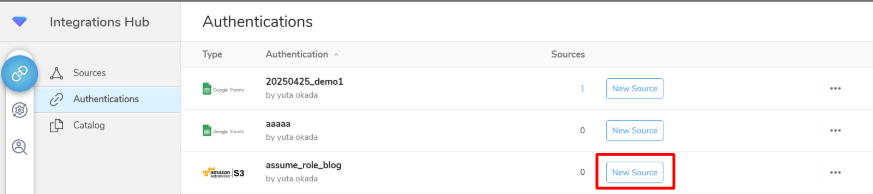
②6段階の設定画面が出てくるので、順々に設定
■ Step 1: Connection(コネクションの設定)

・Data Transfer Name:このデータ転送処理(ジョブ)の名前を任意で入力します。今回「customer_list202603」と設定しました。
・Authentication:前編で作成した認証情報を選択します。プルダウンから「assume_role_blog」を指定します。
■ Step 2: Source Table(取得元データの設定)
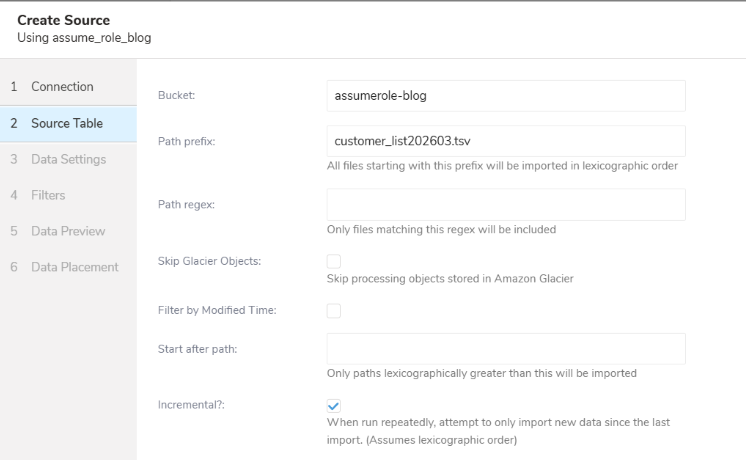
続いて、Amazon S3上のどのファイルを取り込むかを指定します。
・Bucket:データを取得するAmazon S3のバケット名を入力します。今回は先ほどAmazon S3側で作成した「assumerole-blog」を指定しています。
・Path prefix:取得したいファイルのプレフィックス(パスやファイル名)を指定します。今回は「customer_list202603.tsv」という特定のファイルを指定しています。
・Incremental?:定期的にデータをインポートする場合に、前回から新しく追加されたデータのみを取り込む(差分取り込み)かどうかの設定です。今回はチェックを入れて有効にしています。
※その他の項目(Path regexやSkip Glacier Objectsなど)については、今回は空白・チェックなしのままで進めます。
■ Step 3: Data Settings(データ形式とスキーマの設定)
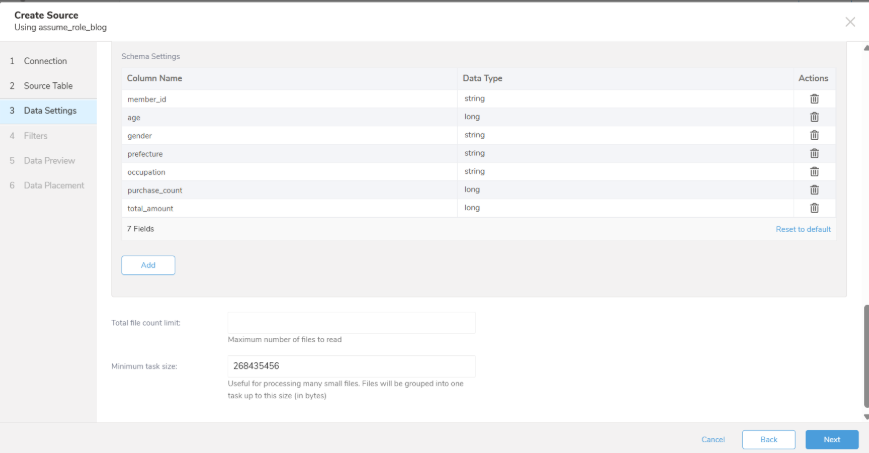
取得するファイルの中身(カラム名やデータ型)が正しく認識されているかを確認・設定する画面です。
・Schema Settings:
読み込んだデータの各列に対して、カラム名(Column Name)とデータ型(Data Type)が一覧で表示されます。画像のように「member_id」や「gender」には文字列の「string」が、「age」や「total_amount」などの数値には「long」が割り当てられていることを確認します。もし自動判定されたデータ型が意図と異なる場合は、この画面で手動で変更・追加することができます。
※画面下部の「Total file count limit」や「Minimum task size」などの詳細な設定項目は、今回はデフォルトのままで進めます。
■ Step 4: Filters(データのフィルタリング設定)

取り込むデータに対して、特定の条件で事前の絞り込み(フィルタリング)を行う画面です。
例えば「年齢(age)が20歳以上のデータだけを取り込む」といった細かな指定が可能ですが、今回はS3上のファイルデータをそのまま全件取り込みます。
そのため、ここでは何も設定(Add Filter)を追加せず、「No filters applied」の状態のまま右下の「Next」を押して次に進みましょう。
■ Step 5: Data Preview(データのプレビュー確認)

ここまでの設定で、実際にS3のデータがどのようにTreasure Dataへ読み込まれるかを事前確認(プレビュー)できる画面です。
・赤枠で囲っている「Generate Preview」ボタンをクリックすると、S3のデータの一部がサンプルとして取得・表示されます。
・先ほどのStep 3で設定したカラム名に対して、データがズレたり文字化けしたりせずに綺麗に並んでいればOKです!
■ Step 6: Data Placement(データの保存先とスケジュールの設定)

いよいよ最後のステップです!Treasure Dataのどこにデータを保存するか(STORAGE)と、取り込み処理のスケジュール(SCHEDULE)を設定します。
<STORAGE(保存先)の設定>
・Database:データの保存先となるデータベースを選択します。今回は「assume_role_blog」を指定しています。
・Table:既存のテーブルに入れるか、新しく作るかを選びます。今回は「Create New Table」を選択します。
・Table Name:新しく作成するテーブル名を入力します。今回は「customer_list202603」としています。
・Method:データの書き込み方式です。今回は既存のデータに追記していく「Append」を選択しています(※毎回全件洗い替えしたい場合は「Always Replace」などを選びます)。
<SCHEDULE(スケジュール)の設定>
・Repeat:自動で定期実行させるかどうかの設定です。今回は手動で1回だけテスト実行するため「Off」のままにしておきます。
③データが取り込まれているか確認
Treasure Data CDPのクエリ画面から、上の②で作成した「assume_role_blog.customer_list202603」テーブルにレコードが正しく入っているかを確認します。

実際にクエリを実行してみた結果、無事に100レコードが抽出され、Amazon S3からTreasure Data CDPへのデータインプットが成功したことを確認できました!
インプットの手順が完了したところで、続いては逆の動きとなる「データのアウトプット(出力)」について解説していきます。Treasure Data CDPに蓄積されたデータを、今度はAmazon S3へ書き出してみましょう!
3.AssumeRoleを使ったTreasure Data CDPからAmazon S3へのデータアウトプット(出力)
インプットが外部データをTreasure Data CDPに集約する目的だったのに対し、データのアウトプットは、Treasure Data CDP内で分析・抽出したデータを外部で活用する際に利用されます。
例えば、抽出した優良顧客リストなどのセグメントデータを、外部のMAツール等へ連携するための経由地としてAmazon S3に書き出したり、加工済みのデータをバックアップ目的で長期保管したりするケースが代表的です。
それでは、実際にアウトプットの設定を進めていきましょう!
【Amazon S3側の設定】
①Amazon S3上のバケットの中にアウトプット先のファイルをアップロード

今回はインプットの時に使用したAmazon S3上のバケット(assumerole-blog)の中に「output_sheet.txt」というファイルを用意しています。(※本来はTreasure Data側で自動生成されるため事前の空ファイル作成は必須ではありませんが、今回は出力先のプレースホルダーとしてあらかじめ用意しました)
【Treasure Data CDP側の設定】
Treasure Data CDPからAmazon S3へのデータアウトプット方法はいくつかありますが、今回は最も手軽な「クエリによるアウトプット」をご紹介します。
①Treasure Data CDPのクエリ画面の「Export Results」にチェック

右上のチェックボックスをクリックします。

ポップアップが開くので、今回何度も使用している「assume_role_blog」というAuthenticationを選択します。
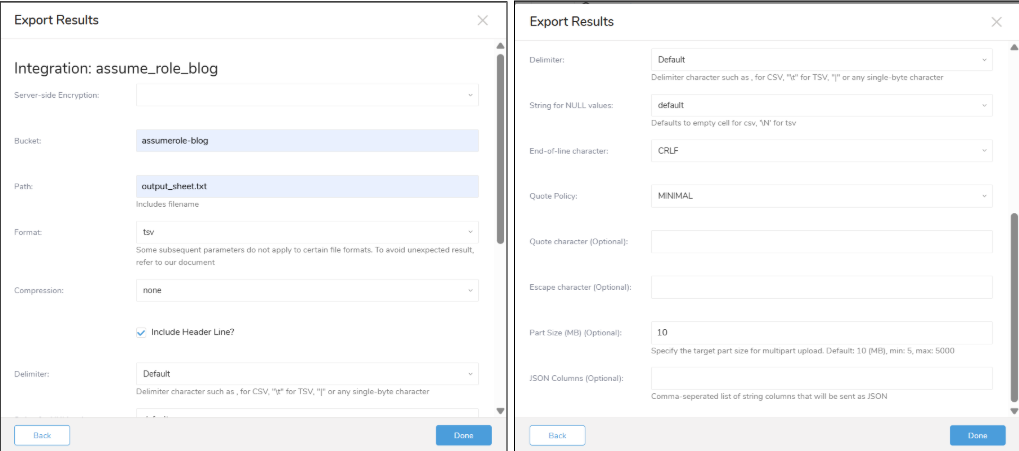
設定項目がたくさんありますが、基本的には以下の必須項目とファイルの出力形式を設定すればOKです!
~主な設定項目の説明~
・Bucket:アウトプット先のS3バケット名を入力します。今回は作成した「assumerole-blog」を指定します。
・Path:S3に出力する際のファイルパス(ファイル名を含む)です。今回は「output_sheet.txt」としています。
・Format:出力するファイルの形式です。今回は「tsv」(タブ区切り)を選択します。
・Compression:出力ファイルの圧縮形式です。今回は圧縮なしの「none」としています。
・Include Header Line?:出力されるファイルの1行目にカラム名(ヘッダー)を含めるかどうかの設定です。今回はチェックを入れます。
※その他の詳細設定について
Delimiter(区切り文字)や End-of-line character(改行コード)、Part Sizeなどの細かいオプション項目がありますが、今回はすべて「デフォルトのまま」で進めて問題ありません。実務で特殊なデータ形式を扱う場合のみ、必要に応じて変更してください。
②「Export Results」にチェックがついた状態でクエリを実行
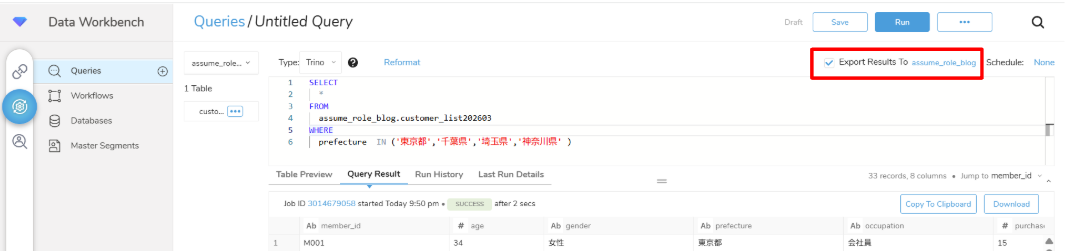
今回は、住所が”東京都”、”千葉県”、”埼玉県”、”神奈川県”の人だけをピックアップすようなクエリを実行しています。
③Amazon S3上のバケットに配置したファイルの中身を確認
それでは、S3の管理画面から対象のファイルを開いて(またはダウンロードして)中身を見てみましょう。

実際に確認してみると、先ほどまで空だったファイルにTreasure Dataのクエリ結果がしっかりと出力されていました。これで、無事にデータのアウトプットが成功したことを確認できました!
インプット設定と合わせて、これでAssumeRoleを利用した双方向のセキュアなデータ連携ができるようになりました。
4.まとめ
以上、「AssumeRoleを使ってTreasure Data CDPとAmazon S3を連携してみた!」を前編・後編にわたってお届けしました。
Treasure Data CDPとAmazon S3の認証方法にはいくつか種類がありますが、セキュリティの高さは assume_role > session > basic > anonymous の順となっており、今回ご紹介した「AssumeRole」が最もセキュアで推奨される方法です。
必要なタイミングで一時的な権限(トークンなど)を付与し、有効期限が切れると自動的に無効化されるため、常時使用可能なアクセス権限を持たせない「最小権限の原則」によって、不正利用や情報漏洩などのセキュリティリスクを大きく軽減することができます。
設定が少し難しそうに思われるかもしれませんが、一度手順を覚えてしまえば非常に簡単に設定することが可能です。セキュリティを意識したデータ連携の運用には、ぜひ「assume_role」をお試しください!
Treasure Data CDPにご興味を持たれた方はぜひ「こちら」からお問い合わせください
その他、Treasure Data CDP についての記事はこちら↓
セグメント作成について↓↓
Treasure Data CDP <第1弾>Audience Studio の機能でセグメント作成してみた!!
Activationについて↓↓
Treasure Data CDP <第2弾>Audience Studio の機能 Activation を使ってみた!
Predictive Scoring について↓↓
Treasure Data CDP <第3弾>Predictive Scoring のご紹介
データのインポートについて↓↓
Treasure Data CDP <第4弾>Treasure Data にデータをインポートしてみた
SQLを使ったデータの抽出方法について↓↓
Treasure Data CDP<第5弾>SQL を使ってデータ抽出してみた!
Treasure Workflowについて(前編)↓↓
Treasure Data CDP<第6弾>Treasure Workflow とは(前編)
Treasure Workflowについて(後編)↓↓
Treasure Data CDP<第7弾>Treasure Workflow とは(後編)
新機能 ジャーニーオーケストレーションについて↓↓
Treasure Data CDP<第8弾>新機能 ジャーニーオーケストレーション ご紹介
Server Side 1st Party Cookieについて↓↓
Treasure Data CDP<第9弾>Server Side 1st Party Cookieのご紹介
ジャーニーオーケストレーションの機能を使ったジャーニーの作成方法について↓↓
Treasure Data CDP<第10弾>【Journey Ohchestration】ジャーニーを作成してみよう!
Predictive Scoring 予測モデルの作成から実行について↓↓
Treasure Data CDP<第11弾>Predictive Scoringを使ってみた!
Policy Based Permissionについて↓↓
Treasure Data CDP<第12弾>Policy Based Permissionとは?
Treasure Insights について↓↓
Treasure Data CDP<第13弾>Treasure Insights について ご紹介
ID Unificationについて↓↓
Treasure Data CDP<第14弾>ID Unification 機能 ご紹介
アップデートされたAudience Studioについて↓↓
Treasure Data CDP<第15弾>アップデートされたAudience Studioのご紹介!
Utilizationについて↓↓
Treasure Data CDP<第16弾>Utilizationについてご紹介
TD AutoMLについて↓↓
Treasure Data CDP<第17弾>TD AutoMLを動かしてみた!
Policy based Column-level Access Controlについて↓↓
Treasure Data CDP<第18弾>セキュリティ強化機能~カラムレベルでデータを管理してみた!~
Treasure Dataの日時を扱う独自関数について↓↓
Treasure Data CDP<第20弾>Treasure Dataの日時を扱う独自関数をご紹介!
銀行業界でのユースケースについて↓↓
Treasure Data CDP<第21弾>Treasure Dataによる銀行業界でのユースケース【動画】
Googleスプレッドシートとの連携について(前編)↓↓
Treasure Data CDP<第22弾>Treasure Data CDPとGoogle スプレッドシートを連携してみた!(前編)
ジャーニーオーケストレーションのシナリオについて↓↓
Treasure Data CDP<第23弾>ジャーニーオーケストレーションのシナリオをご紹介!
Googleスプレッドシートとの連携について(後編)↓↓
Treasure Data CDP<第24弾>Treasure Data CDPとGoogle スプレッドシートを連携してみた!(後編)
AssumeRoleを使ったAmazon S3との連携について(前編)↓↓
Treasure Data CDP<第25弾>AssumeRoleを使ってTreasure Data CDPとAmazon S3を連携してみた!(前編)